 克里夫的角落:克里夫硅藻土在数学和计算
克里夫的角落:克里夫硅藻土在数学和计算 MATLAB的博客
MATLAB的博客 史蒂夫与MATLAB图像处理
史蒂夫与MATLAB图像处理 人在仿真软件金宝app
人在仿真软件金宝app 人工智能
人工智能 开发区域
开发区域 斯图尔特的MATLAB视频
斯图尔特的MATLAB视频 在标题后面
在标题后面 文件交换的选择
文件交换的选择 汉斯在物联网
汉斯在物联网 学生休息室
学生休息室 MATLAB社区
MATLAB社区 MATLABユーザーコミュニティー
MATLABユーザーコミュニティー 创业、加速器,和企业家
创业、加速器,和企业家 自治系统
自治系统利用强化学习打乒乓球
在1970年代,乒乓球是一个非常流行的视频游戏。这是一个2 d游戏模拟乒乓球,即你有蝙蝠(矩形)你可以移动垂直并试着打了一个“球”(一个移动的平方)。如果球打游戏的边界框,它像一个台球反弹。如果你错过了球,对手的分数。

单人适应爆发出来后,球有能力摧毁一些街区在屏幕的顶部和蝙蝠移动到屏幕底部的。因此,蝙蝠现在水平而不是垂直移动。
在这篇文章中,我想描述如何教一个AI玩乒乓球的一种变体,只是一个上限,球反弹回来。
正如书名所暗示的,我们将使用强化学习任务。它绝对是多余的在我们的场景中,但是谁在乎!简单的街机游戏是一个美丽的运动场强化学习的第一步。如果你不熟悉RL,看一看这篇简短的指南或这个视频系列这就解释了基本的概念。
大致说来,实现强化学习通常包括这四个步骤:
- 建模环境
- 定义训练方法
- 想出一个奖励函数
- 培训代理
实施,我们将使用强化学习工具箱第一次发布的版本R2019a MATLAB。完整的源代码可以在这里找到:https://github.com/matlab-deep-learning/playing-Pong-with-deep-reinforcement-learning。所以让我们开始吧。
建模环境
这实际上要求最重要的工作是4步骤:你必须实现底层物理,即如果球打游戏或蝙蝠的边界或只是在屏幕上移动。此外,你想想象当前状态(好吧,一个很简单的MATLAB)。强化学习工具箱提供了一种方式来定义自定义环境中基于MATLAB代码或仿真软件模型我们可以利用模型Pong环境。金宝app为此,我们从rl.env继承。MATLABEnvironment and implement the system's behavior.
< rl.env.MATLABEnvironment classdef环境%相应的属性(设置属性的属性)属性%指定并初始化环境的必要属性% X限制球运动XLim = [1]% Y限制球运动YLim = (-1.5 - 1.5)%球的半径BallRadius = 0.04%不变球速度BallVelocity = 2 [2]
整个源代码可以找到的这篇文章。虽然我们很容易想象环境我们没有使用游戏截图作为用于强化学习的信息。这样做会是另一个选项,将接近人类玩家独自依靠视觉信息。但它也会使卷积神经网络需要更多的培训工作。相反,我们对游戏的当前状态进行编码向量我们称之为观察七元素:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 当前的坐标的球 | 球的当前坐标 | 球坐标的变化 | 球坐标的变化 | 坐标的蝙蝠 | 改变坐标的蝙蝠 | 力应用于蝙蝠 |
很容易看到如何捕获所有相关游戏的当前状态的信息。第七个元素(“力量”)可能还需要更详细的解释:
力基本上是一个按比例缩小的版本的行动,即蝙蝠左右移动。这意味着我们反馈代理的最后的动作的观察,引入一些记忆的概念,作为代理可以访问以前的决定。
我们可以从一个随机的初始方向球和模拟,直到球撞到地板上。如果球砸到地板上,游戏就结束了。
定义训练方法
一般来说,训练算法的选择影响操作和观察空间。在我们的例子中,观察(向量和七个元素)和行动空间(标量值)是连续的,这意味着它们可以承担任何浮点数的值在一个特定的范围内。例如,我们限制了行动的范围[1]。同样的,球的x和y位置不允许超过一定的阈值,当球必须留在游戏的边界。
对于本例,我们使用一个DDPG (深决定性策略梯度)代理。名称是指一个特定的训练方法,会有其他的选择。培训本身我们需要两个组件:一个演员和一个评论家。
这个演员
演员决定的行动在任何给定的情况下。在每个时间步,它接收7个观测的环境(如上表所示)和输出一个动作,一个数字1和1之间。这个动作对应蝙蝠向左移动非常快(1),向右(+ 1)(0),与所有可能的中间水平。演员是一个神经网络有三个完全连接层和relu激活与随机值初始化样本来自正态分布。输出比例,使其值介于1和1之间。
评论家
批评家的实例计算期望的奖励是演员在长期的行动基于过去的行动和最后的观察。因此,批评家需要两个输入参数。类似于演员,评论家由几个完全连接层,其次是reLu层。现在,我们还没有谈论任何奖励,但很清楚的是,演员的表现(没有双关)可以很好(没有错过一个球)或坏(并不管理达到一个球)。批评家应该预测长期的结果决定的演员。
我们可以使用deepNetworkDesigner应用程序定义的演员和评论家从图书馆网络通过拖动和连接层。截图中,你可以看到演员网络(左)和评论家网络(正确,注意两个输入路径)。您还可以导出的代码从应用程序以编程方式建立一个网络。

想出一个奖励函数
一般来说,找到合适的奖励函数(这一过程被称为奖励塑造)可能相当棘手。我个人的经验是,这很容易成为一个水槽。有一些最近的结果,提出方法来自动化这个过程。原则上,是推动代理行为是你想要的行为:你奖励“好”行为(如击球),你惩罚“坏”行为(如丢失的球)。
从本质上讲,代理试图积累尽可能多的奖励和潜在的神经网络的参数相应地不断更新,只要游戏没有达到终端状态(球下降)。
加强打击的行为我们奖励代理有一个很大的正值当桨击中球。另一方面,我们惩罚‘小姐’行为通过提供一个负的奖励。我们也塑造这个负值通过与球之间的距离成正比,桨的小姐,这鼓励代理的时候靠近球(和最终罢工)当它即将小姐!
培训代理
最后一个步骤非常简单,因为它只是在MATLAB可以归结为一个函数,trainNetwork。然而,培训本身可以花一些时间,根据您的终止条件和可用的硬件(在许多情况下,培训可以在GPU加速的帮助下)。所以拿一杯咖啡,坐下来,放松,而MATLAB显示一个进度包括奖励之和的最后完成一集(即玩游戏直到球打在地板上)。您可以在任何时间和中断使用中间结果或让它运行直到完成。培训将停止时终止准则等事件或特定的奖励值的最大数量。

如果我们手动终止培训处于初期阶段,但代理仍然表现得很笨拙:
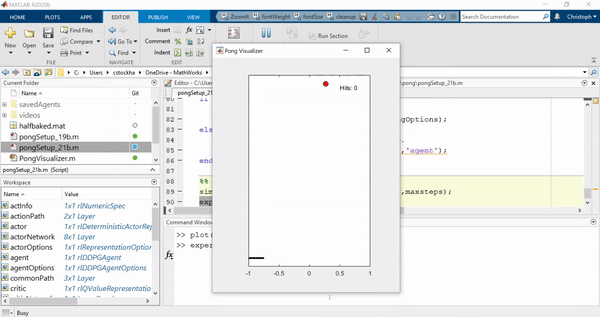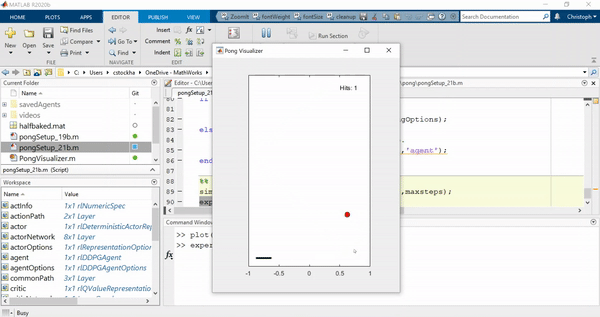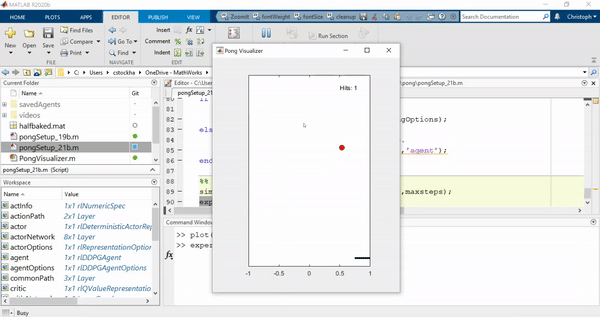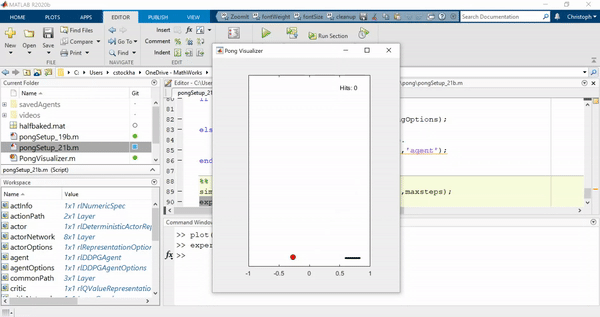
最后,这是训练有素的特工在行动:

结论
显然,您可以轻松地为玩设计没有任何强化学习算法发出难闻的气味有效,它是用大锤砸开坚果——这是有趣的。然而,人们用强化学习解决实际问题,这种问题很难或者根本不容易处理的传统方法。
此外,许多人现有的仿真软件模型精确描述复杂的环境和很容易被用来第金宝app一步——建模环境。客户应用程序使用的视频可以找到强化学习在这里。当然,这些问题更复杂,通常需要更多的时间来每一步在上面的工作流。
然而,好消息是,原理是一样的,您仍然可以利用相同的技术上面我们使用!
现在轮到你了:有没有你正在考虑的领域应用强化学习吗?请让我在评论中了解到。
- 类别:
- 深度学习








评论
要发表评论,请点击此处登录到您的MathWorks帐户或创建一个新帐户。