 克利夫角:克利夫·莫尔谈数学和计算机
克利夫角:克利夫·莫尔谈数学和计算机 洛伦谈MATLAB的艺术
洛伦谈MATLAB的艺术 MATLAB在图像处理中的应用
MATLAB在图像处理中的应用 Simulin金宝appk上的家伙
Simulin金宝appk上的家伙 深度学习
深度学习 开发区域
开发区域 斯图尔特的MATLAB视频
斯图尔特的MATLAB视频 在标题后面
在标题后面 本周文件交换精选
本周文件交换精选 汉斯在物联网
汉斯在物联网 学生休息室
学生休息室 创业公司、加速器和企业家
创业公司、加速器和企业家 MATLAB社区
MATLAB社区 MATLABユーザーコミュニティー
MATLABユーザーコミュニティー测量GPU性能
今天我欢迎回来的嘉宾博客本·托多夫谁之前在这里写过如何在GPU上生成分形。他将继续下面的GPU主题,了解如何衡量GPU的性能。
目录
测量GPU性能
无论你是在考虑给自己买一个新的结实的GPU,还是刚刚花了一大笔钱买了一个,你都可能会问自己它有多快。在这篇文章中,我将描述并尝试测量GPU的一些关键性能特征。这将让你更深入地了解使用GPU而不是CPU和al的相对优势因此,我们可以了解不同的GPU之间的比较情况。
有大量的基准测试可供选择,因此我将其缩小为三个测试:
- 我们发送数据到GPU或再次读取数据的速度有多快?
- GPU内核读写数据的速度有多快?
- GPU的计算速度有多快?
在测量完这些之后,我可以将我的GPU与其他GPU进行比较。
如何衡量时间
在下面的部分中,每个测试都会重复多次,以允许在我的电脑上进行其他活动以及第一次呼叫的开销。我尽量减少结果,因为外部因素只会减慢执行速度。
为了得到准确的计时数字等待(gpu)以确保GPU在停止计时器前已经完成工作。在普通代码中不应该这样做。为了获得最佳性能,你想让GPU继续工作,同时CPU继续处理其他事情。MATLAB自动处理任何需要的同步。
我已经将代码放入一个函数中,这样变量就有了作用域。这可以在内存性能方面产生很大的差异,因为MATLAB能够更好地重用数组。
作用gpu_基准测试
gpu=gpuDevice();fprintf('我有一个%s GPU。\n'gpu.Name)
我有一个特斯拉C2075 GPU。
测试主机/GPU带宽
第一个测试尝试测量数据发送到GPU和从GPU读取的速度。由于GPU插入PCI总线,这在很大程度上取决于PCI总线的性能以及使用它的其他设备的数量。但是,测量中还包括一些开销,特别是函数调用开销和array分配时间。因为这些都存在于GPU的任何“真实世界”使用中,所以包含这些是合理的。
在以下测试中,使用gpuArray函数,并使用聚集.使用uint8所以每个元素都是一个字节。
请注意,本测试中使用的PCI express v2的理论带宽为每通道0.5GB/s。对于NVIDIA的特斯拉卡使用的16通道插槽(PCIe2 x16),理论带宽为8GB/s。
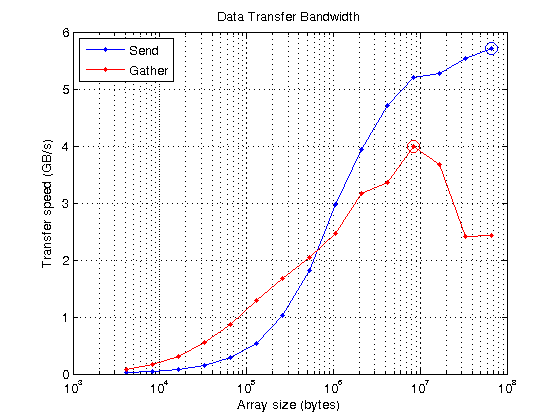
size = power(2, 12:26);重复= 10;sendTimes =正(大小(尺寸));gatherTimes =正(大小(尺寸));对于ii=1:numel(尺寸)数据=randi([0 255],尺寸(ii),1,‘uint8’);对于rr=1:重复计时器=tic();gdata=gpuArray(数据);等待(gpu);发送时间(ii)=分钟(发送时间(ii),toc(计时器));计时器=tic();数据2=gather(gdata);%#好的gatherTimes(ii)=分钟(gatherTimes(ii),toc(计时器));终止终止发送带宽=(大小/发送次数)/1e9;[maxSendBandwidth,maxSendIdx]=最大(发送带宽);fprintf('峰值发送速度为%g GB/s\n',maxSendBandwidth) gatherBandwidth = (size ./gatherTimes)/1e9;[maxGatherBandwidth, maxGatherIdx] = max (gatherBandwidth);流('峰值收集速度为%g GB/s\n',最大(带宽))
峰值发送速度为5.70217 GB/s峰值采集速度为3.99077 GB/s
在图上,您可以看到在每种情况下达到峰值的位置(圆圈)。在小尺寸的情况下,PCI总线的带宽无关紧要,因为开销占主导地位。在较大尺寸时,PCI总线是限制因素,曲线变平。由于PC和我使用的所有GPU都使用相同的PCI v2,因此比较不同的GPU没有什么好处。不过,PCI v3硬件已经开始出现,所以将来可能会变得更有趣。
持有关semilogx(大小、sendBandwidth“b.-”、大小、gatherBandwidth' r . - ')持有在…上semilogx(大小(maxSendIdx)、maxSendBandwidth、,“博——”,“MarkerSize”10);maxGatherBandwidth semilogx(大小(maxGatherIdx),“ro - - - - - -”,“MarkerSize”,10);网格在…上标题(“数据传输带宽”)xlabel(的数组大小(字节))伊拉贝尔(传输速度(GB / s)的)传说(“发送”,“聚集”,“位置”,“西北”)
测试内存密集型操作
您可能想要执行的许多操作只对数组的每个元素进行很少的计算,因此主要取决于从内存中取出数据或将数据写回所需的时间。像ONES, ZEROS, NAN, TRUE这样的函数只写它们的输出,而像TRANSPOSE, TRIL/TRIU这样的函数既能读也能写,但不做计算。即使像PLUS, MINUS, MTIMES这样简单的运算符对每个元素的计算也很少,它们只受内存访问速度的限制。
我可以使用一个简单的加号操作来测量我的机器读写内存的速度。这包括读取每个双精度数字(即,输入的每个元素8字节),添加一个,然后再次写入(即,每个元素另外8字节)。
sizeOfDouble = 8;readWritesPerElement = 2;memoryTimesGPU =正(大小(尺寸));对于ii=1:numel(大小)numElements=size(ii)/sizeOfDouble;data=gpuArray.zero(numElements,1,“双人”);对于rr=1:重复定时器=tic();对于Jj =1:100 data = data + 1;终止等待(gpu);memoryTimesGPU(ii) = min(memoryTimesGPU(ii), toc(timer)/100);终止终止memoryBandwidth=读写关联*(大小。/memoryTimesGPU)/1e9;[maxBWGPU,maxBWIdxGPU]=最大值(memoryBandwidth);fprintf('GPU上的峰值读/写速度为%g GB/s\n',maxBWGPU)
GPU上的峰值读/写速度为110.993 GB/s
为了知道这是否快速,我将其与CPU上运行的相同代码进行比较。但是,请注意,CPU有几个级别的缓存和一些奇怪的功能,如“先读后写”这可能会让结果看起来有点奇怪。对于我的电脑来说,理论上的主内存带宽是32GB/s,所以高于这一速度可能是由于高效缓存。
MemoryTimeHost=inf(大小);对于ii=1:numel(尺寸)numElements=尺寸(ii)/sizeOfDouble;对于rr=1:重复hostData = 0 (numElements,1);计时器=抽搐();对于jj=1:100 hostData=hostData+1;终止MemoryTimeHost(ii)=最小值(MemoryTimeHost(ii),toc(计时器)/100;终止终止memoryBandwidthHost=2*(大小。/MemoryTimeHost)/1e9;[maxBWHost,maxBWHostIdx]=max(memoryBandwidthHost);fprintf('主机上的峰值写速度为%g GB/s\n',maxBWHost)%绘制CPU和GPU结果。持有关semilogx(尺寸、内存带宽、,“b.-”,...大小、memoryBandwidthHost“k.-”)持有在…上maxBWGPU semilogx(大小(maxBWIdxGPU),“博——”,“MarkerSize”10);maxBWHost semilogx(大小(maxBWHostIdx),“ko-”,“MarkerSize”,10);网格在…上标题(“读/写带宽”)xlabel(的数组大小(字节))伊拉贝尔(“速度(GB/s)”)传说('读+写(GPU)',“阅读+写作(主机)”,“位置”,“西北”)
主机写速度峰值为44.6868 GB/s
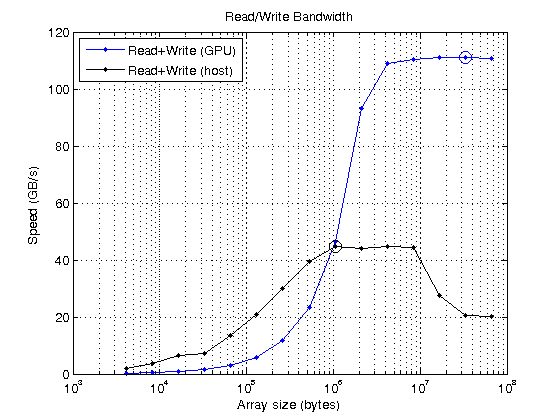
很明显,gpu读写内存的速度要比从主机获取数据的速度快得多。因此,在编写代码时,应尽量减少主机与gpu或gpu与主机的传输次数。你必须将数据传输到GPU,然后在GPU上尽可能多地使用它,只有在绝对需要的时候才把它带回主机。如果可以的话,在GPU上创建数据就更好了。
测试计算密集型计算
对于计算占主导地位的操作,内存速度就不那么重要了。在这种情况下,您可能更感兴趣的是计算执行得有多快。一个很好的计算性能测试是矩阵-矩阵乘法。对于两个NxN矩阵相乘,浮点运算的总数为
$ flops (n) = 2n ^3 - n ^2
如上所述,我在主机PC和GPU上计时,看看它们的相对处理能力:
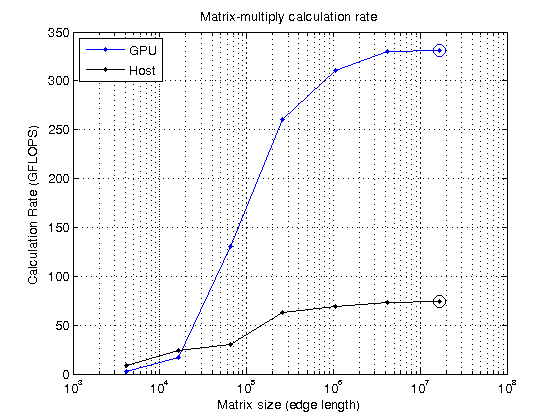
size=power(2,12:2:24);N=sqrt(size);mmtimeshhost=inf(size(size));mmTimesGPU=inf(size(size));对于A = rand(N(ii), N(ii));B = rand(N(ii), N(ii));%首先在主机上执行此操作对于rr=1:重复定时器=tic();C=A*B;%#好的mmTimesHost(ii)=最小值(mmTimesHost(ii),toc(计时器));终止%现在在GPU上A=gpuArray(A);B=gpuArray(B);对于rr=1:重复定时器=tic();C=A*B;%#好的 等待(gpu);mmTimesGPU(ii) = min(mmTimesGPU(ii), toc(timer));终止终止mmGFlopsHost = (2 * N。^ 3 - n ^ 2)。/ mmTimesHost / 1 e9;[maxGFlopsHost, maxGFlopsHostIdx] = max (mmGFlopsHost);mmGFlopsGPU = (2 * N。^ 3 - n ^ 2)。/ mmTimesGPU / 1 e9;[maxGFlopsGPU, maxGFlopsGPUIdx] = max (mmGFlopsGPU);流('峰值计算率:%1.1f GFLOPS(主机),%1.1f GFLOPS (GPU)\n',...maxGFlopsHost,maxGFlopsGPU)
峰值计算速率:73.7 GFLOPS(主机),330.9 GFLOPS (GPU)
现在绘制图,看看达到峰值的位置。
持有关semilogx(大小、mmGFlopsGPU“b.-”,尺寸,mmGFlopsHost,“k.-”)持有在…上maxGFlopsGPU semilogx(大小(maxGFlopsGPUIdx),“博——”,“MarkerSize”,10);半对数x(尺寸(maxGFlopsHostIdx),maxGFlopsHost,“ko-”,“MarkerSize”,10);网格在…上标题(“矩阵乘法计算率”)xlabel('矩阵大小(边长)')伊拉贝尔(“计算率(GFLOPS)”)传说(“图形”,“主持人”,“位置”,“西北”)
比较gpu
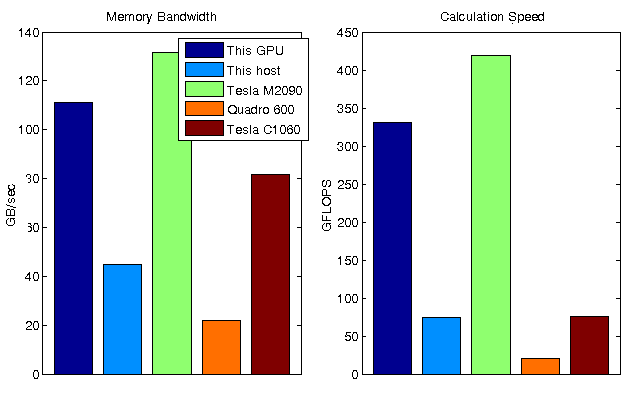
在测量了内存带宽和计算性能之后,我现在可以将我的GPU与其他GPU进行比较。之前,我在两个不同的GPU上运行了这些测试,并将结果存储在数据文件中。
离线=负载(“gpuBenchmarkResults.mat”); 姓名=[“这个GPU”“这位主人”脱机.names];ioData=[maxBWGPU maxBWHost offline.memoryBandwidth];calcData=[maxGFlopsGPU MaxGFlopst offline.mmGFlops];子批(1,2,1)条([ioData(:),nan(numel(ioData),1)],“分组”);集(gca,“Xlim”(0.6 - 1.4),“克斯蒂克”[]);传奇(名字{}):标题(“内存带宽”),伊拉贝尔(“GB/秒”)子地块(1,2,2)bar([calcData(:),nan(numel(calcData),1)],“分组”);集(gca,“Xlim”(0.6 - 1.4),“克斯蒂克”, [] ); 头衔(“计算速度”),伊拉贝尔(“GFLOPS”)集合(gcf,“位置”,get(gcf,“位置”)+[0 0 300 0]);
结论
这些测试揭示了GPU的一些行为:
- 从主机内存到GPU内存的传输相对较慢,在我的情况下小于6GB/s。
- 一个好的GPU读/写内存的速度比主机PC读/写内存的速度快得多。
- 如果有足够大的数据,gpu的计算速度要比主机快得多,在我的情况下要快四倍多。
每次测试中都会注意到,你需要相当大的阵列来完全饱和你的GPU,无论是受内存还是计算的限制。当你同时处理数百万个元素时,你会从GPU中得到最大的收获。
如果您对GPU性能的更详细基准感兴趣,请查看GPUBench上MATLAB中央文件交换.
如果你对这些测量方法有疑问,或者发现了我做错的地方或需要改进的地方,请给我留言在这里.


另见
-

使用GPU进行图像处理
博客
-

GPU的基准测试
博客





评论
要留下评论,请点击在这里登录到您的MathWorks帐户或创建一个新帐户。