预测
使用分类树预测标签
描述
输入参数
输出参数
例子
使用分类树预测标签
检查训练中遗漏的数据集中的几行预测。
载入费雪的虹膜数据集。
负载fisheriris
将数据分成训练集(50%)和验证集(50%)。
1) n =大小(量;rng (1)%的再现性idxTrn = false (n, 1);idxTrn (randsample (n,圆(0.5 * n))) = true;%训练集逻辑索引idxVal = idxTrn == false;%验证设置逻辑索引
使用训练集生长分类树。
Mdl = fitctree(量(idxTrn:),物种(idxTrn));
预测验证数据的标签。计算错误分类的观察结果的数量。
标签=预测(Mdl量(idxVal:));标签(randsample(元素个数(标签),5))显示几个预测的标签
ans =5 x1细胞{' setosa}{‘setosa}{‘setosa}{‘virginica}{“癣”}
numMisclass =总和(~ strcmp(标签,物种(idxVal)))
numMisclass = 3
该软件将三个样本外的观测结果分类错误。
用分类树估计类后验概率
载入费雪的虹膜数据集。
负载fisheriris
将数据分成训练集(50%)和验证集(50%)。
1) n =大小(量;rng (1)%的再现性idxTrn = false (n, 1);idxTrn (randsample (n,圆(0.5 * n))) = true;%训练集逻辑索引idxVal = idxTrn == false;%验证设置逻辑索引
使用训练集生成分类树,然后查看它。
Mdl = fitctree(量(idxTrn:),物种(idxTrn));视图(Mdl,“模式”,“图”)
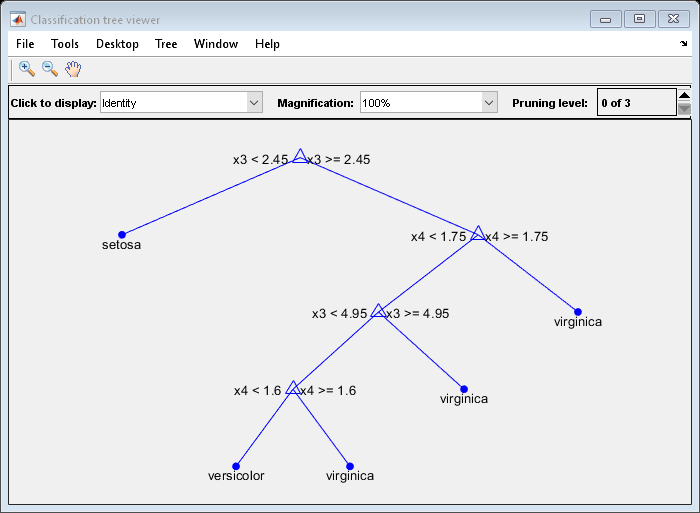
结果树有四个层次。
使用修剪到级别1和3的子树估计测试集的后验概率。
[~,后]=预测(Mdl量(idxVal:)“子树”3 [1]);Mdl。ClassNames
ans =3 x1细胞{'setosa'} {'versicolor'} {'virginica'}
后(randsample(大小(后,1),5),:,:),...显示几个后验概率
ans = ans (:: 1) = 1.0000 0 0 0 0 0 0 0 0 1.0000 1.0000 1.0000 0.8571 - 0.1429 ans (:,: 2) = 0.3733 0.3200 0.3067 0.3733 0.3200 0.3067 0.3733 0.3200 0.3067 0.3733 0.3200 0.3067 0.3733 0.3200 0.3067
的元素后为类后验概率:
行对应于验证集中的观察值。
列对应于中列出的类
Mdl。ClassNames.页面对应于子树。
被修剪到级别1的子树比被修剪到级别3(即根节点)的子树更确定其预测。
更多关于
分数(树)
对于树木,分数叶节点分类的后验概率为该节点分类的后验概率。在一个节点上分类的后验概率是导致该分类的节点的训练序列的数量,除以导致该节点的训练序列的数量。
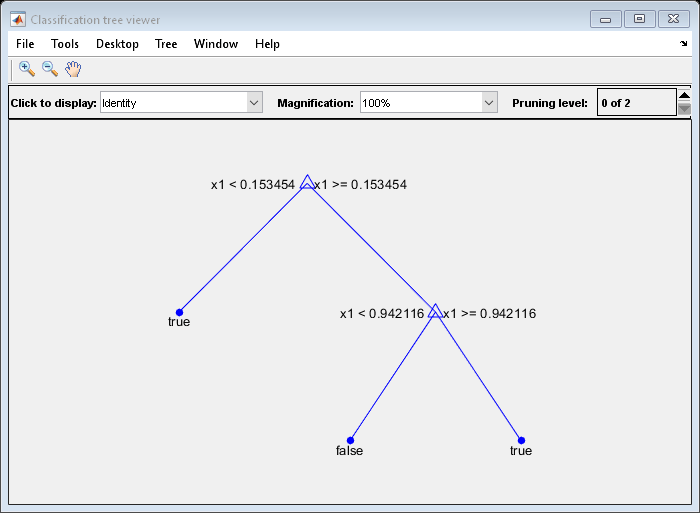
例如,考虑对预测器进行分类X作为真正的当X<0.15或X>0.95,X是假的。
生成100个随机点并进行分类:
rng (0,“旋风”)%的再现性X =兰德(100 1);Y = (abs(X - .55) > .4);树= fitctree (X, Y);视图(树,“模式”,“图”)
修剪树:
tree1 =修剪(树,“水平”1);视图(tree1,“模式”,“图”)
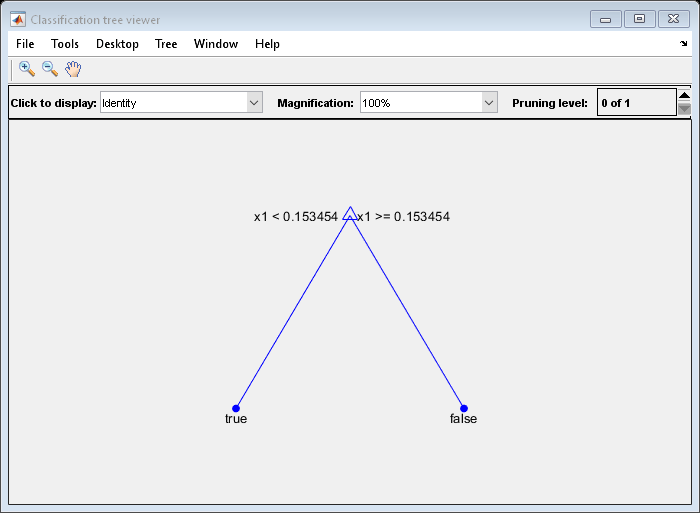
修剪后的树正确地将小于0.15的观测值分类为真正的.它还正确地将0.15到0.94的观测值划分为假.然而,它错误地将大于。94的观测值归类为假.因此,大于0.15的观测值应该是0.05 / 0.85 =。06年的真正的,约为.8/.85=。94年假.
的前10行计算预测得分X:
[~,分数]=预测(tree1 X (1:10));(分数X (1:10)):
ans =10×30.9059 0.0941 0.8147 0.9059 0.0941 0.9058 0 1.0000 0.1270 0.9059 0.0941 0.9134 0.9059 0.0941 0.6324 0 1.0000 0.0975 0.9059 0.0941 0.2785 0.9059 0.0941 0.5469 0.9059 0.0941 0.9575 0.9059 0.0941 0.9649
的确,每一种价值X(最右边的列)小于0.15的有相关的分数(左边和中间的列)0和1,而其他的价值观X有相关的分数0.91和0.09.(得分的区别0.09而不是预期的06)是由于统计上的波动:有8观察X范围内(1) .95而不是预期的5观察。
算法
预测的分支生成预测Mdl直到它到达叶节点或丢失的值。如果预测到达叶节点时,它返回该节点的分类。
如果预测到达一个缺少预测器值的节点时,其行为取决于代理名称-值对的时候fitctree构造Mdl.
代理=“关闭”(默认)预测返回到达节点的训练样本数量最大的标签。代理=“上”- - - - - -预测在节点上使用最佳代理分割。如果所有的代理变量都为正联想预测测量人失踪,预测返回到达节点的训练样本数量最大的标签。关于定义,请参见联想预测测量.
选择功能
金宝app仿真软件块
将分类树的预测模型集成到Simulink中金宝app®,你可以使用ClassificationTree预测块在统计和机器学习工具箱™库或MATLAB®函数块预测函数。有关示例,请参见使用ClassificationTree预测块预测类标签和用MATLAB函数块预测类标签.
在决定使用哪种方法时,请考虑以下几点:
如果使用统计学和机器学习工具箱库块,则可以使用定点的工具(定点设计师)将浮点模型转换为定点模型。
金宝app的MATLAB函数块必须启用对可变大小数组的支持
预测函数。如果您使用MATLAB函数块,您可以使用MATLAB函数在同一个MATLAB函数块中进行预测之前或之后的预处理或后处理。
扩展功能
你也可以从以下列表中选择一个网站:
