 克利夫角:克利夫·莫尔谈数学和计算机
克利夫角:克利夫·莫尔谈数学和计算机 罗兰关于MATLAB的艺术
罗兰关于MATLAB的艺术 用MATLAB进行图像处理
用MATLAB进行图像处理 人在仿真软件金宝app
人在仿真软件金宝app 深度学习
深度学习 开发区域
开发区域 斯图尔特的MATLAB视频
斯图尔特的MATLAB视频 在标题后面
在标题后面 本周文件交换精选
本周文件交换精选 汉斯在物联网
汉斯在物联网 学生休息室
学生休息室 初创企业、加速器和企业家
初创企业、加速器和企业家 MATLAB社区
MATLAB社区 MATLABユーザーコミュニティー
MATLABユーザーコミュニティー高级深度学习:关键术语
自定义训练循环中的关键术语
在这篇文章中,我想详细谈谈损失,模型梯度,自动分化这是高级深度学习系列文章的第2部分。如欲阅读本系列,请浏览以下连结:
|
 循环中的关键步骤
我想用一个非常简单的问题来突出这个循环的重要部分,着重于上图中非可选的部分。我们的模型有两个可学习的参数,x1和x2,我们的目标是优化这些参数,使函数的输出为0:
循环中的关键步骤
我想用一个非常简单的问题来突出这个循环的重要部分,着重于上图中非可选的部分。我们的模型有两个可学习的参数,x1和x2,我们的目标是优化这些参数,使函数的输出为0:
Y = (x2 - x1.²)²+ (1 - x1)²;我们将优化我们的模型直到y = 0;这是一个相当经典的方程(Rosenbrock),用于统计问题。(提示,在x1 = 1 x2 = 1处有一个解) 我们从猜测最优解x1 = 2 x2 = 2开始。这只是一个起点,这段代码将显示我们如何更改这些参数来改进我们的模型并最终得到一个解决方案。
定义可学习的参数,初始猜测2,2my_x1 = 2;my_x2 = 2;learn_rate = 0.1;%安装程序(转换为dlarray)x1 = dlarray (my_x1);x2 = dlarray (my_x2);%调用dlfeval,它使用my_loss函数来计算模型梯度和损失(损失、dydx1 dydx2] = dlfeval (@my_loss (x1, x2);%更新模型[new_x1, new_x2] =调用updateModel (x1, x2, dydx1、dydx2 learn_rate);%绘制当前值情节(extractdata (new_x1) extractdata (new_x2),“处方”);*你看到这个循环和深度学习之间的关联了吗?我们的方程或“模型”要简单得多,但概念是相同的。在深度学习中,我们有“可学习的东西”,比如权重和偏差。这里我们有两个可学习的参数(x1和x2)。随着时间的推移,改变训练中可学习的内容会增加模型的准确性。下面的训练循环做了与深度学习训练相同的事情,只是更容易理解。 让我们回顾一下这个训练循环的所有步骤,并指出其中的关键术语。
1.安装:读取数据,转换为dlarray
dlarray是用来容纳深度学习问题的结构。这意味着对于任何“dl”函数(dlfeval, dlgradient),我们需要将我们的数据转换为dlarray然后转换回使用extractdata.2.计算模型梯度和损失
这发生在被调用的函数中my_loss:函数[y,dydx1,dydx2] = my_loss(x1,x2) y = (x2 - x1.^2)²+ (1 - x1)²;%计算损失(或多么接近于零)[dydx1, dydx2] = dlgradient (y, x1, x2);计算导数结束代入x2和x1的值,我们得到:
 这不是0,这意味着我们必须找到一个新的猜想。的损失是误差,我们可以跟踪它来了解我们离一个好的答案有多远。使用梯度下降法我们计算梯度/导数,然后向与斜率相反的方向移动。
为了更好地形象化,让我们看一下颤抖图:
这不是0,这意味着我们必须找到一个新的猜想。的损失是误差,我们可以跟踪它来了解我们离一个好的答案有多远。使用梯度下降法我们计算梯度/导数,然后向与斜率相反的方向移动。
为了更好地形象化,让我们看一下颤抖图:
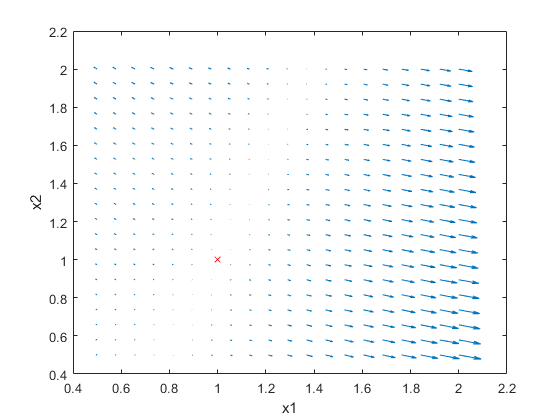 通过可视化不同点的梯度,我们可以看到,通过遵循梯度,我们最终可以找到在plot上的正确位置。
的文档dlfeval他很好地解释了dlgradient是如何工作的,这也是我偷取颤抖情节想法的地方。
使用以下方法计算梯度dlgradient使用自动分化.这是我意识到的时刻自动微分意味着这个函数会自动微分模型,并告诉我们模型的梯度。没有我想的那么可怕。
从函数中my_loss,我们得到模型梯度和损失,用于计算新的可学习参数,以改进模型。
通过可视化不同点的梯度,我们可以看到,通过遵循梯度,我们最终可以找到在plot上的正确位置。
的文档dlfeval他很好地解释了dlgradient是如何工作的,这也是我偷取颤抖情节想法的地方。
使用以下方法计算梯度dlgradient使用自动分化.这是我意识到的时刻自动微分意味着这个函数会自动微分模型,并告诉我们模型的梯度。没有我想的那么可怕。
从函数中my_loss,我们得到模型梯度和损失,用于计算新的可学习参数,以改进模型。
3.更新模型
在我们的循环中,下一步是使用梯度更新模型以找到新的模型参数。%更新模型[new_x1, new_x2] =调用updateModel (x1, x2, dydx1、dydx2 learn_rate);
使用梯度下降,我们将更新这些参数,向相反的方向移动:
function [new_x1,new_x2] = updateModel(x1,x2,dydx1,dydx2,learn_rate);Newx1 = x1 + -dydx1*learn_rate;Newx2 = x2 + -dydx2*learn_rate;结束请注意,这就是这个例子和深度学习的不同之处:您不负责确定新的可学习内容.这是通过优化器(ADAM或SGDM或您选择的任何优化器)在真正的训练循环中完成的。在深度学习中,将该updateModel函数替换为SGDMUpdate或ADAMUpdate 的学习速率就是你想在某个方向上移动多快。更高意味着更快或更大的跳跃,但我们马上就会看到这对你的训练有很强的影响。 循环训练
定义可学习的参数,初始猜测2,2my_x1 = 2;my_x2 = 2;learn_rate = 0.1;%安装程序(转换为dlarray)x1 = dlarray (my_x1);x2 = dlarray (my_x2);%循环从这里开始:对于ii = 1:100%调用dlfeval,它使用my_loss函数来计算模型梯度和损失(损失、dydx1 dydx2] = dlfeval (@my_loss (x1, x2);%更新模型(x1, x2) =调用updateModel (x1, x2, dydx1、dydx2 learn_rate);%绘制当前值情节(extractdata (x1)、extractdata (x2)、“软”);结束这是训练的情节
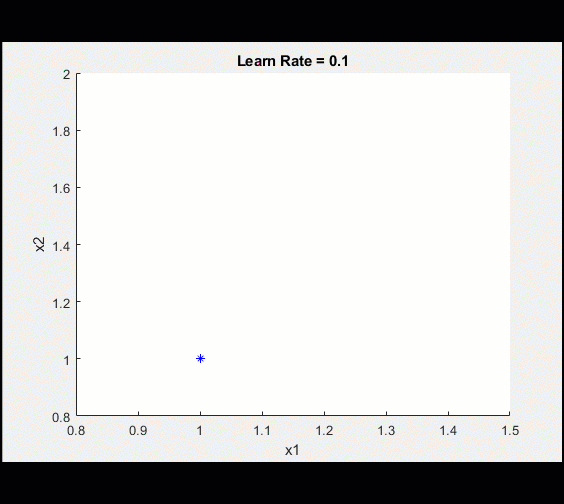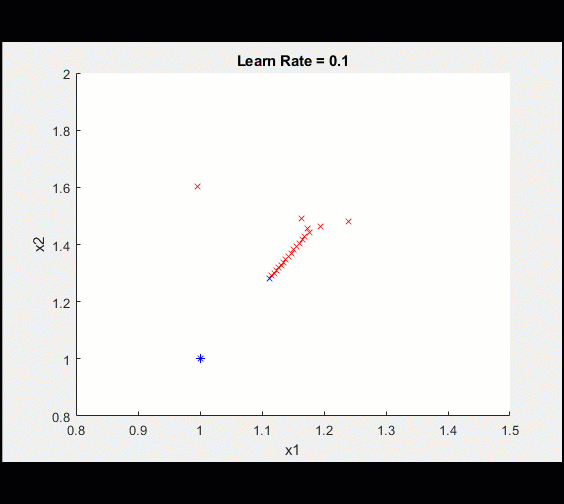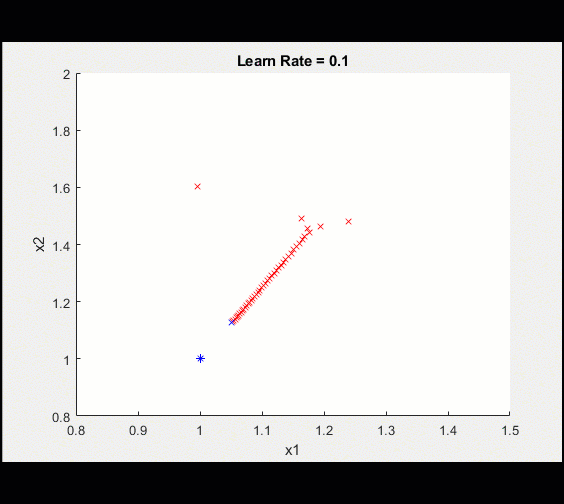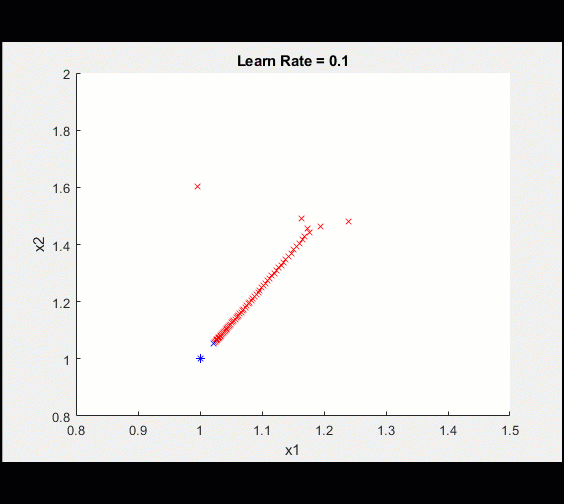 经过100次迭代后,我们将训练可视化,使其越来越接近最优值。
学习速度的重要性
如前所述学习速率就是我们可以采取多快或多大幅度的跳跃来达到最佳解决方案。一个更大的步骤可能意味着你更快地得到你的解决方案,但你可以跳过它,永远不会收敛。
这里是与上面相同的训练循环,learn_rate = 0.2而不是0.1:学习率过高意味着我们可能会偏离并永远卡在次优解决方案上。
经过100次迭代后,我们将训练可视化,使其越来越接近最优值。
学习速度的重要性
如前所述学习速率就是我们可以采取多快或多大幅度的跳跃来达到最佳解决方案。一个更大的步骤可能意味着你更快地得到你的解决方案,但你可以跳过它,永远不会收敛。
这里是与上面相同的训练循环,learn_rate = 0.2而不是0.1:学习率过高意味着我们可能会偏离并永远卡在次优解决方案上。
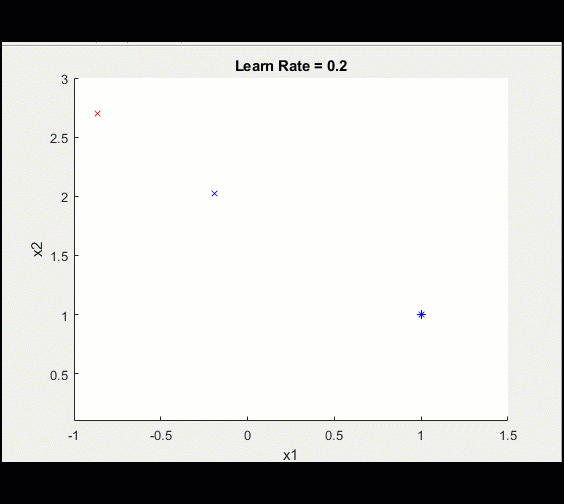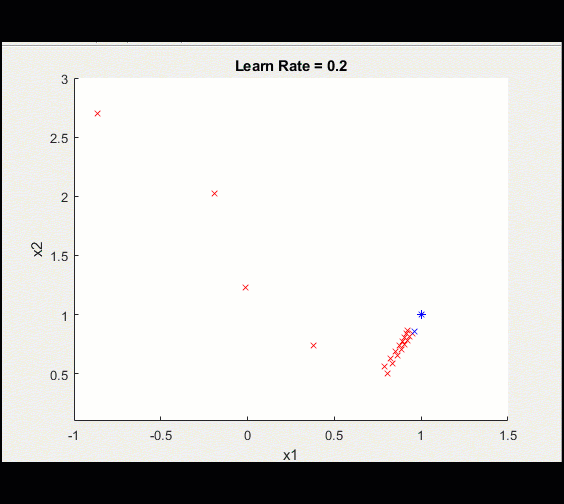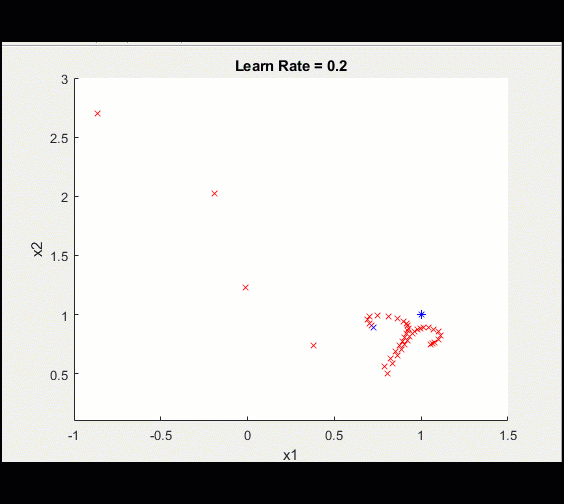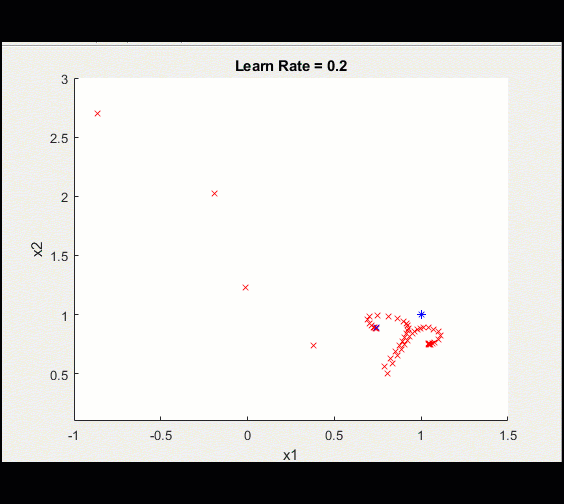 请注意,这种训练并没有收敛到最优解,这是由于较高的学习率造成的。
所以一个大的学习速率可能是有问题的,但是一个较小的步骤可能意味着你移动得太慢了(打哈欠),或者我们可能会以局部最小值结束,或者可能需要一辈子才能完成。
那么,你会怎么做?一个建议是在一开始使用更高的学习率,然后在接近解决方案时使用较低的学习率,我们可以称之为“基于时间的衰减”。
输入定制的学习速率,在我们的定制训练图中很容易实现*。
请注意,这种训练并没有收敛到最优解,这是由于较高的学习率造成的。
所以一个大的学习速率可能是有问题的,但是一个较小的步骤可能意味着你移动得太慢了(打哈欠),或者我们可能会以局部最小值结束,或者可能需要一辈子才能完成。
那么,你会怎么做?一个建议是在一开始使用更高的学习率,然后在接近解决方案时使用较低的学习率,我们可以称之为“基于时间的衰减”。
输入定制的学习速率,在我们的定制训练图中很容易实现*。
%安装程序自定义学习率initialLearnRate = 0.2;衰变= 0.01;learn_rate = initialLearnRate;对于ii = 1:100%…%更新自定义学习速率learn_rate = initialLearnRate /(1 +衰减*迭代);结束*当然,学习速率函数可能很复杂,但将其添加到我们的训练循环中是直接的。
| 在100次迭代中,学习率是这样的: | 这使得我们的模型收敛得更清晰: |
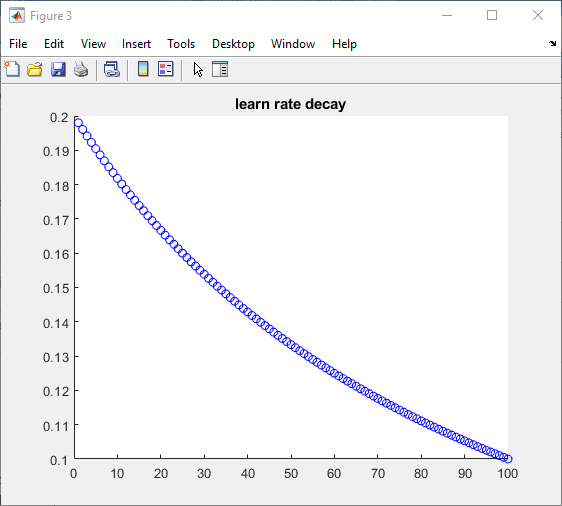 |
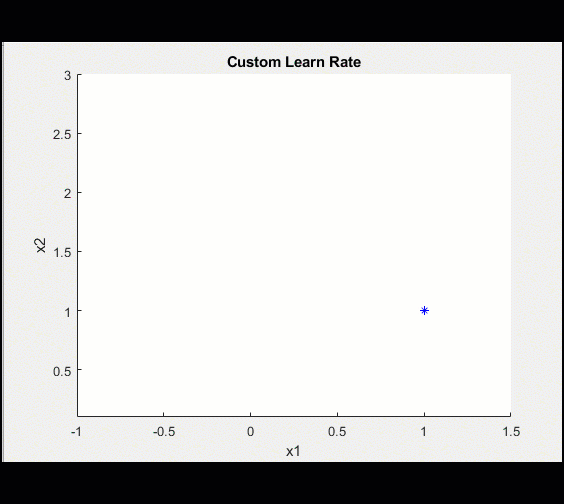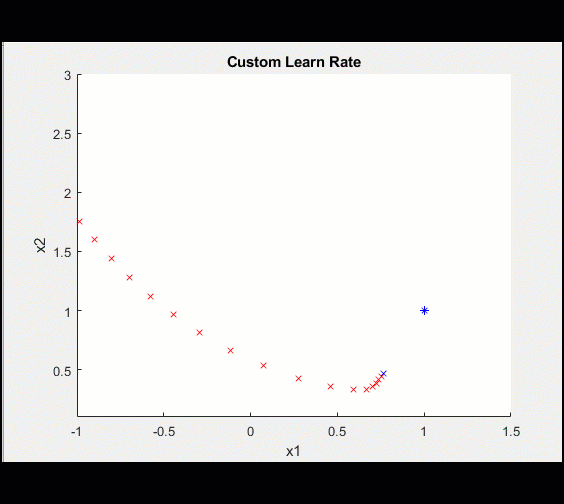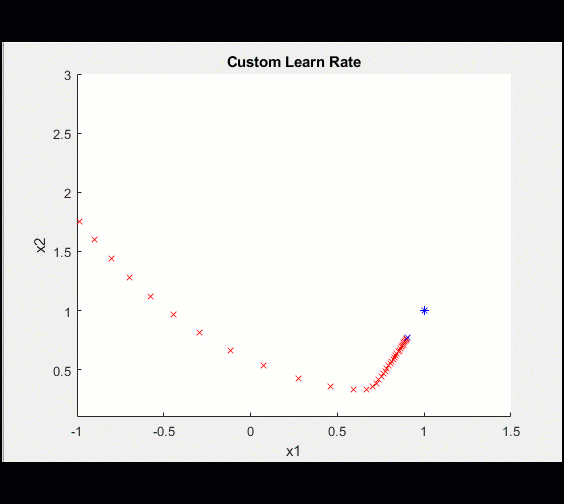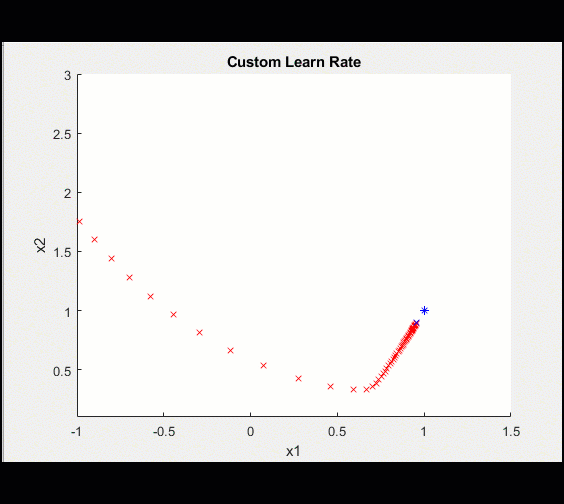 |
- dlfeval
- dlgradient
- dlarray & extractdata
- 自动分化:
- 损失
- 模型梯度
- 学习速率
- dlfeval:也介绍了如何建立rosenbrock方程。
- 更多关于自动分化
- 更多关于解决方案。,有时也称为香蕉函数,它是本例中使用的优化函数
- 全深度学习示例
- 创建自定义深度学习层
|
- 类别:
- 深度学习


另请参阅
-

高级深度学习:第1部分
博客
-
糖尿病性视网膜病变检测
博客
-
-



评论
要留下评论,请点击在这里登录到您的MathWorks帐户或创建一个新帐户。