 克里夫的角落:克里夫硅藻土在数学和计算
克里夫的角落:克里夫硅藻土在数学和计算 MATLAB的博客
MATLAB的博客 史蒂夫与MATLAB图像处理
史蒂夫与MATLAB图像处理 人在仿真软件金宝app
人在仿真软件金宝app 人工智能
人工智能 开发区域
开发区域 斯图尔特的MATLAB视频
斯图尔特的MATLAB视频 在标题后面
在标题后面 文件交换的选择
文件交换的选择 汉斯在物联网
汉斯在物联网 学生休息室
学生休息室 MATLAB社区
MATLAB社区 MATLABユーザーコミュニティー
MATLABユーザーコミュニティー 创业、加速器,和企业家
创业、加速器,和企业家 自治系统
自治系统潜在语义索引、圣言,Zipf定律
潜在语义索引、大规模集成电路,采用奇异值分解的term-by-document矩阵来表示文档中的信息的方式促进回应查询和其他信息检索任务。我自己开始学习如何实现大规模集成电路。我发现比我想象的要难。
内容
背景
潜在语义索引是在1990年第一次描述了苏珊•杜和几个同事在贝尔的后代著名“并。贝尔实验室。(杜现在微软研究院)。我第一次听到LSI几年后从田纳西州大学的迈克·贝瑞。巴里,杜和加文·奥布莱恩纸,“使用线性代数智能信息检索”暹罗审查在1995年。这里是一个链接预印的纸。
信息检索的一个重要问题是同义词。不同的单词可以引用相同或非常相似,主题。如何检索相关文档,实际上并没有使用一个关键字查询?例如,考虑这些条件
- FFT(快速傅里叶变换有限)
- 圣言(奇异值分解)
- ODE(常微分方程)
有人寻找信息PCA(主成分分析)将文档更感兴趣关于圣言会比其他两个主题。可以发现这种联系,因为文档对PCA和圣言会更容易分享“排名”和“子”不存在于他人。用于信息检索目的,PCA和圣言是同义词。潜在语义索引可以揭示这种联系。
字符串
我将使用新的字符串对象,介绍了MATLAB的最新版本。双引号是MATLAB中的非法字符。但现在它要表达的字符串。
s =“%让一个4×4的美元从杜勒的_Melancholia_幻方。”
s =“%让一个4×4的美元从杜勒的_Melancholia_幻方。”
消除主要百分号和美元之间的乳胶的迹象。
s =擦掉(年代,“%”)= eraseBetween(年代,“美元”,“美元”,“界限”,“包容”)
s =“让一美元的4×4幻方杜勒的_Melancholia_。”s =“让4×4的幻方杜勒的_Melancholia_。”
克里夫的角落
这个项目的文档是MATLAB文件构成本博客的源文本。我开始写这个博客版克里夫的角落五年前,2012年6月。
每个帖子来自一个MATLAB文件处理发布命令。大部分的线从一个文件中的注释%。这些成为《华盛顿邮报》的散文。从一开始的评论% %生成标题和章节标题。文本在‘|’字符呈现固定宽度字体代表变量和代码。文本中“$”字符是乳胶MathJax最终排版的。
我收集了5年的源文件在一个目录中,博客在我的电脑。该声明
D = doc_list (“博客”);
生成一个字符串数组的文件名博客。的前几行D是
D (1:5)
ans = 5×1 apologies_blog字符串数组”。米”“arrowhead2。米”“反斜杠。米”“平衡。米" "biorhythms.m"
的语句
n =长度(D) n / 5
n = 135 ans = 27
告诉我有多少帖子我,每年有多少帖子。这是一个平均约每两周。
生成的文件今天的帖子是包含在图书馆。
为j = 1: n如果包含(D {j},“大规模集成电路”)j D {j}结束结束
j = 75 ans = ' lsi_blog.m '
读文章
下面的代码加每个文件名和目录名,每个帖子读入一个字符串年代,数量我写的行数,并计算平均每个职位的行数。
行= 0;为j = 1: n s = read_blog (“博客/”+ D {j});行=线+长度(s);结束线avg =线/ n
美国航空志愿队(飞虎队)= 15578 = 115.3926
停止词
最常见的词在博客克里夫的角落是“的”。本身”、“占总数的8%以上。这是大致相同的比例在大样本的英语散文。
停止词很短,经常使用的单词,如“”,可以排除频率计数比较文档时,因为他们是没有价值的。这里是一个列表25个常用的停止词。
我要用蛮力,容易实现,战略停止的话。我指定一个整数参数,停止,简单地忽略所有单词停止或更少的字符。值为零停止意味着不忽略任何单词。我要展示一些实验后,我将决定停止= 5。
找到条件
这是这个项目的核心代码。输入文件的列表D和控制参数停止。代码扫描所有文档,查找和计算的每一个字。在这个过程中它
- 跳过所有noncomment行
- 跳过所有嵌入式乳胶
- 跳过所有代码片段
- 跳过所有url
- 忽略所有单词停止或更少的字符
代码打印一些中间结果然后返回三个数组。
- T,字符串数组独特的单词。这些条款。
- C、T的频率计数。
- ,(稀疏)术语/文档矩阵。
这个词/文档矩阵米——- - - - - -n,在那里
- 米= T是术语的数量的长度,
- n= D是文档的数量的长度。
类型find_terms
函数(T C] = find_terms (D,停止)% (T C] = find_terms (D、停止)%输入% D %停止= =文档列表的长度停止词%输出% T =条款,按照字母顺序排列的% C =项条款% =术语/文档矩阵[W Cw wt] = words_and_counts (D、停止);T =条款(W);m =长度(T);流(' \ n \ n停止= % d \ n字= % d % d \ n \ n \ n m =”,停止,wt, m) A = term_doc_matrix (W、连续波、T);完整C =((, 2)总和);(Cp, p) =排序(C,“下”);Tp = T (p);%的条款按频率频率= Cp / wt;10 = 10;流(“标引词数分数\ n”) k = 1:十流(% 8 d % 12年代% 8 d % 9.4 f \ n, k, Tp (k), Cp (k),频率(k)结束总=总和(频率(1:10)); fprintf('%s total = %7.4f\n',blanks(24),total) end
不停止的话
让我们运行代码停止设置为零所以没有停止的话。十个最常用单词占四分之一以上的所有文字和描述文档是无用的。注意,本身”、“占超过8%的所有单词。
停止= 0;find_terms (D、停止);
停止= 0字= 114512 = 8896指数项数分数1 9404 0.0821 2885 0.0252 3941 0.0344 - 3 4和6 2685 0.0234 2561 0.0224 2358 0.0206 2272年7 0.0198 8,1308 0.0114 1128 0.0099 969 0.0085 = 0.2577
三个字符或更少
削减跳过所有单词和三个或更少的字符的单词总数近一半和消除“的”,但仍大多无趣的词在前十。
停止= 3;find_terms (D、停止);
停止=三个字= 67310 = 8333指数项数分数1 1308 0.0194 969 0.0144 907 0.0135 509 0.0076 - 5 4矩阵与481 0.0071 472 0.0070 matlab 7 438 0.0065 8点约363 0.0054 9头350 0.0052 303 0.0045 = 0.0906
5个字符或更少
设置停止4是一个合理的选择,但我们更咄咄逼人。与停止等于5,最频繁的十个字现在更本博客的特征。所有进一步的计算使用这些结果。
停止= 5;[T、C、A] = find_terms (D、停止);m =长度(T);
停止= 5字= 38856 = 6459指数项数分数1矩阵509 0.0131 472 0.0121 302 0.0078函数4 matlab数字224 0.0047 184 0.0058 199 0.0051浮动6精密电脑167 0.0043 164算法数值0.0042 9值160 0.0041 158 0.0041 = 0.0653
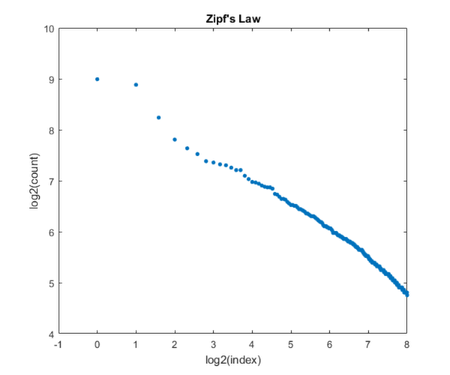
Zipf定律
这只是一个一边。Zipf定律乔治·金斯利Zipf命名,尽管他没有创意。一个示例的法律规定,自然语言,任何词的频率成反比的频率表中的索引。
换句话说,如果频率计数C按频率排序,那么一块吗日志(C (1: k))与日志(1:k)应该是一条直线。我们的频率计数只模模糊糊地遵循这个法律,但重对数坐标图让很多数量成比例。(我们得到更好地符合法律与较小的值停止。)
Zipf (C)
圣言会
现在我们准备计算出圣言。我们不妨一个完整的;它只有n= 135列。但一个很高和瘦,所以重要的是要使用吗“经济学”国旗,U也只有135列。如果没有这个标志,我们将要求一个广场米——- - - - - -米矩阵U与米6000岁以上的老人。
(U, V) =圣言(完整的(A),“经济学”);
查询
这是一个初步尝试函数查询。
类型查询
帖子=函数查询(查询,k,截止,T, U,年代,V, D) %的帖子=查询(查询,k,截止,T, U, V, D) % k秩矩阵近似术语/文档。英国= U (:, 1: k);Sk = S (1: k 1: k);Vk = V (:, 1: k);%构造查询向量相关的条款。m =大小(U, 1);q = 0 (m, 1);i = 1:长度(查询)%找到查询关键字的索引术语列表。{我}wi = word_index(查询,T);问(wi) = 1; end % Project the query onto the document space. qhat = Sk\Uk'*q; v = Vk*qhat; v = v/norm(qhat); % Pick off the documents that are close to the query. posts = D(v > cutoff); query_plot(v,cutoff,queries) end
试一试
设置秩k和截止的水平。
排名= 40;截止= 2;
尝试几个单词查询。
查询= {“奇异”,“凑整”,“威尔金森”};为j = 1:长度查询(查询)queryj = = {j}职位查询(queryj、等级、截止,T, U, V, D) snapnow结束
queryj =“奇异”的帖子= 4×1 eigshowp_w3字符串数组”。米”“four_spaces_blog。米”“parter_blog。米" "svdshow_blog.m"

queryj =“凑整”帖子= 5×1 condition_blog字符串数组”。米”“漂浮。米" "partial_pivot_blog.m" "refine_blog.m" "sanderson_blog.m"

queryj =“威尔金森”帖子= 2×1 dubrulle字符串数组”。m jhw_1.m”

注意查询关于威尔金森发现发布关于他还有篇关于Dubrulle,改善威尔金森算法。
结局,合并所有的查询。
查询帖子=查询(查询、等级、截止、T, U, V, D)
查询= 1×3单元阵列(“奇异”)(“凑整”)(“威尔金森”)的帖子= 5×1 four_spaces_blog字符串数组”。m jhw_1.m”"parter_blog.m" "refine_blog.m" "svdshow_blog.m"

- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
代码
doc_list
类型doc_list
函数D = doc_list (dir) % D = doc_list (dir)是一个字符串数组的文件名“dir”。D = " ";(地位、L) =系统((“ls”dir));如果状态~ = 0错误([“找不到”dir])结束k1 = 1;i = 1;k2 =找到(L = =换行)D(我:)= L (k1: k2-1);我=我+ 1;k1, k2 + 1;结束结束
erase_stuff
类型erase_stuff
功能多= erase_stuff (s) % s = erase_stuff (s) %擦除noncomments !系统,乳胶,url,快递和标点符号。j = 1;k = 1;而k < = (s) sk长度=低(char (s (k)));如果长度(sk) > = 4 sk(1) ~ =‘%’%跳过非打破elseif任何评论(sk = =“!”) & & (sk = = ' | ') %跳过!系统|…打破elseif所有(sk(3:4) = =“美元”)sk (3:4) = ';%跳过显示乳胶虽然所有(sk ~ =“美元”)k = k + 1;sk = char (s (k));其他结束%嵌入式乳胶sk = eraseBetween (sk,“美元”,“美元”,“边界”,“包容性”);%如果任何URL (sk = = ' < ')如果~ (sk = = >) k = k + 1; sk = [sk lower(char(s(k)))]; end sk = eraseBetween(sk,'<','>','Boundaries','inclusive'); sk = erase(sk,'>'); end if contains(string(sk),"http") break end % Courier f = find(sk == '|'); assert(length(f)==1 | mod(length(f),2)==0); for i = 1:2:length(f)-1 w = sk(f(i)+1:f(i+1)-1); if length(w)>2 && all(w>='a') && all(w<='z') sk(f(i)) = ' '; sk(f(i+1)) = ' '; else sk(f(i):f(i+1)) = ' '; end end % Puncuation sk((sk<'a' | sk>'z') & (sk~=' ')) = []; sout(j,:) = string(sk); j = j+1; end end k = k+1; end skip = k-j; end
find_words
类型find_words
函数w = find_words(年代,停止)%单词(年代,停止)找到单词的长度>停止文本字符串。w = " ";i = 1;k = 1:长度(s) sk = [“char (s {k})' ');f = strfind (sk”、“);j = 1:长度(f) 1 t = strtrim (sk (f (j): f (j + 1)));%不停止的话如果长度(t) < =停止继续结束如果~ isempty (t) w{我1}= t;我=我+ 1;结束结束结束
query_plot
类型query_plot
函数query_plot (v,截止、查询)clf宋惠乔情节(v,‘。’,‘markersize’, 12) ax =轴;马克斯(abs yax = 1.1 * (ax (3:4)));轴([ax (1:2) -yax yax])线(ax(1:2),(截止截止),“颜色”,“k”)标题(sprintf (“% s”,查询{:}))
read_blog
类型read_blog
函数s = read_blog(文件名)% read_blog(文件名)%跳过,不以“%”开始。fid = fopen(文件名);行= fgetl (fid);k = 1;虽然~ isequal eof(线,1)% 1信号如果长度(线)> 2 & &线(1)= =‘%’s (k,:) =字符串(线);k = k + 1;结束行= fgetl (fid);最终文件关闭(fid);结束
term_doc_matrix
类型term_doc_matrix
函数= term_doc_matrix (W C T) % = term_doc_matrix (W C T) m =长度(T);n =长度(W);一个=稀疏(m, n);j = 1: n nzj =长度(W {j});我= 0 (nzj, 1);s = 0 (nzj, 1);k = 1: nzj (k) = word_index (W {j} (k), T);年代(k) = C {j} (k);结束(i, j) = s;结束结束
word_count
类型word_count
函数[wout,计数]= word_count (w) % [w,计数]= word_count (w)独特的单词计数。w = (w)进行排序;wout = " ";数= [];i = 1;k = 1;而k < =长度(w) c = 1;而k <长度(w) & & isequal (w w {k}, {k + 1}) c = c + 1;k = k + 1;结束wout{我1}= w {k}; count(i,1) = c; i = i+1; k = k+1; end [count,p] = sort(count,'descend'); wout = wout(p); end
word_index
类型word_index
函数p = word_index (w,列表)%的w指数列表。%返回空如果w不在列表。m =长度(列表);p =修复(m / 2);q =装天花板(p / 2);t = 0;达峰时间=装天花板(log2 (m));%二进制搜索,列表(p) ~ = w如果列表(p) > w p = max (p q, 1);其他p =最小(p + q, m);结束q =装天花板(q / 2); t = t+1; if t == tmax p = []; break end end end
words_and_counts
类型words_and_counts
函数[W Cw wt] = words_and_counts (D,停止)% (W Cw wt) = words_and_counts (D,停止)W = [];%单词Cw = [];%计算wt = 0;n =长度(D);j = 1: n s = read_blog(“博客/”+ D {j});s = erase_stuff(年代);w = find_words(年代,停止);[W {j, 1}, Cw {j, 1}] = word_count (W);wt = wt +长度(w);结束结束
Zipf
类型Zipf
函数Zipf (C) % Zipf (C)情节log2 (C (1: k))与log2 (1: k) C =排序(C,“下”);%按照频率计数排序图(1)clf宋惠乔k = 256;情节(log2 (1: k), log2 (C (1: k)),“。”,“markersize”, 12)轴([1 8 4 10])包含(log2(索引))ylabel (log2(计数))标题(Zipf”年代法律)drawnow结束







评论
留下你的评论,请点击在这里MathWorks账户登录或创建一个新的。