分类VM
金宝app支持向量机(SVM)用于单级和二进制分类
描述
分类VM是一个金宝app支持向量机(SVM)分类器为一个班和两个班的学习。训练有素的分类VM分类器存储训练数据、参数值、先验概率、支持向量和算法实现信息。使用这些分类器执行任务,例如将分数拟合到后验概率变换函数(参见金宝appFitleDosterior.)和预测新数据的标签(见预测).
创造
创建一个分类VM通过使用fitcsvm..
属性
对象的功能
契约 |
减少机器学习模型的规模 |
compareHoldout |
使用新数据比较两个分类模型的精度 |
crossval |
交叉验证机器学习模型 |
discard金宝appSupportVectors |
丢弃线性支持向量金宝app机分类器的支持向量 |
边缘 |
查找支持向量机(SVM)分类器的分类边金宝app |
FitleDosterior. |
支持向量机(SVM)分类器的拟合后验概率金宝app |
incrementalLearner |
将二值分类支持向量机模型转换为增量学习器金宝app |
损失 |
寻找支持向量机(SVM)分类器的分类误差金宝app |
利润 |
查找支持向量机(SVM)分类器的分类边距金宝app |
partialDependence |
计算部分依赖 |
局部依赖 |
创建部分依赖图(PDP)和个人条件期望图(ICE) |
预测 |
使用支持向量机分类器对观测数据进行分类金宝app |
resubEdge |
Resubstitution分类边缘 |
酸橙 |
局部可解释的模型不可知解释(LIME) |
resubLoss |
Resubstitution分类损失 |
重新提交 |
Resubstitution分类保证金 |
resubPredict |
使用训练的分类器对训练数据进行分类 |
的简历 |
恢复训练支持向量机分类器金宝app |
沙普利 |
沙普利值 |
testckfold |
通过重复交叉验证比较两种分类模型的准确性 |
例子
训练支持向量机分类器
载入费雪的虹膜数据集。去掉萼片的长度和宽度以及所有观察到的刚毛鸢尾。
负载渔民第1 = ~ strcmp(物种,“塞托萨”);X = MEAS(INDS,3:4);Y =物种(INDS);
使用处理后的数据集训练支持向量机分类器。
SVMModel = fitcsvm (X, y)
svmmodel = classificationsvm contractename:'y'pationoricalpricictors:[] classnames:{versicolor''virginica'} scoreTransform:'none'numobservations:100个字母:[24x1 double]偏置:-14.4149内核参数:[1x1 struct] boxconstraints:[100x1DOUBLE] CONFORGENGEINFO:[1x1 struct] iss金宝appupportVector:[100x1逻辑]求解器:'smo'属性,方法
SVMModel是训练有素的分类VM分类器。显示的属性SVMModel.例如,要确定类的顺序,可以使用点符号。
classOrder = SVMModel。一会
classOrder =2x1电池{“癣”}{' virginica '}
头等舱('versicolor')是否定类,而第二个(“维吉尼亚”)是积极类。属性可以在训练期间更改类的顺序'classnames'名称-值对的论点。
绘制数据散点图并圈出支持向量。金宝app
sv = SVMModel.金宝appSupportVectors;图gscatter (X (: 1), (:, 2), y)在情节(sv (: 1), sv (:, 2),'ko',“MarkerSize”,10)传奇('versicolor',“维吉尼亚”,“金宝app支持向量”) 抓住从
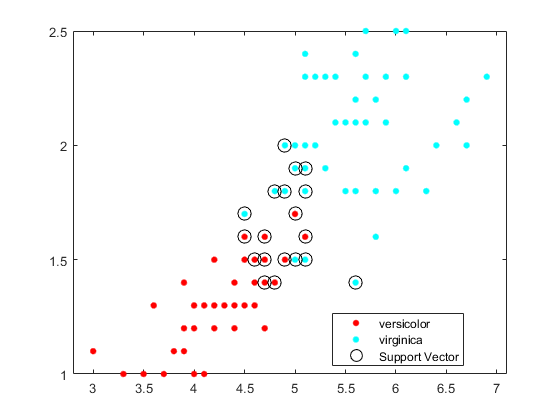
支持向量金宝app是发生在或超出其估计类边界的观察值。
您可以通过在使用期间设置培训期间的框约束来调整边界(以及因此,支持向量的数量)金宝app“BoxConstraint”名称-值对的论点。
训练并交叉验证支持向量机分类器
加载电离层数据集。
负载电离层
列车并交叉验证SVM分类器。标准化预测器数据并指定类的顺序。
RNG(1);%为了再现性cvsvmmodel = fitcsvm(x,y,“标准化”,真的,...'classnames', {“b”,‘g’},“CrossVal”,“上”)
CVSVMModel = ClassificationPartitionedModel CrossValidatedModel: 'SVM' PredictorNames: {1x34 cell} ResponseName: 'Y' NumObservations: 351 KFold: 10 Partition: [1x1 cvpartition] ClassNames: {'b' ' 'g'} ScoreTransform: 'none'属性,方法
CVSVMModel是一个ClassificationPartitionedModel旨在支持向量机分类器。默认情况下,该软件实现10倍交叉验证。
或者,您可以交叉验证一个经过培训的分类VM将它传递给crossval.
使用点符号检查训练镜的一个折叠。
CVSVMModel。训练有素的{1}
ans = CompactClassificationSVM ResponseName: 'Y' CategoricalPredictors: [] ClassNames: {'b' ' 'g'} ScoreTransform: 'none' Alpha: [78x1 double] Bias: -0.2209 KernelParameters: [1x1 struct] Mu: [1x34 double] Sigma: [1x34 double金宝app] SupportVectors: [78x34 double] SupportVectorLabels: [78x1 double]属性,方法
每个褶皱都是一个褶皱CompactClassificationsVM.分类器对90%的数据进行训练。
估计泛化误差。
genError = kfoldLoss (CVSVMModel)
genError = 0.1168
平均而言,泛化误差约为12%。
更多关于
算法
支持向量机二值分类算法的数学公式见金宝app二值分类的支持向量机和理解支持向量机金宝app.
南,<未定义>,空字符向量(''),空字符串(""),<缺失>值表示缺失值。fitcsvm.删除与缺失响应相对应的整行数据。计算总重量(参见下一个子弹),fitcsvm.忽略与至少缺少一个预测器的观测值相对应的任何权重。此操作可能导致平衡类问题中的先验概率不平衡。因此,观测框约束可能不相等boxconstraint..fitcsvm.去除具有零重量或先前概率的观察。对于两类学习,如果你指定代价矩阵 (见
成本),然后软件更新类的先验概率p(见之前) 到pc通过纳入本节中所述的处罚 .具体来说,
fitcsvm.完成这些步骤:计算
规范化pc*更新后的先验概率和是1。
K是班级的数量。
将成本矩阵重置为默认值
从对应于具有零先验概率的类的训练数据中移除观察值。
对两种学习,
fitcsvm.正常化所有观察重量(见权重)求和为1。然后,该函数对归一化权重进行重归一化,使其总和为观测所属类的更新先验概率。即观察的总权重j在课堂上k是wj是观察的规范化重量j;pc,k是更新的课程的现有概率k(见前的子弹)。
对两种学习,
fitcsvm.为训练数据中的每个观测值指定一个方框约束。观察框约束的公式j是n为训练样本量,C0初始框约束(参见
“BoxConstraint”名称-值对参数),以及 是观察的总重量j(见前的子弹)。如果你设置了
“标准化”,真的和“成本”,'事先的',或“重量”名称-值对参数fitcsvm.使用相应的加权平均值和加权标准差对预测值进行标准化。就是,fitcsvm.标准化预测j(xj)使用xjk是观察k(行)预测器j(列)。
假设
p是你在训练数据中期望的和你设置的异常值的比例吗OutlierFraction, p.对于单班学习,软件训练的偏差项为100
p%在训练数据中的观察值中,有1%的得分为负值。软件实现鲁棒学习两级学习。换句话说,该软件试图删除100个
p%优化算法收敛时的观测值。移除的观测值对应于幅度较大的梯度。
如果预测器数据包含分类变量,则软件通常对这些变量使用完全虚拟编码。软件为每个分类变量的每个级别创建一个虚拟变量。
的
预测属性为每个原始预测器变量名存储一个元素。例如,假设有三个预测因子,其中一个是具有三个层次的分类变量。然后预测是包含预测变量原始名称的字符向量的1×3单元格数组。的
ExpandedPredictorNames.属性存储每个预测变量的一个元素,包括虚拟变量。例如,假设有三个预测因子,其中一个是具有三个层次的分类变量。然后ExpandedPredictorNames.是一个包含预测变量和新的虚拟变量名称的字符向量的1 × 5单元格数组。类似地,
bet属性为每个预测器存储一个beta系数,包括虚拟变量。的
金宝appSupportVectors属性存储支持向量的预测值,包括虚拟变量。例如,假设有金宝app米金宝app支持向量和三个预测因子,其中一个是具有三个级别的分类变量。然后金宝appSupportVectors是一个n-by-5矩阵。的
X属性将训练数据存储为原始输入,不包括虚拟变量。当输入是一个表时,X只包含用作预测器的列。
对于表中指定的预测器,如果任何变量包含有序(有序)类别,软件将对这些变量使用有序编码。
的变量k软件创建了有序的关卡k– 1虚拟变量jth虚拟变量是–1对于级别最多j,+1的水平j+ 1通过k.
存储在中的虚拟变量的名称
ExpandedPredictorNames.属性表示具有值的第一级+1.软件商店k– 1虚拟变量的其他预测名称,包括级别2,3,...的名称,k.
所有解算器都执行l1软边缘最小化。
对于单级学习,软件估计拉格朗日乘法器,α1,......,αn,这样
参考
Hastie, T., R. Tibshirani, J. Friedman。统计学习的要素, 第二版。纽约:斯普林斯,2008年。
[2] 斯科尔科夫,B.,J.C.普拉特,J.C.肖夫·泰勒,A.J.斯莫拉和R.C.威廉姆森。“估计高维分布的支持度。”金宝app神经计算机., Vol. 13, no . 7, 2001, pp. 1443-1471。
克里斯汀尼尼,N。c。肖-泰勒。支持向量机和其他基于核的学习方法简介金宝app英国剑桥:剑桥大学出版社,2000年。
[4] Scholkopf, B.和A. Smola。使用内核学习:支持向量机,正规化,优化和超越,金宝app自适应计算和机器学习。麻省剑桥:麻省理工学院出版社,2002年。
扩展功能
您还可以从以下列表中选择一个网站:
