主要内容
nnmf
非负矩阵分解
描述
例子
非负秩二近似和双图
加载示例数据。
负载fisheriris
计算费雪虹膜数据中四个变量测量值的非负二阶近似。
rng(1)%为了再现性[W,H]=nnmf(meas,2);H
H=2×40.6945 0.2856 0.6220 0.2218 0.8020 0.5683 0.1834 0.0149
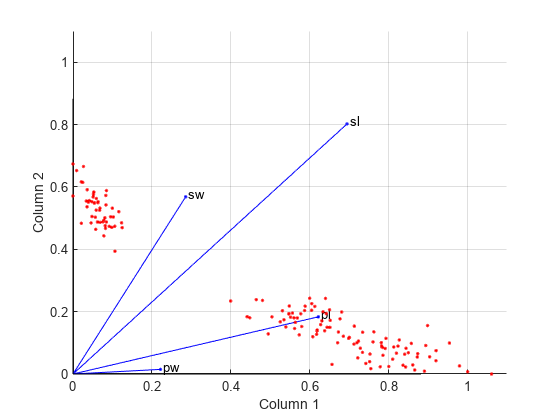
第一个和第三个变量量(萼片长度和花瓣长度,系数分别为0.6945和0.6220)为第一列花瓣提供了相对较强的权重W.中的第一个和第二个变量量(萼片长度和萼片宽度,系数分别为0.8020和0.5683)为第二列提供了相对较强的权重W.
创建一个biplot中的数据和变量量在的列空间中W.
biplot (H ',“分数”W,“VarLabels”,{“sl”,“西南”,“pl”,“pw”});xlabel([0 1.1 0 1.1])第一列的)伊拉贝尔(第2列的)
变换算法
从随机数组开始X对于第20位,尝试使用乘法算法在多个重复中进行几次迭代。
rng违约%为了再现性X=兰特(100,20)*兰特(20,50);opt=statset(“MaxIter”5.“显示”,“决赛”);[W0,H0]=nnmf(X,5,“复制品”,10,...“选项”选择,...“算法”,“骡子”);
代表迭代rms渣油δx | 1 | 5 0.560887 0.66418 - 0.0364471 0.0245182 - 2 5 3 5 0.619291 - 0.0455135 0.608894 - 0.0415491 0.609125 0.0358355 - 4 5 5 5 6 5 0.621549 - 0.0299965 7 5 0.640549 - 0.0438758 8 5 0.633526 - 0.0319591 0.673015 - 0.0366856 9 5 0.606835 - 0.0318931 10 5最后均方根剩余= 0.560887
使用交替最小二乘法从这些最好的结果中继续进行更多的迭代。
opt=statset(“麦克斯特”,1000,“显示”,“决赛”);[W,H]=nnmf(X,5,“W0”W0,“H0”H0,...“选项”选择,...“算法”,“als”);
rep迭代rms残差|delta x| 1 24 0.257336 0.00271859最终均方根残差= 0.257336
输入参数
输出参数
参考文献
[1] 贝瑞、迈克尔W、莫里·布朗、艾米·N·兰维尔、V·保罗·鲍卡和罗伯特·J·普莱蒙斯,“近似非负矩阵分解的算法和应用。”计算统计与数据分析52岁的没有。1(2007年9月):155-73。https://doi.org/10.1016/j.csda.2006.11.006.
扩展能力
介绍了R2008a
你也可以从以下列表中选择一个网站:
