逐步执行文本分类
这个例子展示了如何逐步训练模型分类文档文件中基于词频率;一个bag-of-words模型。
加载NLP的数据集,其中包含单词频率的稀疏矩阵X计算从MathWorks®文档。标签Y工具箱的文档页面所属。
负载nlpdata
更多细节的数据集,如词典和语料库,回车描述。
观测排列的标签。因为增量学习软件不开始计算性能指标,直到它处理所有标签至少一次,洗牌的数据集。
(氮、磷)大小(X) =
n = 31572
p = 34023
rng (1);shflidx = randperm (n);X = X (shflidx:);Y = Y (shflidx);
确定数据的类的数量。
猫=类别(Y);maxNumClasses =元素个数(猫);
创建一个朴素贝叶斯增量学习。指定类的数量、度量预热段0和指标窗口大小为1000。因为预测 词的频率 在字典中,指定的预测是有条件的,共同多项式,考虑到类。
Mdl = incrementalClassificationNaiveBayes (MaxNumClasses = MaxNumClasses,…MetricsWarmupPeriod = 0, MetricsWindowSize = 1000, DistributionNames =“锰”);
Mdl是一个incrementalClassificationNaiveBayes对象。Mdl是一个冷模型,因为它没有处理观察;它代表了一个模板进行训练。
测量模型的性能和适应增量式模型通过使用训练数据updateMetricsAndFit函数。模拟数据流处理的1000块一次观察。在每一次迭代:
1000年的观察过程。
覆盖前面的增量式模型与一个新安装的观察。
将当前的最小存储成本。
这个阶段可能需要几分钟。
numObsPerChunk = 1000;nchunks =地板(n / numObsPerChunk);(nchunks mc = array2table (0, 2),“VariableNames”,(“累积”“窗口”]);为j = 1: nchunks ibegin = min (n, numObsPerChunk * (j - 1) + 1);iend = min (n, numObsPerChunk * j);idx = ibegin: iend;XChunk =全(X (idx:));Mdl = updateMetricsAndFit (Mdl XChunk Y (idx));mc {j:} = Mdl.Metrics {“MinimalCost”,:};结束
Mdl是一个incrementalClassificationNaiveBayes模型对象培训中的所有数据流。在增量学习模型是热身之后,updateMetricsAndFit检查传入的块的性能模型的观测,然后符合观测模型。
情节的最小成本,看看它发展在训练。
图绘制(mc.Variables) ylabel (“最小成本”传奇(mc.Properties.VariableNames)包含(“迭代”)
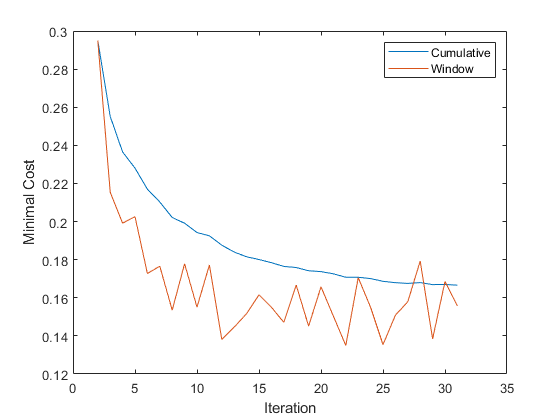
累计最小平稳降低成本和解决在0.16附近,而最小的成本计算块跳跃在0.14和0.18之间。