fitPosterior
拟合支持向量机分类器的后验概率金宝app
语法
描述
ScoreSVMModel= fitPosterior (SVMModel)ScoreSVMModel包含两类学习的最优得分-后验概率变换函数。有关详细信息,请参见算法.
[另外,返回最优的得分后验概率转换函数参数。ScoreSVMModel,ScoreTransform) = fitPosterior (SVMModel)
[使用由一个或多个名称-值对参数指定的附加选项。例如,您可以指定折叠的数量或坚守样品的比例。ScoreSVMModel,ScoreTransform) = fitPosterior (SVMModel,名称,值)
例子
SVM分类器样本内后验概率的估计
加载电离层数据集。该数据集有34个预测器和351个雷达返回的二进制响应,或坏(“b”)或好(‘g’).
负载<年代pan style="color:#A020F0">电离层
训练支持向量机分金宝app类器。将数据标准化并指定‘g’是积极类。
SVMModel = fitcsvm (X, Y,<年代pan style="color:#A020F0">“类名”, {<年代pan style="color:#A020F0">“b”,<年代pan style="color:#A020F0">‘g’},<年代pan style="color:#A020F0">“标准化”,真正的);
SVMModel是一个ClassificationSVM分类器。
拟合最优得分-后验概率变换函数。
rng (1);<年代pan style="color:#228B22">%的再现性ScoreSVMModel = fitPosterior (SVMModel)
ScoreSVMModel = ClassificationSVM ResponseName: 'Y' CategoricalPredictors: [] ClassNames: {'b' ' '} ScoreTransform: '@(S)sigmoid(S,-9.482415e-01,-1.217768e-01)' NumObservations: 351 Alpha: [90x1 double] Bias: -0.1342 KernelParameters: [1x1 struct] Mu:[0.8917 0 0.6413 0.0444 0.6011 0.1159 0.5501…Sigma:[0.3112 0 0.4977 0.4414 0.5199 0.4608 0.4927…][351x1 double] ConvergenceInfo: [1x1 struct] IsSupportVector: [35金宝app1x1 logical] Solver: 'SMO'属性,方法
由于类是不可分的,分数变换函数(ScoreSVMModel。ScoreTransform)为s型函数。
估计训练数据的分数和正类后验概率。显示前10个观察的结果。
(标签,分数)= resubPredict (SVMModel);[~, postProbs] = resubPredict (ScoreSVMModel);表(Y(1:10),标签(1:10),分数(1:10),2),postProbs (1:10), 2),<年代pan style="color:#A020F0">“VariableNames”,<年代pan style="color:#0000FF">...{<年代pan style="color:#A020F0">“TrueLabel”,<年代pan style="color:#A020F0">“PredictedLabel”,<年代pan style="color:#A020F0">“分数”,<年代pan style="color:#A020F0">“PosteriorProbability”})
ans =<年代pan class="emphasis">10×4表TrueLabel PredictedLabel得分PosteriorProbability _________ ______________ _______ ____________________ {' 1.4862 - 0.82216 g’}{‘g’}{b} {b} -1.0004 - 0.30431{‘g’}{‘g’}1.8686 - 0.86918 {b} {b} -2.6462 - 0.084133{‘g’}{‘g’}1.2808 - 0.79188 {b} {b} -1.4618 - 0.22022{‘g’}{‘g’}2.1673 - 0.89815 {b} {b} -5.7093 - 0.0050066{‘g’}{‘g’}2.47970.92224 {'b'} {'b'} -2.7811 0.074784
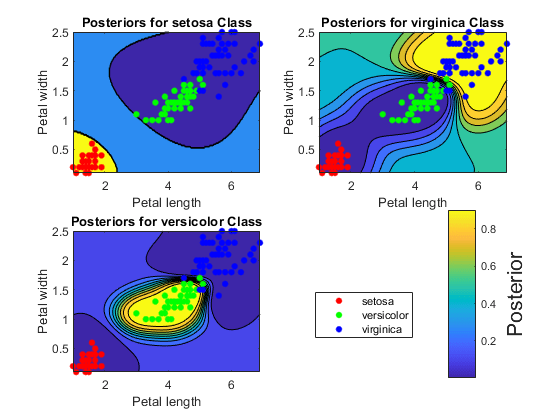
绘制多个类别的后验概率轮廓
通过一对所有(OVA)分类过程训练多类SVM分类器,然后绘制每类的概率轮廓。要直接实现OVA,请参见fitcecoc.
载入费雪的虹膜数据集。使用花瓣的长度和宽度作为预测数据。
负载<年代pan style="color:#A020F0">fisheririsX =量(:,3:4);Y =物种;
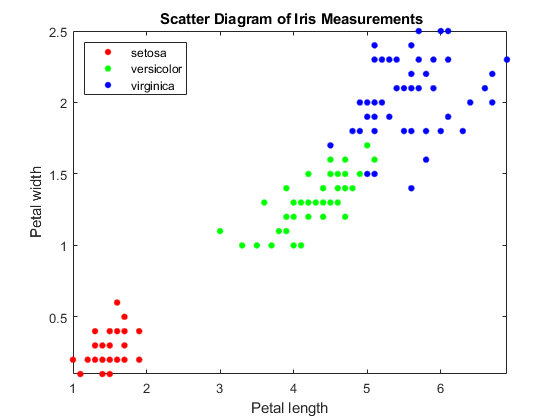
检查数据的散点图。
图gscatter (X (: 1), (:, 2), Y);标题(<年代pan style="color:#A020F0">'{\bf虹膜测量散点图}');包含(<年代pan style="color:#A020F0">“花瓣长度”);ylabel (<年代pan style="color:#A020F0">“花瓣宽度”);传奇(<年代pan style="color:#A020F0">“位置”,<年代pan style="color:#A020F0">“西北”);轴<年代pan style="color:#A020F0">紧
训练三个二值支持向量机分类器,将每种虹膜类型与其他类型区分开来。假设一个径向基函数是每一个合适的核,并允许算法选择一个核尺度。定义类顺序。
一会= {<年代pan style="color:#A020F0">“setosa”;<年代pan style="color:#A020F0">“virginica”;<年代pan style="color:#A020F0">“多色的”};numClasses =大小(类名,1);第1 =细胞(3,1);<年代pan style="color:#228B22">%预先配置SVMModel =细胞(3,1);rng (1);<年代pan style="color:#228B22">%的再现性为j = 1:numClasses inds{j} = strcmp(Y,classNames{j});<年代pan style="color:#228B22">%卵子分类SVMModel {j} = fitcsvm (X,第1 {j},<年代pan style="color:#A020F0">“类名”(虚假的真实),<年代pan style="color:#0000FF">...“标准化”,真的,<年代pan style="color:#A020F0">“KernelFunction”,<年代pan style="color:#A020F0">“rbf”,<年代pan style="color:#A020F0">“KernelScale”,<年代pan style="color:#A020F0">“汽车”);<年代pan style="color:#0000FF">结束
fitcsvm使用一种启发式过程,涉及到子抽样来计算核尺度的值。
为每个分类器拟合最优的得分-后验概率变换函数。
为j = 1:numClasses SVMModel{j} = fitPosterior(SVMModel{j});<年代pan style="color:#0000FF">结束
警告:类是完全分离的。最优积分后验变换是一个阶跃函数。
定义一个网格来绘制后验概率轮廓。估计网格上每个分类器的后验概率。
d = 0.02;[x1Grid, x2Grid] = meshgrid (min (X (: 1)): d:马克斯(X (: 1))<年代pan style="color:#0000FF">...min (X (:, 2)): d:马克斯(X (:, 2)));xGrid = [x1Grid (:), x2Grid (:));后=细胞(3,1);<年代pan style="color:#0000FF">为j = 1:numClasses [~,posterior{j}] = predict(SVMModel{j},xGrid);<年代pan style="color:#0000FF">结束
对于每个SVM分类器,在数据的散点图下绘制后验概率轮廓。
图h = 0 (numClasses + 1,1);<年代pan style="color:#228B22">%预分配图形句柄为j = 1:numClasses subplot(2,2,j) contourf(x1Grid,x2Grid,重塑(posterior{j}(:,2),size(x1Grid,1),size(x1Grid,2));持有<年代pan style="color:#A020F0">在h (1: numClasses) = gscatter (X (: 1), (:, 2), Y);标题(sprintf (<年代pan style="color:#A020F0">' %s类的后验'{j}),类名);包含(<年代pan style="color:#A020F0">“花瓣长度”);ylabel (<年代pan style="color:#A020F0">“花瓣宽度”);传说<年代pan style="color:#A020F0">从轴<年代pan style="color:#A020F0">紧持有<年代pan style="color:#A020F0">从结束h(numClasses + 1) = colorbar(<年代pan style="color:#A020F0">“位置”,<年代pan style="color:#A020F0">“EastOutside”,<年代pan style="color:#0000FF">...“位置”, [[0.8, 0.1, 0.05, 0.4]]);集(get (h (numClasses + 1),<年代pan style="color:#A020F0">“YLabel”),<年代pan style="color:#A020F0">“字符串”,<年代pan style="color:#A020F0">“后”,<年代pan style="color:#A020F0">“字形大小”16);传奇(h (1: numClasses),<年代pan style="color:#A020F0">“位置”, 0.6, 0.2, 0.1, 0.1);
用抵抗交叉验证拟合最优后验概率函数
在训练支持向量机分类器后,估计得分-后验概率转换函数。在估计过程中使用交叉验证以减少偏差,并比较10倍交叉验证和坚持交叉验证的运行时间。
加载电离层数据集。
负载<年代pan style="color:#A020F0">电离层
训练SVM分类器。将数据标准化并指定‘g’是积极类。
SVMModel = fitcsvm (X, Y,<年代pan style="color:#A020F0">“类名”, {<年代pan style="color:#A020F0">“b”,<年代pan style="color:#A020F0">‘g’},<年代pan style="color:#A020F0">“标准化”,真正的);
SVMModel是一个ClassificationSVM分类器。
拟合最优得分-后验概率变换函数。比较使用10倍交叉验证(默认)和10%坚持测试样本的运行时间。
rng (1);<年代pan style="color:#228B22">%的再现性抽搐;<年代pan style="color:#228B22">启动秒表SVMModel_10FCV = fitPosterior (SVMModel);toc<年代pan style="color:#228B22">%停止秒表并显示运行时间
运行时间为1.190378秒。
抽搐;SVMModel_HO = fitPosterior (SVMModel,<年代pan style="color:#A020F0">“坚持”, 0.10);toc
运行时间为0.158474秒。
尽管这两个运行时间都很短,因为数据集相对较小,SVMModel_HO拟合积分变换函数的速度比SVMModel_10FCV.您可以指定holdout交叉验证(而不是默认的10倍交叉验证),以减少较大数据集的运行时间。
输入参数
输出参数
更多关于
提示
这个过程描述了一种预测正类后验概率的方法。
通过传递数据来训练SVM分类器
fitcsvm.结果是一个训练的SVM分类器,如SVMModel,用来存储数据。软件设置分数变换函数属性(SVMModel。ScoreTransformation)没有一个.通过训练的SVM分类器
SVMModel来fitSVMPosterior或fitPosterior.结果,如:ScoreSVMModel,与训练的SVM分类器相同SVMModel,除了软件集ScoreSVMModel。ScoreTransformation的最优积分变换函数。通过预测器数据矩阵和包含最优分数变换函数的训练SVM分类器(
ScoreSVMModel)预测.的第二个输出参数中的第二列预测存储预测器数据矩阵每一行对应的正类后验概率。如果你跳过第二步,那么
预测返回正的类别得分,而不是正的类别后验概率。
在拟合后验概率之后,您可以生成C/ c++代码来预测新数据的标签。生成C/ c++代码需要<年代pan class="entity">MATLAB<年代up>®编码器™.有关详细信息,请参见代码生成简介.
算法
该软件利用支持向量机分类器拟合出合适的得分-后验概率转换函数SVMModel通过使用存储的预测数据进行10倍交叉验证(SVMModel。X)和类标签(SVMModel。Y)[1].变换函数计算观察被归入正类的后验概率(SVMModel.Classnames (2)).
如果您重新估计得分后验概率转换函数,也就是说,如果您将一个SVM分类器传递给fitPosterior或fitSVMPosterior和它的ScoreTransform属性是不没有一个,则软件:
显示一个警告
将原来的转换函数重置为
“没有”在估计新的情况之前
选择功能
你也可以用fitSVMPosterior.这个函数类似于fitPosterior,但它更广泛,因为它接受更广泛的SVM分类器类型。
参考文献
[1] Platt, J.“支持向量机的概率输出和与正则似然方法的比较。”金宝app大裕度分类器的进展.麻省理工学院出版社,2000年,61-74页。
另请参阅
ClassificationSVM|<年代pan itemscope itemtype="//www.tatmou.com/help/schema/MathWorksDocPage/SeeAlso" itemprop="seealso">预测|<年代pan itemscope itemtype="//www.tatmou.com/help/schema/MathWorksDocPage/SeeAlso" itemprop="seealso">fitSVMPosterior|<年代pan itemscope itemtype="//www.tatmou.com/help/schema/MathWorksDocPage/SeeAlso" itemprop="seealso">fitcsvm
选择网站
选择一个网站,在那里获得翻译的内容,并看到当地的活动和优惠。根据您的位置,我们建议您选择:<年代trong class="recommended-country">.
选择<年代pan class="recommended-country">网站你也可以从以下列表中选择一个网站:
