 克利夫角:克利夫Moler的数学和计算
克利夫角:克利夫Moler的数学和计算 Loren在Matlab的艺术上
Loren在Matlab的艺术上 史蒂夫在图像处理与matlab
史蒂夫在图像处理与matlab Simulin金宝appk上的家伙
Simulin金宝appk上的家伙 深度学习
深度学习 开发区域
开发区域 斯图尔特的MATLAB视频
斯图尔特的MATLAB视频 在标题后面
在标题后面 本周的文件交换选择
本周的文件交换选择 汉斯在物联网
汉斯在物联网 赛车休息室
赛车休息室 初创公司,加速器和企业家
初创公司,加速器和企业家 MATLAB社区
MATLAB社区 MATLABユーザーコミュニティー
MATLABユーザーコミュニティー在噪音中寻找信息
对于今天的博客,我想提出一个问题:
假设您有很多代表了非常随机的数据,但这非常小的“告诉”将数据分化为两种不同的类 - 例如嘈杂的基因组群中的单一核苷酸缺陷。(好的,也许这是一个伸展。)但是在一个嘈杂的数据集中给出了一个单一的信息“位”,你怎么找到讲述的?
内容
让我们创建(和可视化)一个建立问题的数据集
首先,创建10,000个随机20 x 20矩阵。
RNG(0);n = 10000;sz = [20 20];a = rand(sz(1),sz(2),1,n);
创建一个“告诉”:
现在,我们将转换1个随机选择的像素被修改为Class1 / Class2“告诉”或“指示灯”:
OrmanInformationalElement = RANDI(SZ(1)* SZ(2))[ROWINDTRUE,COLINDTRUE] = IND2SUB(大小(a),randominformationelement);%在那个随机选择的位置,我们将设置一半的图像%有一个随机值,而另一半有一个不同的随机值%值:%级别1:class1val = rand(1);为了i = 1:n/2 a(rowIndTrue, colIndTrue, ii) = class1Val;%1结尾%第2级:class2val = rand(1);为了i = n/2 + 1:n a(rowIndTrue, colIndTrue, ii) = class2Val;% 0.5结尾%我们将创建分类标签来跟踪“Class”:标签= [repmat(分类(“class1”),n / 2,1);repmat(分类(分类)“class2”),n / 2,1)];摘要(标签)
OrmanInformationalElement = 193类5000类别2 5000
让我们看看每个班级的三个......你能发现讲述吗?
数字('名称'那“样本”);inds = [1:3,n-2:n];layout = tiledlayout(2,3,“TileSpacing”那'袖珍的');Ax = gobjects(2, 3);印第安纳州= 1;为了II = INDS AX(IND)= NELTTILE(布局);imshow(a(:,:,ii))持有上如果title == 2'1'那'颜色'那'r'那'字体大小',18);elseifIND == 5标题('2'那'颜色'那'r'那'字体大小',18);结尾IND = IND + 1;结尾

现在怎么样?
为了plot(ax(ii), colIndTrue, rowIndTrue,“gs”那'Markersize',12,“线宽”, 2)结尾linkaxes (ax)组(ax,'xlim', (0.85 * colIndTrue, 1.15 * colIndTrue),......“ylim”,[0.85 * ROWINDTRUE,1.15 * ROWINDTRUE])

tell在哪里?
这里的目标是找到一种检测信息位的模型 - 从而将矩阵分成两个类。感知读者可能意识到,可以简单地查看矩阵的最小标准偏差,例如,找到信息位:
数字('名称'那'找到了!')stda = std(a,1,ndims(a));imshow(stda,[]);标题('标准偏差')检测=查找(stda == min(stda(:)));[RowindDeted,ColinDdetected] = Ind2Sub(尺寸(a),检测);抓住上情节(colIndTrue rowIndTrue,“gs”那'Markersize',12,“线宽”,4)情节(ColindDetected,RowindDetected,'rs'那'Markersize',12,......“线宽”, 1.5);如果检测== randomInformationElement检测到=“真的”;别的检测到=“错误的”;结尾标题(“信息位=”+检测+“?(”+检测到+“)”)

混淆
很明显这有点做作。我们可以通过混淆的方式改变一些值来进一步混淆它。例如:
为了confounder = randi(sz(1) * sz(2));[rowInd, colInd] = ind2sub(size(a), confounder);R =兰德(1);为了II = 1:2:n a(rowind,colind,ii)= r;结尾R =兰德(1);为了II = 2:2:n a(rowind,colind,ii)= r;结尾结尾数字('名称'那“混淆”)stda = std(a,1,ndims(a));imshow(stda,[]);标题('标准偏差')检测=查找(stda == min(stda(:)));[RowindDeted,ColinDdetected] = Ind2Sub(尺寸(a),检测);抓住上情节(colIndTrue rowIndTrue,“gs”那'Markersize',12,“线宽”,4)情节(ColindDetected,RowindDetected,'rs'那'Markersize',12,......“线宽”, 1.5);如果检测== randomInformationElement检测到=“真的”;别的检测到=“错误的”;结尾标题(“信息位=”+检测+“?(”+检测到+“)”)

现在的信息更加模糊了!
一个挑战:
尝试使用“古典机器学习”(CML)模型找到此信息位,利用像这样的工具ClassificationLearner应用程序.根据我的经验,classificationLearner提供的模型将会产生很长一段时间(数小时,甚至!),而且没有一个模型会收敛到超过50%。也就是说,模型将是100%无用的!(我把这个问题留给读者。但我将发送一件MATLAB t恤,谁与我分享一个模型训练与应用程序,可靠地解决这个问题的第一个人!)
约束!
为什么CML模型会失败?一句话:约束!通常,要创建图像分类器,我们可能首先使用“袋功能”.然后,使用这些聚合的功能,我们可以培训“图像类别分类器”。(这TrainimageCategoryClassifier功能使得琐碎的工作。)请注意使用Bagoffeature隐含地计算上网功能,这TrainimageCategoryClassifier隐含地训练多牌支持向量机(SVM)金宝app.功能表征像素之间的关系,并且目前尚不清楚SUR或SVM适合手头的任务。即使您使用了非默认探测器,提取器和分类器,您仍将具有约束模型!
进入深度学习
相比之下,深入学习,相对不受约束;我们不必讲述模型是如何看待的。相反,我们可以指定一个“网络架构”并提供一堆“地面真理”,让计算机弄清楚要查找的内容!
例如,在这里,我们刚刚为分类图像的最简单的“典型”网络架构创建:
sizeOfKernel = [5, 5];numberOfFilters = 20;类= 2;图层= [ImageInputLayer([SZ(1)Sz(2)1])卷积2dlayer(sizeofkernel,numberoffilters,'名称'那“conv”)Rublayer MaxPooling2Dlayer(2,'走吧'2) fullyConnectedLayer(类'名称'那'fc') softmaxLayer classiationlayer ()];
“Triad”的“卷积,释放,汇集”层在设计用于图像分析的深度学习网络中非常常见。但请注意,我们没有过度约束模型只考虑特定的特征或模型类型;我们简单地告诉模型计算20个5x5卷积。更重要的是,我们甚至没有指定要查找的模式(卷积内核)。
因此,让我们创建验证和测试集,并训练模型
创建一个验证集将帮助我们确保模型不会过拟合,测试集将帮助我们在训练后评估模型。
%首先,验证集:Inds = 1:100:size(a, 4);validationData = a(:,:,Inds);ValidationLabels =标签(INDS);%从培训集中删除验证标签:A (:,:,:, inds) = [];标签(INDS)= [];%现在测试集:Inds = 1:100:size(a, 4);testSet = a(:,:,:, inds);testLabels =标签(第1);A (:,:,:, inds) = [];标签(INDS)= [];%……指定一些培训选项:minibatchsize = 100;选项=培训选项(“亚当”那......'italllearnrate',0.005,......'maxepochs',1000,......“MiniBatchSize”miniBatchSize,......'plots'那'培训 - 进步'那......'vightationdata',{ValidationData,ValidationLabels},......'验证职业'10,......'验证景点',30,......“OutputFcn”@(信息)stopIfAccuracyNotImproving(信息,50));%……和培训!net = trainNetwork(a,标签,图层,选项);
单个GPU培训。

哇……
在不到半分钟的时间里,这个简单的“深度”学习模型似乎收敛到了95%的准确率!
predictedLabels = net.classify (testSet);ind = randi(size(testset,ndims(a)));net.classify(testset(:,:,:,Ind));togglefig('混乱矩阵')m = confusionchart(testlabels,predightlabels);testAccuracy = sum(predigedlabels == testlabels)/ numel(testlabels)
testaccuracy = 0.94949.
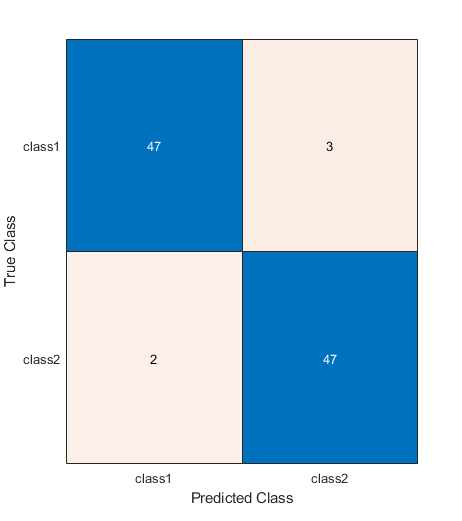
这是怎么回事?
这很有用,但它也是令人费解的:如果模型已经找到了“告诉”是(它必须已经完成的那个,或者它不能超过50%),那么为什么不是100%准确?
该答案在于网络架构。我们使用的典型卷积神经网络(CNN)层的“三合会”包括池层。由于我们的信息是单一的,因此汇集是“涂抹”信息!如果我们删除该图层怎么办?
图层= [ImageInputLayer([SZ(1)Sz(2)1])卷积2dlayer(sizeofkernel,numberoffilters,'名称'那“conv”) reluLayer fullyConnectedLayer (2'名称'那'fc') softmaxLayer classiationlayer ()];net = trainNetwork(a,标签,图层,选项);predictedLabels = net.classify (testSet);testAccuracy = sum(predigedlabels == testlabels)/ numel(testlabels)
单个GPU培训。

甜蜜的!
大约10秒到100%的准确性!这有助于我们了解一些层次正在做的事情,以及为什么我们需要将网络量身定制到手头的任务!(请注意,我们也可以删除Relu层;它既不有帮助也没有阻碍该模型。)
伟大的!但我们可以确定位置告诉吗?
是的!“深梦”是你的朋友!
频道= [1,2];第= 4;%完全连接i = DeepDreamImage(网络,图层,频道,'Pyramidlevels',1);togglefig('深梦');子图(1,2,1)Channel1Image = i(:,:,:1);imshow(channel1image);标题('深梦通道1(1级)')子图(1,2,2)Channel2Image = i(:,:,2);imshow(channel2image);标题(“深梦频道2(一级)”) [rmax, cmax] = find(channel1Image == min(channel1Image(:)));%或[rmax,cmax] = find(channel2image == max(channel2image(:));fprintf('目标:\ t \ trowind =%i; \ tcolind =%i; \ ndetection:\ trow =%i; \ t \ tcol =%i \ n',rowindtrue,colindtrue,rmax,cmax)
| =============================================== ||迭代|激活|金字塔级别|||力量||| =============================================== | | 1 | 1.55 | 1 | | 2 | 265.54 | 1 | | 3 | 533.66 | 1 | | 4 | 804.17 | 1 | | 5 | 1075.66 | 1 | | 6 | 1347.60 | 1 | | 7 | 1619.17 | 1 | | 8 | 1891.03 | 1 | | 9 | 2163.16 | 1 | | 10 | 2435.12 | 1 | |==============================================| TARGET: RowInd = 13; ColInd = 10; DETECTION: Row = 13; Col = 10

最后的评论
当我们谈论深度学习时,“深度”通常是指网络架构中的层数。这型模型在这方面并不是很深处。但我们做过实施端到端学习(即直接从数据中学习)——这是深度学习的另一个标志。
我希望你能找到这个有趣的,即使它有点是有点的。欢迎您的意见!
- 类别:
- 深度学习


也可以看看
-

深度学习图像分类
博客
-
创建一个简单的DAG网络
博客
-

场景分类使用深度学习
博客






注释
请点击留下评论在这里登录到你的MathWorks帐户或创建一个新的。