 克里夫角:克里夫·摩尔论数学与计算
克里夫角:克里夫·摩尔论数学与计算 罗兰关于MATLAB的艺术
罗兰关于MATLAB的艺术 用MATLAB进行图像处理
用MATLAB进行图像处理 人在仿真软件金宝app
人在仿真软件金宝app 深度学习
深度学习 开发区域
开发区域 斯图尔特的MATLAB视频
斯图尔特的MATLAB视频 在标题后面
在标题后面 本周文件交换精选
本周文件交换精选 汉斯在物联网
汉斯在物联网 学生休息室
学生休息室 创业公司、加速器和企业家
创业公司、加速器和企业家 MATLAB社区
MATLAB社区 MATLABユーザーコミュニティー
MATLABユーザーコミュニティー高级深度学习:第1部分
建立任何深度学习网络
在接下来的几篇文章中,我希望大家都走出自己的舒适区。我将探索和展示更高级的深度学习主题。发行版19b引入了许多令人兴奋的新特性,我一直在犹豫是否要尝试这些特性,因为人们开始抛出一些术语,比如自定义训练循环、自动区分(如果你真的知道的话,甚至还有“autodiff”)。但我认为是时候深入探索新概念了,不仅要理解它们,还要理解在哪里以及为什么要使用它们。
除了深度学习的基础知识,还有很多东西需要消化,所以我决定写一系列的帖子。你现在读的这篇文章将作为一个温和的介绍来奠定基础和关键术语,然后是一系列关于个人网络类型(自动编码器、暹罗网络、GANs和注意机制)的文章。
高级深度学习基础
首先,让我们从为什么:“为什么我要费心使用扩展的深度学习框架?到目前为止,我一直过得很好。”首先,你可以得到一个灵活的培训结构,允许你在MATLAB中创建任何网络。下一篇文章中介绍的更复杂的结构需要扩展框架来解决以下功能:


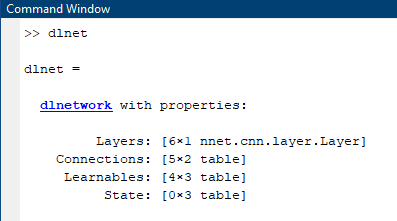 dlnetwork具有层和连接等属性(可以处理Series或DAG网络),还可以存储“可学习内容”。稍后再详细介绍。
dlnetwork具有层和连接等属性(可以处理Series或DAG网络),还可以存储“可学习内容”。稍后再详细介绍。
 您将注意到明确定义了许多非可选参数:这些参数将在自定义训练循环中使用。同样,我们不再有像在基本框架中一样的漂亮的训练情节的选择。
您将注意到明确定义了许多非可选参数:这些参数将在自定义训练循环中使用。同样,我们不再有像在基本框架中一样的漂亮的训练情节的选择。
 进入训练循环之前你需要知道的基本知识:
进入训练循环之前你需要知道的基本知识:
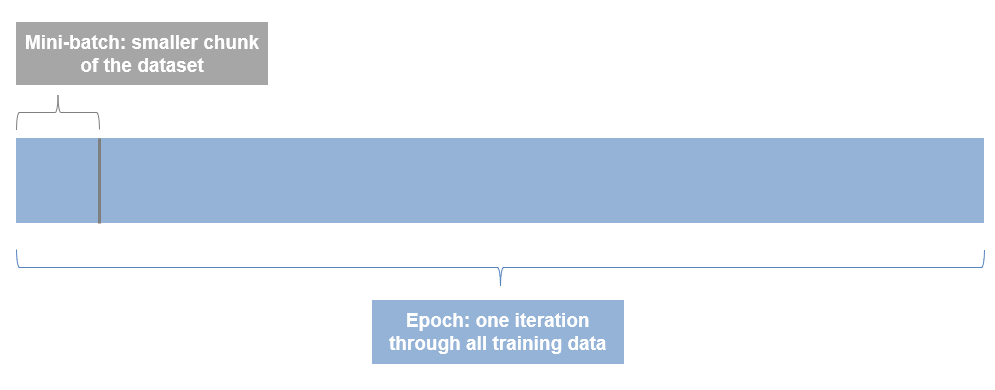 所以根据我们上面定义的参数,我们的自定义训练循环将遍历整个数据集30次,由于我们的小批量大小是128,我们的图像总数是5000,它将需要39次迭代来遍历数据1次。这是自定义训练循环的结构。完整的代码在医生的例子,我要提醒您,完整的脚本只有几行代码,但一旦您理解了整体结构,其中很多代码都很简单。
所以根据我们上面定义的参数,我们的自定义训练循环将遍历整个数据集30次,由于我们的小批量大小是128,我们的图像总数是5000,它将需要39次迭代来遍历数据1次。这是自定义训练循环的结构。完整的代码在医生的例子,我要提醒您,完整的脚本只有几行代码,但一旦您理解了整体结构,其中很多代码都很简单。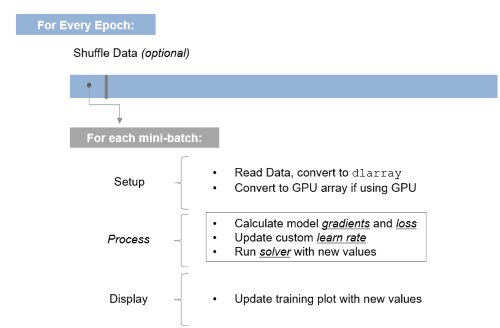 正如你可能已经猜到了基于突出显示在上面的可视化,本系列的下一篇文章将详细介绍循环的内部运作,和你需要知道的理解发生了什么损失,梯度、学习速率和更新网络参数。三种模型的方法最后一点要记住,当我将扩展框架与DLNetwork方法,还有一个模型函数当您还希望控制初始化和显式定义网络权重和偏差时使用的方法。该示例还可以使用模型函数方法,您可以按照此方法进行操作医生的例子要学习更多的知识。这种方法可以让您在3种方法中获得最大的控制,但也是最复杂的。整个景观如下所示:
正如你可能已经猜到了基于突出显示在上面的可视化,本系列的下一篇文章将详细介绍循环的内部运作,和你需要知道的理解发生了什么损失,梯度、学习速率和更新网络参数。三种模型的方法最后一点要记住,当我将扩展框架与DLNetwork方法,还有一个模型函数当您还希望控制初始化和显式定义网络权重和偏差时使用的方法。该示例还可以使用模型函数方法,您可以按照此方法进行操作医生的例子要学习更多的知识。这种方法可以让您在3种方法中获得最大的控制,但也是最复杂的。整个景观如下所示: 这篇文章到此为止。这是很多信息,但希望你能从中找到一些有用的信息。如果您有任何问题或澄清,请在下面留言!
这篇文章到此为止。这是很多信息,但希望你能从中找到一些有用的信息。如果您有任何问题或澄清,请在下面留言!
- 多输入多输出
- 定制的损失函数
- 体重分享
- 自动分化
- 训练期间的特殊可视化
- 定义网络层
- 指定培训选项
- 列车网络的
加载数据
[XTrain, YTrain] = digitTrain4DArrayData;[XTest, YTest] = digitTest4DArrayData;类=类别(YTrain);numClasses =元素个数(类);

1.定义网络层
创建一个网络,由一系列简单的层组成。layers=[imageInputLayer([28 28 1])卷积2dLayer(5,20,'Padding','same')批规格化层reluLayer MaxPoolig2dLayer(2,'Stride',2)fullyConnectedLayer(10)softmaxLayer classificationLayer];
2.指定培训选项
选项=培训选项('sgdm',…'InitialLearnRate',0.01,…'MaxEpochs',4,…'Plots','training-progress');这些都是简单的培训选项,并不一定是为了提供最佳效果。事实上trainingOptions只需要您设置优化器,其余可以使用默认值。
3.培训网络
网= trainNetwork (XTrain、YTrain层,选择);很简单!现在让我们在扩展框架中做同样的事情。 扩展框架的例子 同样的例子,只是使用扩展框架,或者我将要提到的“DLNetwork”来推进这种方法。这是代码的修改版本。下面是完整的示例,完整的代码在医生的例子.
加载数据
这是完全相同的,不需要显示重复代码。现在,我们可以展示简单方法和DLNetwork方法之间的差异:让我们并排比较以下每个步骤,以突出显示差异。
1.定义网络层
层几乎同样:我们只需要为每个层添加名称。这是在简单框架中显式处理的,但是我们需要做更多的准备工作。层=[…imageInputLayer([28 28 1], 'Name',' input','Mean', Mean (Xtrain,4))卷积2dlayer (5, 20, 'Name',' conv1') reluLayer('Name', 'relu1') maxPooling2dLayer(2, 'Stride', 2, 'Name',' pool1') fulllyconnectedlayer (10, 'Name',' fc') softmaxLayer('Name','softmax')];
请注意,在图层中,不再有分类图层。这将在训练循环中处理,因为这是我们想要定制的。
然后将层转换为layerGraph,这使它们在自定义训练循环中可用。另外,请指定包含网络的dlnet结构。
lgraph = layerGraph(层);dlnet = dlnetwork (lgraph);
 dlnetwork具有层和连接等属性(可以处理Series或DAG网络),还可以存储“可学习内容”。稍后再详细介绍。
dlnetwork具有层和连接等属性(可以处理Series或DAG网络),还可以存储“可学习内容”。稍后再详细介绍。
2.指定培训选项
 您将注意到明确定义了许多非可选参数:这些参数将在自定义训练循环中使用。同样,我们不再有像在基本框架中一样的漂亮的训练情节的选择。
您将注意到明确定义了许多非可选参数:这些参数将在自定义训练循环中使用。同样,我们不再有像在基本框架中一样的漂亮的训练情节的选择。
miniBatchSize = 128;numEpochs = 30;numObservations =元素个数(YTrain);numIterationsPerEpoch =地板(numObservations. / miniBatchSize);initialLearnRate = 0.01;动量= 0.9;executionEnvironment =“汽车”;韦尔= [];你现在要负责你自己的可视化,但这也意味着你可以在整个训练过程中创建你自己的可视化,并根据你的喜好定制任何关于网络的东西,这将有助于理解网络训练。 现在,让我们设置一个绘图,在网络训练时显示丢失/错误。
情节=“训练进步”;如果plot == "training-progress" figure lineLossTrain = animatedline;xlabel(“总迭代”)ylabel(“丢失”)结束
使用自定义训练循环的训练网络
 进入训练循环之前你需要知道的基本知识:
进入训练循环之前你需要知道的基本知识:
- 一个时代是对整个数据集的一次迭代。所以如果你有10个纪元,你将遍历所有文件10次。
- 一个Mini-batch是数据集的一个较小的块。数据集通常太大,无法同时放在内存或GPU上,因此我们分批处理数据。
 所以根据我们上面定义的参数,我们的自定义训练循环将遍历整个数据集30次,由于我们的小批量大小是128,我们的图像总数是5000,它将需要39次迭代来遍历数据1次。这是自定义训练循环的结构。完整的代码在医生的例子,我要提醒您,完整的脚本只有几行代码,但一旦您理解了整体结构,其中很多代码都很简单。
所以根据我们上面定义的参数,我们的自定义训练循环将遍历整个数据集30次,由于我们的小批量大小是128,我们的图像总数是5000,它将需要39次迭代来遍历数据1次。这是自定义训练循环的结构。完整的代码在医生的例子,我要提醒您,完整的脚本只有几行代码,但一旦您理解了整体结构,其中很多代码都很简单。for epoch = 1:numEpochs…for ii = 1:numIterationsPerEpoch%*设置:读取数据、转换为dlarray、传递到GPU...%评估模型梯度和损失[gradient, loss] = dlfeval(@modelGradients, dlnet, dlX, Y);%更新自定义学习速率learnRate = initialLearnRate/(1 +衰减*迭代);%使用SGDM优化器更新网络参数[dlnet。= sgdmupdate(dlnet。学习性,梯度,vel,学习率,动量);%更新培训图...结束结束为了完整起见,您创建了这个函数modelGradients这里定义了梯度和损失函数。更多细节将在下一篇文章中介绍。
function [gradient, loss] = modelGradients(dlnet, dlX, Y)loss = cross - sentropy(dlYPred, Y);gradient = dlgradient(loss, dlnet.Learnables);结束在这个简单的例子中,有一个函数trainnetwork已经扩展成一系列的循环和代码。我们这样做是为了在网络需要的时候,我们有更多的灵活性,当它过度破坏的时候,我们可以恢复到简单的方法。好消息是,这已经是最复杂的了:一旦你理解了这个结构,你就可以把正确的信息放进去了!对于那些想要可视化循环中发生的事情的人,我看到的是这样的:
 正如你可能已经猜到了基于突出显示在上面的可视化,本系列的下一篇文章将详细介绍循环的内部运作,和你需要知道的理解发生了什么损失,梯度、学习速率和更新网络参数。三种模型的方法最后一点要记住,当我将扩展框架与DLNetwork方法,还有一个模型函数当您还希望控制初始化和显式定义网络权重和偏差时使用的方法。该示例还可以使用模型函数方法,您可以按照此方法进行操作医生的例子要学习更多的知识。这种方法可以让您在3种方法中获得最大的控制,但也是最复杂的。整个景观如下所示:
正如你可能已经猜到了基于突出显示在上面的可视化,本系列的下一篇文章将详细介绍循环的内部运作,和你需要知道的理解发生了什么损失,梯度、学习速率和更新网络参数。三种模型的方法最后一点要记住,当我将扩展框架与DLNetwork方法,还有一个模型函数当您还希望控制初始化和显式定义网络权重和偏差时使用的方法。该示例还可以使用模型函数方法,您可以按照此方法进行操作医生的例子要学习更多的知识。这种方法可以让您在3种方法中获得最大的控制,但也是最复杂的。整个景观如下所示: 这篇文章到此为止。这是很多信息,但希望你能从中找到一些有用的信息。如果您有任何问题或澄清,请在下面留言!
这篇文章到此为止。这是很多信息,但希望你能从中找到一些有用的信息。如果您有任何问题或澄清,请在下面留言!
|
- 类别:
- 深度学习






评论
要留下评论,请点击在这里登录到您的MathWorks帐户或创建一个新帐户。