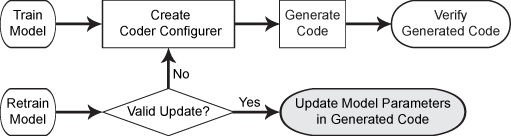
使用支持向量机二进制学习器训练纠错输出码(ECOC)模型,并为该模型创建编码器配置器。使用编码器配置器的属性来指定ECOC模型参数的编码器属性。使用编码器配置器的对象函数生成C代码,用于预测新的预测数据的标签。然后使用不同的设置重新训练模型,并在不重新生成代码的情况下更新生成代码中的参数。
火车模型
载入费雪的虹膜数据集。
创建一个支持向量机二元学习模板,使用高斯核函数和标准化预测数据。
使用模板训练一个多类ECOC模型t.
Mdl是一个Classifiedecoc.对象。
创建编码器配置
为此创建一个编码器配置程序Classifiedecoc.模型通过使用learnerCoderConfigurer.指定预测器数据X.的learnerCoderConfigurer函数使用输入X配置编码器属性预测函数的输入。此外,将输出的数量设置为2,以便生成的代码返回预测函数,它是预测的标号和负的平均二进制损耗。
configurer = ClassificationCocoderConfigurer具有属性:更新输入:BinaryLearners:[1x1 ClassificationsVmcoderConfigurer]之前:[1x1 LearnercoderInput]成本:[1x1 LearnercoderInput]预测输入:X:[1x1 LearnerCoderInput]代码生成参数:NumOutputs:2 OutputFileName:'ClassificationCocModel'属性,方法
配置是一个ClassificationECOCCoderConfigurer对象的编码配置器Classifiedecoc.对象。的可调参数预测和更新:X,二进制书,之前,成本.
指定参数的编码器属性
的编码器属性预测参数(预测器数据和名称-值对参数)“解码”和'二元乐') 和更新参数(SVM学习者的支金宝app持向量)以便您可以将这些参数用作输入参数预测和更新在生成的代码中。
首先,指定的编码器属性X因此,生成的代码接受任何数量的观察。修改SizeVector和VariableDimensions属性。的SizeVector属性指定预测器数据大小的上限,而VariableDimensions属性指定预测器数据的每个维度是具有可变大小还是固定大小。
第一维度的大小是观察的数量。在这种情况下,代码指定大小的上限是正大小是可变的,这意味着X可以有任意数量的观察结果。如果您在生成代码时不知道观察的数量,那么这个规范很方便。
第二维度的大小是预测变量的数量。必须为机器学习模型固定此值。X包含4个预测器,因此SizeVector属性的第二个值必须为4VariableDimensions属性必须错误的.
接下来,修改编码器属性BinaryLoss和解码用来'二元乐'和“解码”生成的代码中的名称-值对参数。显示编码器属性BinaryLoss.
ANS = eNumerateDupput使用属性:value:'铰链'selectionOption:'内置'构建选项:{1x7 Cell} iSononstant:1可调性:0
若要在生成的代码中使用非默认值,必须在生成代码之前指定该值。指定价值的属性BinaryLoss作为“指数”.
ans = EnumeratedInput与属性:值:'指数' SelectedOption: '内置' BuiltInOptions: {1x7 cell} IsConstant: 1可调性:1
如果您在何时修改属性值可调谐性是错误的(逻辑0),软件设置可调谐性来真正的(逻辑1)。
显示编码器属性解码.
ANS = eNumerateDupput使用属性:value:'lockweighted'selectionOption:'内置'内置选项:{'lockweighted'的“丢失”} iSononstant:1可调性:0
指定IsConstant的属性解码作为错误的以便使用。中的所有可用值内置选项在生成的代码中。
ans = EnumeratedInput的属性:值:[1x1 LearnerCoderInput] SelectedOption: 'NonConstant' BuiltInOptions: {' lossweightight ' ' losssbased '} IsConstant: 0可调性:1
软件改变了价值的属性解码到一个LearnercoderInpul.对象,以便两者都可以使用“失去重量”和“lossbased的价值“解码”.此外,软件设置选择选项来'不合作'和可调谐性来真正的.
最后,修改的编码器属性金宝appSupportVectors在二进制书.显示编码器属性金宝appSupportVectors.
ANS = LearnerCoderInput具有属性:Sizevector:[54 4] variabledimensions:[1 0]数据类型:'Double'可调性:1
的默认值VariableDimensions是(真假)因为每个学习者都有不同数量的支持向量。金宝app如果使用新数据或不同的设置重新恢复ECOC型号,则SVM学习者中的支持向量的数量可能会有所不同。金宝app因此,增加支撑载体数量的上限。金宝app
Alpha的SizeVector属性已被修改以满足配置约束。修改了SupportVectorLabels的Si金宝appzeVector属性以满足配置约束。
的编码器属性金宝appSupportVectors,然后软件修改了编码器属性α和金宝appSupportVectorLabels.以满足配置约束。如果修改一个参数的编码器属性需要随后更改其他相关参数以满足配置约束,则软件更改相关参数的编码器属性。
显示编码器配置器。
配置= ClassificationECOCCoderConfigurer属性:更新输入:BinaryLearners:之前[1 x1 ClassificationSVMCoderConfigurer]: [1 x1 LearnerCoderInput]成本:[1 x1 LearnerCoderInput]预测输入:X: [1 x1 LearnerCoderInput] BinaryLoss: [1 x1 EnumeratedInput]解码:[1 x1 EnumeratedInput]代码生成参数:NumOutputs:2 OutputFileName: 'ClassificationECOCModel'属性,方法
现在显示包括BinaryLoss和解码也
生成代码
要生成C/ c++代码,您必须访问配置正确的C/ c++编译器。MATLAB编码器定位并使用一个受支持的、安装的编译器。金宝app您可以使用墨西哥人-设置查看和更改默认编译器。有关详细信息,请参见改变默认的编译器.
为预测和更新ECOC分类模式的功能(Mdl).
generateCode在输出文件夹中创建这些文件:米”、“预测。米”、“更新。米”、“ClassificationECOCModel。代码生成成功。
的Generatecode.函数完成这些操作:
生成生成代码所需的MATLAB文件,包括两个入口点函数预测.M.和update.m为预测和更新的功能Mdl,分别。
创建名为MEX函数ClassificationECOCModel对于两个入口点函数。
控件中创建MEX函数的代码Codegen \ Mex \ ClassificationCocModel文件夹中。
将MEX函数复制到当前文件夹。
验证生成的代码
通过一些预测数据来验证是否是预测功能Mdl和预测函数中返回相同的标签。要在具有多个入口点的MEX函数中调用入口点函数,请将函数名指定为第一个输入参数。因为你指定了“解码”作为调谐输入参数来改变IsConstant属性在生成代码之前,您还需要在对MEX函数的调用中指定它,即使如此“失去重量”默认值是“解码”.
比较标签来label_mex通过使用isequal.
isequal返回逻辑1 (真正的),如果所有输入相等。比较证实了预测功能Mdl和预测函数中返回相同的标签。
NegLoss_mex可能包括与之相比的圆截止差异negl.在这种情况下,比较NegLoss_mex来negl,允许有一个小的公差。
对比证实了negl和NegLoss_mex在公差内是相等的吗1 e-8.
在生成的代码中重新训练模型和更新参数
使用不同的设置重新训练模型。指定“KernelScale”作为“汽车”因此,该软件采用启发式的方法选择合适的比例因子。
使用提取要更新的参数validatedUpdateInputs.该函数检测修改后的模型参数returatedmdl.并验证修改的参数值是否满足参数的编码器属性。
更新生成代码中的参数。
验证生成的代码
的输出比较预测功能returatedmdl.到了输出预测函数。
对比证实了标签和label_mex是相等的,negl和NegLoss_mex在公差范围内是相等的。