 克莱夫之角:克莱夫·莫勒谈数学与计算
克莱夫之角:克莱夫·莫勒谈数学与计算 MATLAB博客
MATLAB博客 史蒂夫的图像处理与MATLAB
史蒂夫的图像处理与MATLAB Simulin金宝appk上的家伙
Simulin金宝appk上的家伙 人工智能
人工智能 开发区域
开发区域 Stuart的MATLAB视频
Stuart的MATLAB视频 头条背后
头条背后 文件交换选择的一周
文件交换选择的一周 汉斯谈物联网
汉斯谈物联网 学生休息室
学生休息室 MATLAB社区
MATLAB社区 Matlab
Matlab 创业公司、加速器和企业家
创业公司、加速器和企业家 自治系统
自治系统
测量GPU性能
今天我欢迎客座博主回来本Tordoff谁之前在这里写过如何在GPU上生成一个分形.他将在下面继续这个GPU主题,看看如何测量GPU的性能。
内容
测量GPU性能
无论你是在考虑给自己买一个新的强大的GPU,还是刚刚花钱买了一个,你都可能会问自己它有多快。在本文中,我将描述并尝试测量GPU的一些关键性能特征。这应该会让你对使用GPU相对于CPU的优点有一些了解,也会让你对不同GPU之间的比较有一些了解。
有大量的基准测试可供选择,所以我把范围缩小到三个测试:
- 我们将数据发送到GPU或再次读取数据的速度有多快?
- GPU内核读取和写入数据的速度有多快?
- GPU的计算速度有多快?
在测量了这些之后,我可以将我的GPU与其他GPU进行比较。
如何衡量时间
在下面的部分中,每个测试都会重复多次,以允许在我的PC上进行其他活动和第一次调用开销。我只保留最小的结果,因为外部因素只会减慢执行速度。
为了得到准确的计时数字,我使用等待(gpu)以确保GPU在停止计时器之前已经完成工作。在普通代码中不应该这样做。为了获得最佳性能,你想让GPU继续工作,而CPU继续处理其他事情。MATLAB自动处理所需的任何同步。
我把代码放入一个函数中,这样变量就有了作用域。这可以在内存性能方面产生很大的不同,因为MATLAB能够更好地重用数组。
函数gpu_benchmarking
gpu = gpuDevice();流(“我有一个%s的GPU。”gpu.Name)
我有一个特斯拉C2075 GPU。
测试主机/GPU带宽
第一个测试试图测量数据发送到GPU和读取GPU的速度。由于GPU插入PCI总线,这在很大程度上取决于您的PCI总线有多好,以及有多少其他东西正在使用它。然而,度量中也包含了一些开销,特别是函数调用开销和数组分配时间。因为这些存在于任何“真实世界”的GPU使用中,所以包含这些是合理的。
在以下测试中,使用gpuArray函数并将其分配/返回给主机内存收集.创建数组时使用uint8每个元素都是一个字节。
请注意,本测试中使用的PCI express v2的理论带宽为每通道0.5GB/s。对于NVIDIA的Tesla卡使用的16通道插槽(PCIe2 x16),理论上可以提供8GB/s。
size = power(2,12:26);重复次数= 10;sendTimes = inf(size(size));gatherTimes = inf(size(size));为Ii =1: nummel (sizes) data = randi([0 255], sizes(Ii), 1,“uint8”);为Rr =1:repeat timer = tic();gdata = gpuArray(data);等待(gpu);sendTimes(ii) = min(sendTimes(ii), toc(timer));Timer = tic();dat2 = collect (gdata);% #好< NASGU >gatherTimes(ii) = min(gatherTimes(ii), toc(timer));结束结束sendBandwidth = (size ./sendTimes)/1e9;[maxSendBandwidth, maxsenddidx] = max(sendBandwidth);流(“峰值发送速度为%g GB/s\n”,maxSendBandwidth) gatherBandwidth = (size ./gatherTimes)/1e9;[maxGatherBandwidth,maxGatherIdx] = max(gatherBandwidth);流(“峰值采集速度为%g GB/s\n”马克斯(gatherBandwidth))
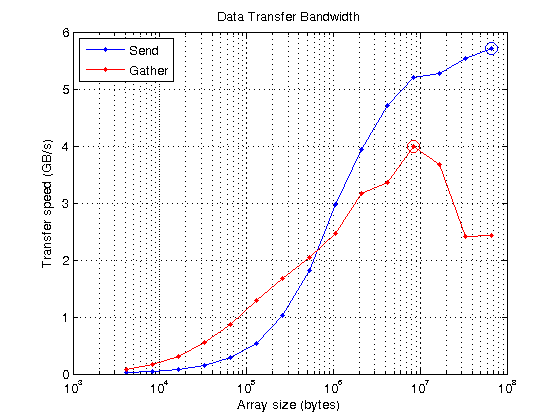
发送速度峰值为5.70217 GB/s,收集速度峰值为3.99077 GB/s
在该图中,您可以看到在每种情况下达到峰值的位置(圈起)。在小尺寸时,PCI总线的带宽是无关的,因为开销占主导地位。在较大的尺寸PCI总线是限制因素和曲线变平。由于PC和我所有的gpu都使用相同的PCI v2,所以比较不同的gpu没有什么优点。不过,PCI v3硬件已经开始出现,所以将来可能会变得更有趣。
持有从semilogx(大小、sendBandwidth“b -”, size, gatherBandwidth,' r . - ')举行在maxSendBandwidth semilogx(大小(maxSendIdx),“bo - - - - - -”,“MarkerSize”10);maxGatherBandwidth semilogx(大小(maxGatherIdx),“ro - - - - - -”,“MarkerSize”10);网格在标题(“数据传输带宽”)包含('数组大小(字节)') ylabel (“传输速度(GB/s)”)传说(“发送”,“收集”,“位置”,“西北”)
测试内存密集型操作
您可能希望执行的许多操作对数组的每个元素只进行很少的计算,因此主要是由从内存中获取数据或将其写回所花费的时间所决定的。像ONES, zero, NAN, TRUE这样的函数只写它们的输出,而像TRANSPOSE, TRIL/TRIU这样的函数既读又写,但不计算。即使是像PLUS、MINUS、MTIMES这样简单的运算符,每个元素的计算量也很少,它们只受内存访问速度的限制。
我可以使用一个简单的PLUS操作来测量我的机器读取和写入内存的速度。这包括读取每个双精度数字(即输入的每个元素8个字节),添加1,然后再次将其写出来(即每个元素另外8个字节)。
sizeOfDouble = 8;readWritesPerElement = 2;memoryTimesGPU = inf(size(size));为ii=1: numelement = sizes(ii)/sizeOfDouble;data = gpuArray。0 (numElements 1“双”);为Rr =1:repeat timer = tic();为Jj =1:100 data = data + 1;结束等待(gpu);memoryTimesGPU(ii) = min(memoryTimesGPU(ii), toc(timer)/100);结束结束memoryBandwidth = readWritesPerElement*(size ./memoryTimesGPU)/1e9;[maxBWGPU, maxBWIdxGPU] = max(memoryBandwidth);流(“GPU的峰值读/写速度为%g GB/s\n”maxBWGPU)
GPU的峰值读写速度为110.993 GB/s
为了知道这是否快,我将其与在CPU上运行的相同代码进行了比较。但是,请注意,CPU有几个级别的缓存和一些奇怪的东西,比如“先读后写”,这可能会使结果看起来有点奇怪。对于我的PC来说,主存的理论带宽是32GB/s,所以高于这个带宽可能是由于高效的缓存。
memoryTimesHost = inf(size(size));为ii=1: numelement = sizes(ii)/sizeOfDouble;为rr=1:重复hostData = 0 (numElements,1);Timer = tic();为jj=1:10 00 hostData = hostData + 1;结束memoryTimesHost(ii) = min(memoryTimesHost(ii), toc(timer)/100);结束结束memoryBandwidthHost = 2*(size ./memoryTimesHost)/1e9;[maxBWHost, maxBWHostIdx] = max(memoryBandwidthHost);流('主机上的峰值写速度为%g GB/s\n'maxBWHost)%显示CPU和GPU结果。持有从semilogx(大小、memoryBandwidth“b -”,…大小、memoryBandwidthHost“k -”)举行在maxBWGPU semilogx(大小(maxBWIdxGPU),“bo - - - - - -”,“MarkerSize”10);maxBWHost semilogx(大小(maxBWHostIdx),“ko - - - - - -”,“MarkerSize”10);网格在标题(“读/写带宽”)包含('数组大小(字节)') ylabel (“速度(GB / s)”)传说(“阅读+写作(GPU)”,“阅读+写作(主机)”,“位置”,“西北”)
主机写速度峰值为44.6868 GB/s
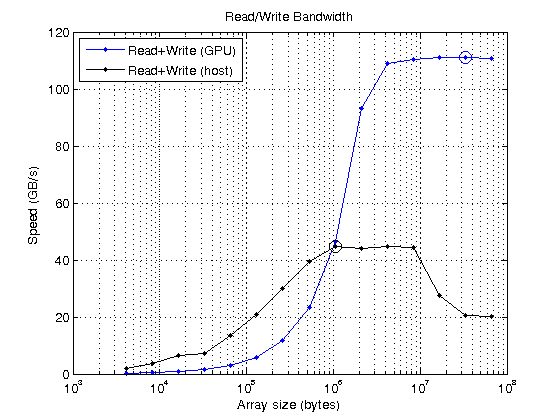
很明显,gpu读取和写入内存的速度比从主机获取数据的速度要快得多。因此,在编写代码时,必须尽量减少主机- gpu或gpu -主机传输的次数。你必须将数据传输到GPU,然后在GPU上尽可能多地处理它,只有在你绝对需要的时候才把它带回主机。如果可以的话,最好在GPU上创建数据。
测试计算密集型计算
对于计算占主导地位的操作,内存速度就不那么重要了。在这种情况下,您可能对执行计算的速度更感兴趣。计算性能的一个很好的测试是矩阵-矩阵乘法。对于两个NxN矩阵的乘法,浮点计算的总数为
$ flops (n) = 2n ^3 - n ^2
如上所述,我在主机PC和GPU上计时此操作,以查看它们的相对处理能力:
尺寸=权力(2,12:2:24);N = sqrt(size);mmTimesHost = inf(size(size));mmTimesGPU = inf(size(size));为ii=1: nummel (size) A = rand(N(ii), N(ii));B = rand(N(ii), N(ii));首先在主机上执行为Rr =1:repeat timer = tic();C = a * b;% #好< NASGU >mmTimesHost(ii) = min(mmTimesHost(ii), toc(timer));结束%现在在GPU上A = gpuArray(A);B = gpuArray(B);为Rr =1:repeat timer = tic();C = a * b;% #好< NASGU >等待(gpu);mmTimesGPU(ii) = min(mmTimesGPU(ii), toc(timer));结束结束mmGFlopsHost = (2*N.)^3 - n ^2)./mmTimesHost/1e9;[maxGFlopsHost,maxGFlopsHostIdx] = max(mmGFlopsHost);mmGFlopsGPU = (2*N。^3 - n ^2)./mmTimesGPU/1e9;[maxGFlopsGPU,maxGFlopsGPUIdx] = max(mmGFlopsGPU);流('峰值计算率:%1.1f GFLOPS(主机),%1.1f GFLOPS (GPU)\n',…maxGFlopsHost maxGFlopsGPU)
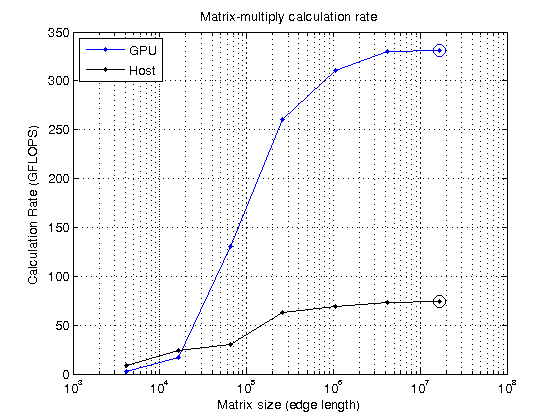
峰值计算速率:73.7 GFLOPS(主机),330.9 GFLOPS (GPU)
现在把它画出来,看看峰值在哪里。
持有从semilogx(大小、mmGFlopsGPU“b -”, size, mmGFlopsHost,“k -”)举行在maxGFlopsGPU semilogx(大小(maxGFlopsGPUIdx),“bo - - - - - -”,“MarkerSize”10);maxGFlopsHost semilogx(大小(maxGFlopsHostIdx),“ko - - - - - -”,“MarkerSize”10);网格在标题(“矩阵乘法计算速率”)包含(“矩阵大小(边长度)”) ylabel (“计算速率(GFLOPS)”)传说(“图形”,“主机”,“位置”,“西北”)
比较gpu
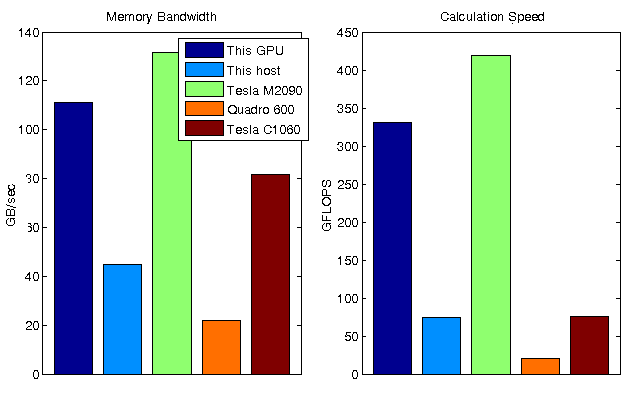
在测量了内存带宽和计算性能之后,我现在可以将我的GPU与其他GPU进行比较。之前我在几个不同的gpu上运行了这些测试,并将结果存储在一个数据文件中。
离线=加载(“gpuBenchmarkResults.mat”);名称= [“这GPU”“这主机”offline.names];ioData = [maxBWGPU maxBWHost offline.memoryBandwidth];calcData = [maxGFlopsGPU maxGFlopsHost offline.mmGFlops];次要情节(1、2、1)栏([ioData(,)、南(元素个数(ioData), 1))”,“分组”);集(gca),“Xlim”, [0.6 . 1.4],“XTick”, []);传奇(名字{}):标题(内存带宽的), ylabel (“GB /秒”)次要情节(1、2、2)栏([calcData(,)、南(元素个数(calcData), 1))”,“分组”);集(gca),“Xlim”, [0.6 . 1.4],“XTick”, []);标题(的计算速度), ylabel (“GFLOPS”)设置(gcf“位置”得到(gcf“位置”)+[0 0 300 0]);
结论
这些测试揭示了gpu的一些行为:
- 从主机内存到GPU内存的传输速度相对较慢,在我的情况下<6GB/s。
- 一个好的GPU读/写内存的速度比主机PC读/写内存的速度快得多。
- 在数据足够大的情况下,gpu执行计算的速度比主机PC快得多,在我的情况下是主机PC的四倍多。
在每个测试中值得注意的是,您需要相当大的数组来完全饱和GPU,无论是受内存还是计算的限制。当一次处理数百万个元素时,您可以从GPU中获得最大的收益。
如果您对GPU性能的更详细基准测试感兴趣,请查看GPUBench在MATLAB中心文件交换.
如果您对这些测量有任何疑问,或者发现我做错了什么或可以改进的地方,请给我留言在这里.







コメント
コメントを残すには,ここをクリックしてMathWorksアカウントにサインインするか新しいMathWorksアカウントを作成します。