 克利夫角:克利夫莫勒的数学和计算
克利夫角:克利夫莫勒的数学和计算 MATLAB博客
MATLAB博客 用MATLAB进行图像处理
用MATLAB进行图像处理 Simulin金宝appk上的Guy
Simulin金宝appk上的Guy 深度学习
深度学习 开发区域
开发区域 Stuart的MATLAB视频
Stuart的MATLAB视频 头条新闻背后
头条新闻背后 本周文件交换选择
本周文件交换选择 汉斯谈物联网
汉斯谈物联网 学生休息室
学生休息室 MATLAB社区
MATLAB社区 Matlabユザコミュニティ
Matlabユザコミュニティ高级深度学习:关键术语
自定义训练循环中的关键术语
在这篇文章中,我想详细谈谈损失,模型梯度,自动分化这是高级深度学习系列文章的第2部分。欲阅读该系列,请参阅以下链接:
|
 循环中的关键步骤
我想用一个非常简单的问题来突出这个循环的重要部分,重点是上面图中不可选的部分。我们的模型有2个可学习参数,x1和x2,我们的目标是优化这些参数,使我们的函数的输出为0:
循环中的关键步骤
我想用一个非常简单的问题来突出这个循环的重要部分,重点是上面图中不可选的部分。我们的模型有2个可学习参数,x1和x2,我们的目标是优化这些参数,使我们的函数的输出为0:
Y = (x2 - x1.^2)^2 + (1 - x1) ^2;我们将优化我们的模型,直到y = 0;这是一个用于统计问题的相当经典的方程(Rosenbrock)。(提示,在x1 = 1和x2 = 1处有一个解)。 我们将从猜测最佳解x1 = 2, x2 = 2开始。这只是一个起点,这段代码将展示我们如何改变这些参数来改进我们的模型,并最终得到一个解决方案。
定义可学习参数,初始猜测为2,2My_x1 = 2;My_x2 = 2;Learn_rate = 0.1;%设置(转换为darray)X1 = dlarray(my_x1);X2 = dlarray(my_x2);调用dlfeval,使用my_loss函数计算模型梯度和损失[loss,dydx1,dydx2] = dlfeval(@my_loss,x1,x2);%更新模型[new_x1,new_x2] = updateModel(x1,x2,dydx1,dydx2,learn_rate);%绘制当前值情节(extractdata (new_x1) extractdata (new_x2),“处方”);*你看到这个循环和深度学习之间的相关性了吗?我们的方程或“模型”要简单得多,但概念是一样的。在深度学习中,我们有“可学习的东西”,比如权重和偏差。这里有两个可学习的参数(x1和x2)。随着时间的推移,改变训练中的可学习内容可以提高模型的准确性。下面的训练循环做的事情与深度学习训练相同,只是更容易理解一些。 让我们回顾一下这个训练循环的所有步骤,并指出过程中的关键术语。
1.设置:读取数据,转换为dlarray
dlarray是设计用来包含深度学习问题的结构。这意味着对于任何“dl”函数(dlfeval, dlgradient)才能工作,我们需要将数据转换为adlarray然后转换回使用extractdata.2.计算模型梯度和损失
这发生在调用的函数中my_loss:函数[y,dydx1,dydx2] = my_loss(x1,x2) y = (x2 - x1.^2)。^2 + (1 - x1) ^2;%计算损失(或接近零的程度)[dydx1,dydx2] = dlgradient(y,x1,x2);计算导数结束代入x2和x1的值,我们得到:
 这不是0,这意味着我们必须找到一个新的猜测。的损失是误差,我们可以跟踪它来了解我们离一个好答案还有多远。使用梯度下降法,这是一种流行的策略更新参数的方法,我们计算梯度/导数,然后沿斜率相反的方向移动。
为了更好地理解这一点,让我们看看箭袋图:
这不是0,这意味着我们必须找到一个新的猜测。的损失是误差,我们可以跟踪它来了解我们离一个好答案还有多远。使用梯度下降法,这是一种流行的策略更新参数的方法,我们计算梯度/导数,然后沿斜率相反的方向移动。
为了更好地理解这一点,让我们看看箭袋图:
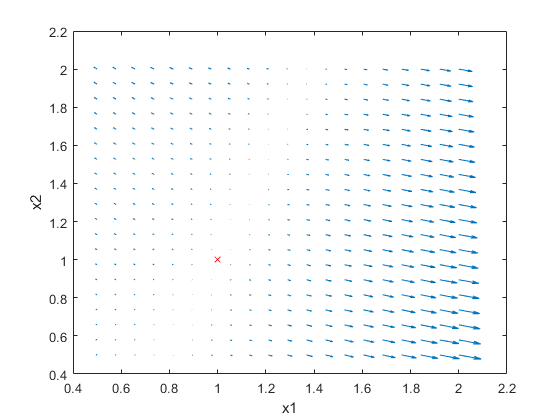 通过可视化不同点的梯度,我们可以看到,通过跟随梯度,我们最终可以找到图上正确的位置。
的文档dlfeval它很好地解释了dlgradient是如何工作的,这就是我偷了quiver情节想法的地方。
使用以下方法计算梯度dlgradient使用自动分化.这一刻我意识到自动微分的意思是这个函数会自动微分模型,告诉我们模型的梯度。没我想的那么可怕。
从函数中my_loss,我们得到模型梯度而且损失,用于计算新的可学习参数,以改进模型。
通过可视化不同点的梯度,我们可以看到,通过跟随梯度,我们最终可以找到图上正确的位置。
的文档dlfeval它很好地解释了dlgradient是如何工作的,这就是我偷了quiver情节想法的地方。
使用以下方法计算梯度dlgradient使用自动分化.这一刻我意识到自动微分的意思是这个函数会自动微分模型,告诉我们模型的梯度。没我想的那么可怕。
从函数中my_loss,我们得到模型梯度而且损失,用于计算新的可学习参数,以改进模型。
3.更新模型
在我们的循环中,下一步是使用梯度更新模型以找到新的模型参数。%更新模型[new_x1,new_x2] = updateModel(x1,x2,dydx1,dydx2,learn_rate);
使用梯度下降,我们将更新这些参数,沿着斜率的相反方向移动:
function [new_x1,new_x2] = updateModel(x1,x2,dydx1,dydx2,learn_rate);Newx1 = x1 + -dydx1*learn_rate;Newx2 = x2 + -dydx2*learn_rate;结束请注意,这就是这个例子和深度学习的不同之处:您不负责确定新的可学习内容.这是通过优化器ADAM或SGDM或任何你选择的优化器在真实的训练循环中完成的。在深度学习中,将这个updateModel函数替换为SGDMUpdate或ADAMUpdate 的学习速率就是你想在某个方向上移动多快。更高意味着更快或更大的跳跃,但我们马上就会看到这对你的训练有很大的影响。 循环训练
定义可学习参数,初始猜测为2,2My_x1 = 2;My_x2 = 2;Learn_rate = 0.1;%设置(转换为darray)X1 = dlarray(my_x1);X2 = dlarray(my_x2);%循环从这里开始:对于ii = 1:100调用dlfeval,使用my_loss函数计算模型梯度和损失[loss,dydx1,dydx2] = dlfeval(@my_loss,x1,x2);%更新模型[x1,x2] = updateModel(x1,x2,dydx1,dydx2,learn_rate);%绘制当前值情节(extractdata (x1)、extractdata (x2)、“软”);结束这是训练的示意图
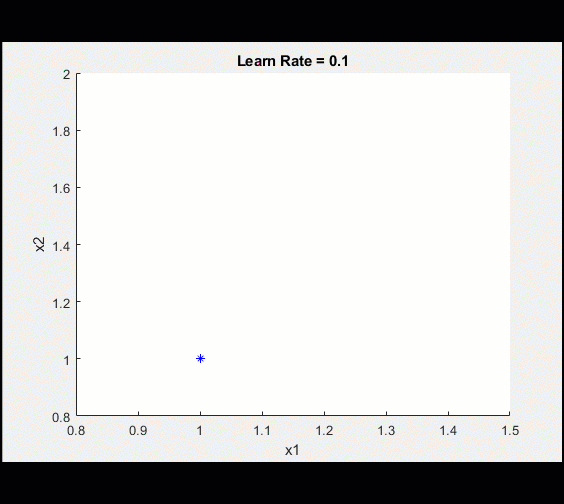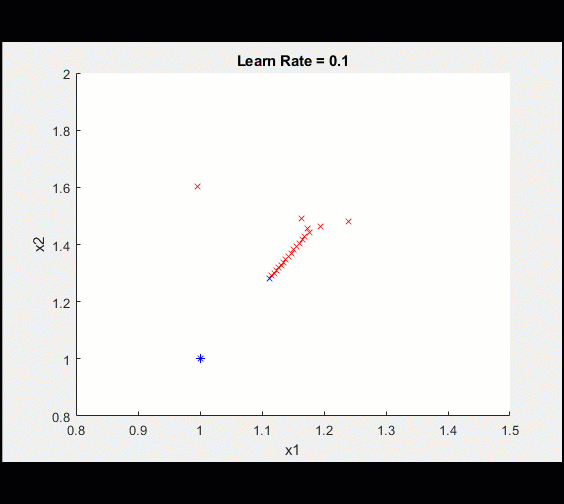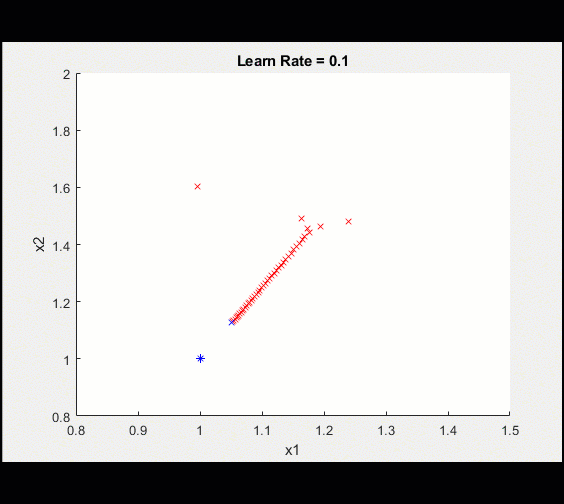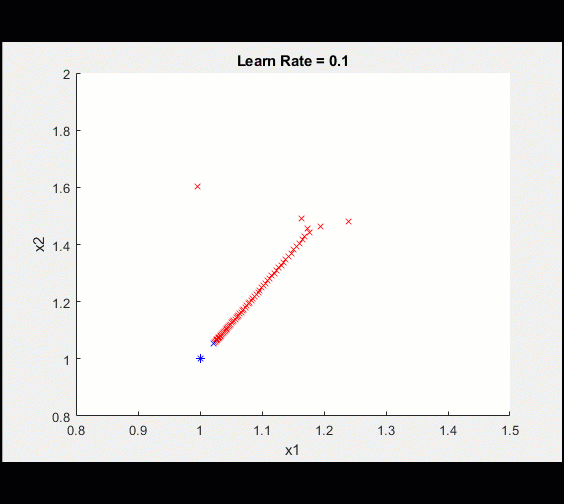 在100次迭代之后,我们可以看到训练越来越接近最优值。
学习率的重要性
如前所述,学习速率就是我们能以多快或多大的速度向最优解移动。更大的一步可能意味着你更快地到达解决方案,但你可能跳过它,永远不会收敛。
下面是上面相同的训练循环,learn_rate = 0.2而不是0.1:学习率太高意味着我们可能会偏离并永远陷入次优解决方案。
在100次迭代之后,我们可以看到训练越来越接近最优值。
学习率的重要性
如前所述,学习速率就是我们能以多快或多大的速度向最优解移动。更大的一步可能意味着你更快地到达解决方案,但你可能跳过它,永远不会收敛。
下面是上面相同的训练循环,learn_rate = 0.2而不是0.1:学习率太高意味着我们可能会偏离并永远陷入次优解决方案。
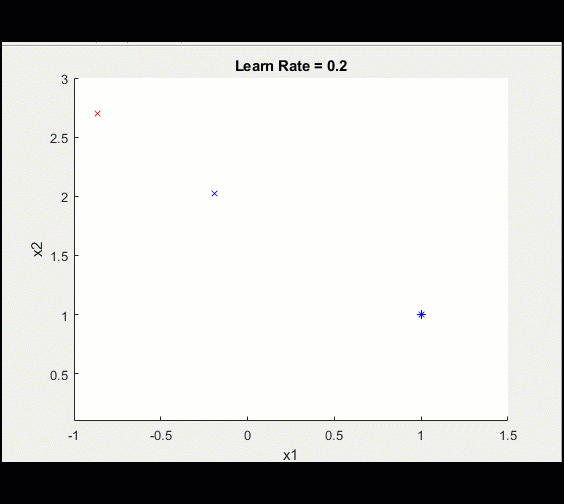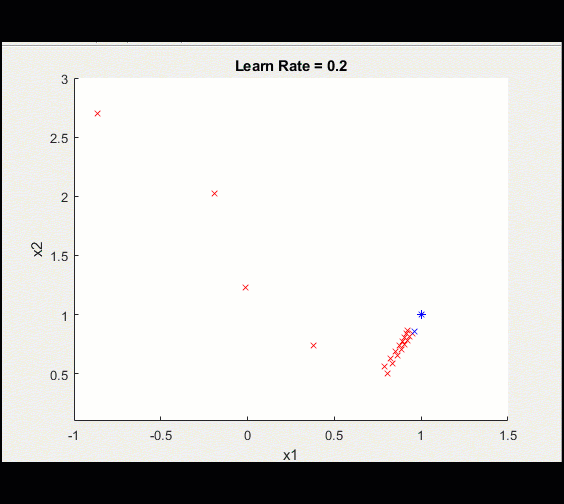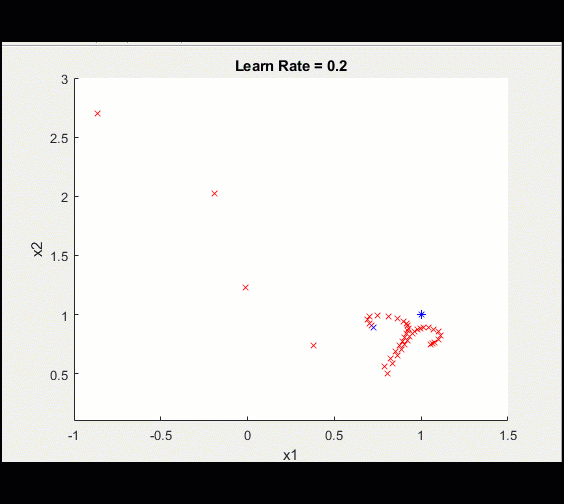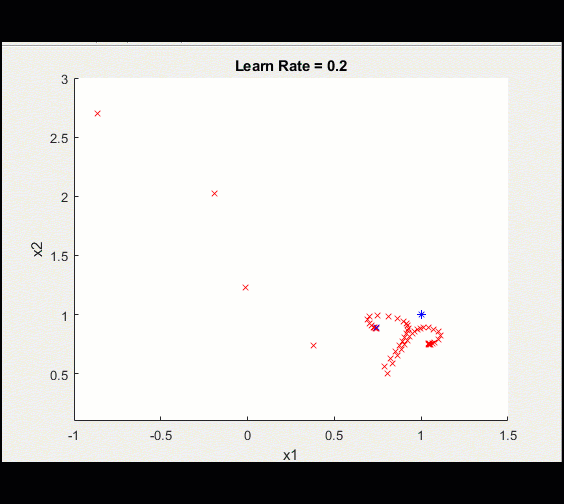 注意,由于学习率较高,这种训练并没有收敛到最优解。
所以大的学习率可能会有问题,但小的一步可能意味着你移动得太慢(打哈欠),或者我们可能会以局部最小值结束,或者可能需要一生的时间才能完成。
那么,你会怎么做呢?一种建议是在开始时以较高的学习率开始,然后在接近解决方案时转向较低的学习率,我们可以想象一下,称之为“基于时间的衰减”。
输入自定义学习率,在我们的自定义训练图中很容易实现*。
注意,由于学习率较高,这种训练并没有收敛到最优解。
所以大的学习率可能会有问题,但小的一步可能意味着你移动得太慢(打哈欠),或者我们可能会以局部最小值结束,或者可能需要一生的时间才能完成。
那么,你会怎么做呢?一种建议是在开始时以较高的学习率开始,然后在接近解决方案时转向较低的学习率,我们可以想象一下,称之为“基于时间的衰减”。
输入自定义学习率,在我们的自定义训练图中很容易实现*。
设置自定义学习速率initialLearnRate = 0.2;衰减= 0.01;learn_rate = initialLearnRate;对于ii = 1:100%……%更新自定义学习率learn_rate = initialLearnRate /(1 +衰减*迭代);结束当然,学习率函数可能很复杂,但是将它添加到我们的训练循环中是很简单的。
| 100次迭代的学习率如下所示: | 这使得我们的模型收敛得更清晰: |
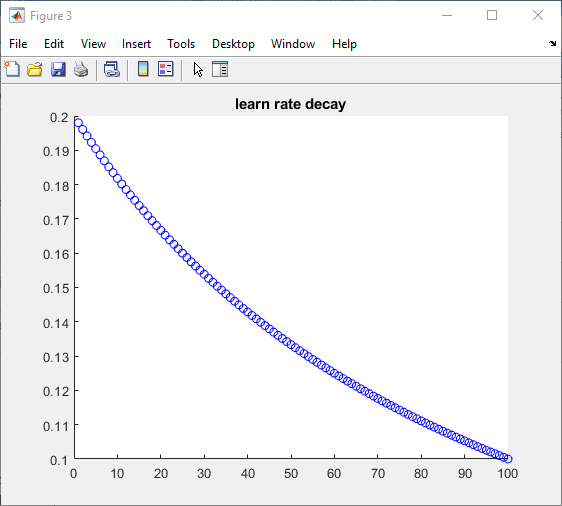 |
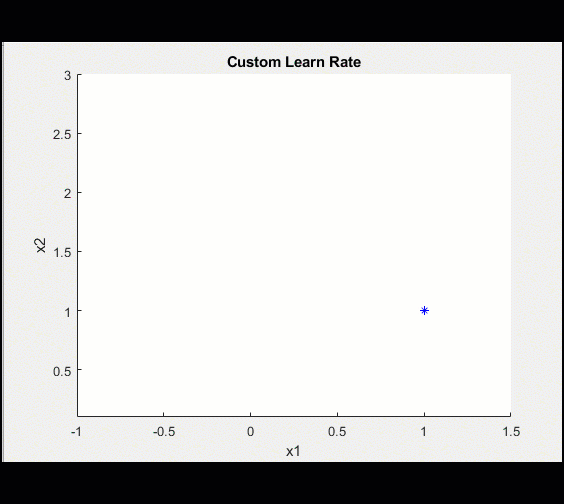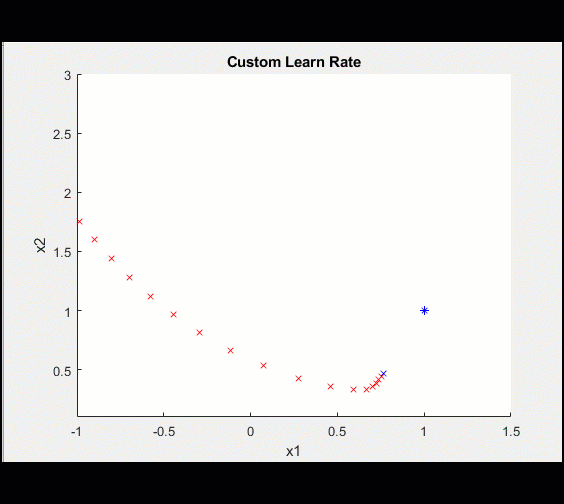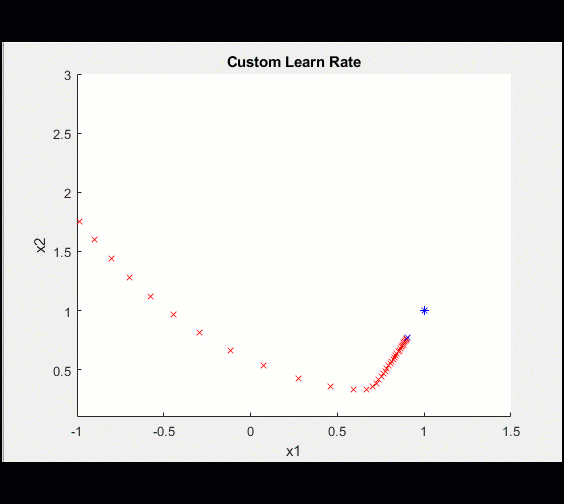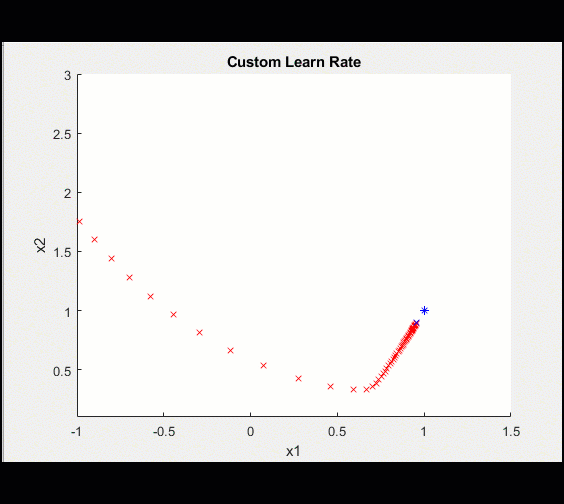 |
- dlfeval
- dlgradient
- Dlarray &提取数据
- 自动分化:
- 损失
- 模型梯度
- 学习速率
- dlfeval:还介绍了rosenbrock方程的建立。
- 更多关于自动分化
- 更多关于解决方案。,有时称为香蕉函数,这是示例中使用的优化函数
- 全深度学习示例
- 创建自定义深度学习层
- 类别:
- 深度学习


另请参阅
-

高级深度学习:第一部分
博客
-
糖尿病视网膜病变的检测
博客
-

使用GANs生成合成图像
博客
-
-




评论
如欲留言,请点击在这里登录您的MathWorks帐户或创建一个新帐户。