 克利夫角:克利夫·莫尔谈数学和计算机
克利夫角:克利夫·莫尔谈数学和计算机 Loren在Matlab的艺术上
Loren在Matlab的艺术上 史蒂夫在图像处理与matlab
史蒂夫在图像处理与matlab Simulin金宝appk上的家伙
Simulin金宝appk上的家伙 深度学习
深度学习 开发人员区域
开发人员区域 Stuart的Matlab视频
Stuart的Matlab视频 在头条线后面
在头条线后面 本周的文件交换选择
本周的文件交换选择 汉斯在某种程度上
汉斯在某种程度上 学生休息室
学生休息室 初创企业、加速器和企业家
初创企业、加速器和企业家 MATLAB社区
MATLAB社区 matlabユーザーコミュニティー
matlabユーザーコミュニティー深度学习系统中的偏见
讨论电影,编码偏见
这篇文章来自希瑟·戈尔(@ heather.codes.)回顾她的经验观看编码偏见,呼吁为每个人阅读而采取行动。编码偏见是最近提名批评者的选择奖,以获得最佳科学纪录片,并于4月5日来到Netflixai可能是错误的。我们知道这一点,我们中的一些人可能太好了!但有时候错误分类可以影响某人的生命。我们不是在谈论猫/狗误解或不幸的Netflix推荐。申请人可能被错误地忽视了作业或被指控犯罪的无辜者。这些是整个电影中的一些例子和主题编码的偏见,一部广受好评的纪录片,突出了发现快乐Buolamwini包括面部识别和文本在内的人工智能系统的偏见,以及这种偏见的影响。在她的案例中,她正在研究的面部识别系统并没有认出她,直到她戴上白色面具。

MathWorks最近举办了一个公共筛选和带电影制作人的问答,Shalini Kantayya.,作为我们的一部分Neurips Meetups.(是的,一家软件公司举办了一部南部的电影筛查!)世界上几百几百加入我们了解这一重要主题并参与讨论。在这篇文章中,我们将摘要来自电影的积分,讨论偏见,以及深度学习界(和社会)的影响。我们还将指出如何帮助和了解更多信息。
观看电影“编码偏见”(从希瑟的桌子)在我们的虚拟神经网络会议
什么是“偏见”?
也许你听说过这个术语,从数学上讲,从社会或一般意义上讲。它们的定义非常相似。例如,术语"信号偏差”或“浮点偏见用于描述添加偏移量(例如常量值)。换句话说,数学偏差是来自中立位置的位移,就像一般意义一样。
那么,电影中的背景是什么?两个都。欢乐发现,用于训练面部识别模型的数据集主要由白人男性组成。当她扩大研究来调查更多商业系统时,数据集包括80%较轻的皮肤人。算法错误地分配了较暗皮肤的女性的面孔,错误率高达37%。然而,较轻的皮肤男性的错误率不超过1%。[1] |
 |
让我们仔细想想:不平衡的数据偏见这个算法。有了更多的数据,它被训练得更准确地分类白色面孔(与黑色面孔的比例不成比例)。此外,算法随后被用于执法和其他系统,这些系统已经对黑脸有偏见,当算法本身有偏见时,进一步复合。
这不仅仅是图像,而且还可以导致偏见的其他类型的数据。例如,许多文本和NLP模型还使用已经发现的大数据集,这些数据集基于收集数据的群体类似地展示偏差。[2]
|
编码偏见突出了许多有害后果的例子,特别是在民权方面。人工智能系统主要应用于警察部门、求职网站和金融系统。美国至少有一半的州允许警察在他们的驾照照片数据库中搜索匹配的照片。然而,无辜的人被逮捕,他们的生活永远改变了。这部电影讨论了无数错误逮捕的例子。一个突出的例子是一个14岁的男孩,因为假匹配被警察拦下并搜查。 |

我们可以继续,但要知道还有希望!基于乔伊的研究和倡导,包括创立算法司法联盟,几家大型科技公司停止销售他们的工具,向执法部门销售和许多美国国家停产面部识别方案。
我们学到了什么?
这部电影有很多教训,特别是我们在深入学习领域工作的人。一个重要的一点是考虑训练数据!使用转移学习是非常受欢迎的,适应研究人员掠夺的模型。但我们应该包括在使用之前对培训数据进行调查,特别是根据您构建的系统类型。
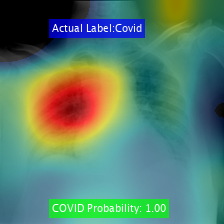
此外,在社区上有研究解释性以及模型构建的更多透明度。当然,用于此的算法通常不会考虑人类/社会偏见,但它们可能有助于识别数据和结果中的问题、模式和趋势。例如,像LIME、grade - cam和Occlusion Sensitivity这样的算法可以让你深入了解一个深度学习网络,以及为什么这个网络会选择一个特定的选项。例如,下面的图片(来自最近的帖子深度学习可视化),显示来自梯度加权类激活映射(gradient-weighted class activation mapping)的结果,突出显示对分类影响更大的图像部分。

Grad-CAM识别影响分类的图像部分的结果。
但我们还必须退后一步并像人类那样思考(让机器负责!)我们可以更清楚培训型号的培训方式,数据集是哪些数据集,并在自己的研究中传达这些东西。更清楚算法如何使用IRL(在现实生活中)以及您工作的含义。
我们能做什么?
这部电影在一个充满希望的呼唤到我们所有人都可以作为个人帮助。基本上主题是意识,教育和行动。教育对我们来说是一个重要的人,因为你们所以很多人才刚刚开始深入学习和AI。自从您在此帖子结束时,您就会知道,并在您追溯到您的生活中有一些背景知识。这是第一步!
 |
为了做得更多,我们可以通过下面的链接学习并采取行动。
|
参考
[1]“性别色调:商业性别分类中的交叉准确性差异”由Joy Buolamwini和Timnit Gebru,Machine学习研究程序,2018年2月http://proceings.mlr.cress/v81/buolamwini18a/buolamwini18a.pdf. [2]艾米莉M. Bender,Timnit Gebru,Angelina McMillan-Major和Shmargaret Shmitchell。2021.关于随机鹦鹉的危险:可以太大的语言模型?在公平,问责制和透明度会议上(Facct'21),3月3日至10日,2021年,虚拟事件,加拿大。ACM,Newyork,NY,USA,14页。https://doi.org/10.1145/3442188.3445922https://faculty.washington.edu/ebender/papers/Stochastic_Parrots.pdf [3]编码偏见教育讨论指南https://static1.squarespace.com/static/5eb23eee707c5356dea97eaa/t/5ffe4ff872238a5c80e4020b/1610502147093/CODED_Educational_Guide_Final.pdf [4]//www.tatmou.com/discovery/Interpetability.html. [5]https://blogs.mathworks.com/deep-learning/2019/06/20/ xplainable-ai/- 类别:
- 深度学习





评论
要发表评论,请点击这里登录您的MathWorks帐户或创建新的。