非线性回归
什么是参数非线性回归模型?
参数非线性模型以形式表示一个连续响应变量与一个或多个连续预测变量之间的关系
y=f(X,β) +ε,
在哪里
y是一个n-乘1向量的观察响应变量。
f是任意函数X和β计算每一行的值X和向量一起β的对应行计算预测y.
X是一个n——- - - - - -p预测器矩阵,每一行代表一个观察,每一列代表一个预测器。
β是一个p-乘1向量的未知参数被估计。
ε是一个n独立同分布随机扰动的-1向量。
与此相反,非参数模型并不试图用模型参数来描述预测因素和响应之间的关系。描述通常是图形化的,例如决策树.
fitnlm试图找到参数的值β使观察到的响应之间的均方差异最小化y以及模型的预测f(X,β).为此,它需要一个初始值beta0在迭代修改向量之前β到一个具有最小均方误差的向量。
准备数据
要开始拟合回归,请将数据转换为拟合函数所期望的形式。所有回归技术都是从数组中的输入数据开始的X响应数据在一个单独的向量中y,或表或数据集数组中的输入数据资源描述和响应数据作为列资源描述.输入数据的每一行代表一个观察。每一列代表一个预测器(变量)。
用于表或数据集数组资源描述,表示响应变量“ResponseVar”名称-值对:
mdl = fitlm(资源描述,“ResponseVar”,“血压”);
默认情况下,响应变量是最后一列。
你不能使用分类非线性回归的预测器。绝对预测器是从一组固定的可能性中取值。
表示缺失数据为南用于输入数据和响应数据。
输入和响应数据的数据集数组
例如,从Excel创建数据集数组®电子表格:
ds =数据集(“XLSFile”,“hospital.xls”,...“ReadObsNames”,真正的);
从工作区变量创建数据集数组:
负载carsmallds =数据集(重量、Model_Year MPG);
输入和响应数据表
从Excel电子表格创建表格:
台= readtable (“hospital.xls”,...“ReadRowNames”,真正的);
要从工作区变量创建一个表:
负载carsmall台=表(重量、Model_Year MPG);
数字矩阵的输入数据和数字向量的响应
例如,要从工作区变量创建数字数组:
负载carsmallX =[重量马力汽缸Model_Year];y = MPG;
从Excel电子表格创建数字数组:
[X, Xnames] = xlsread(“hospital.xls”);y = X (:, 4);反应y为收缩压X (:, 4) = [];从X矩阵中去掉y
请注意非数字项,例如性,不出现在X.
表示非线性模型
有几种表示非线性模型的方法。用最方便的方式。
非线性模型是一个必要的输入fitnlm,在modelfun输入。
fitnlm假设响应函数f(X,β)的参数是平滑的β.如果你的功能不顺利,fitnlm无法提供最优参数估计。
匿名函数或函数文件的函数句柄
函数句柄@modelfunb (x)接受一个向量b以及矩阵、表或数据集数组x.函数句柄应该返回一个向量f行数和x.例如,函数文件hougen.m计算
通过输入来检查函数类型hougen在MATLAB®命令行。
反应动力学的hougen - watson模型。% YHAT = HOUGEN(BETA,X)给出了%反应速率的预测值YHAT,作为%参数向量BETA和数据矩阵X的函数。% BETA必须有5个元素,X必须有3个%列。引用:% [1]Bates, Douglas, and Watts, Donald, "非线性%回归分析及其应用",Wiley % 1988 p. 271-272。% Copyright 1993-2004 The MathWorks, Inc. % B.A. Jones 1-06-95。b1 =β(1);b2 =β(2);b3 =β(3);b4 =β(4);b5 =β(5);x1 = x (: 1); x2 = x(:,2); x3 = x(:,3); yhat = (b1*x2 - x3/b5)./(1+b2*x1+b3*x2+b4*x3);
您可以编写一个匿名函数来执行与hougen.m.
modelfun = @ (b, x) (b) (1) * (:, 2) - x (:, 3) / b(5)) /…(1 + b *x(:,1) + b(3)*x(:,2) + b(4)*x(:,3))
公式的文本表示
对于矩阵中的数据X向量中的响应y:
用下列公式表示
x1的作为第一个预测器(列)X,“x2”作为第二个预测因子,等等。表示需优化的参数向量为
“b1”,“b2”等。将公式写成
'y ~(数学表达式)'.
例如,表示对反应数据的响应:
modelfun = ' y ~ (b1 * x2 - x3 / b5) / (1 + b2 * x1 + b3 * x2 + b4 * x3)”;
对于表或数据集数组中的数据,可以使用表示为表或数据集数组变量名的公式。将响应变量名放在公式的左边,后面跟着a~,后面是表示响应公式的字符向量。
这个例子展示了如何创建一个字符向量来表示对反应数据集数组中的数据。
加载
反应数据。负载反应
将数据放入数据集数组中,其中每个变量都有一个名称
xn或yn.ds =数据集({反应物,xn (1:), xn (2:), xn(3:)},…{率,yn});检查数据集数组的第一行。
ds(1,:) ans = n_戊烷异戊烷反应速率470 300 10 8.55
写
hougen使用数据集数组中的名称进行计算。modelfun =['反应速率~ (b1*n_Pentane - Isopentane/b5) /'…' (1 + h2 *b2 + n_戊烷*b3 +异戊烷*b4)'] modelfun = ReactionRate ~ (b1* n_戊烷-异戊烷/b5) /…(1 +氢*b2 + n_戊烷*b3 +异戊烷*b4)
选择初始向量
拟合迭代的初始向量,beta0,可以极大地影响得到的拟合模型的质量。beta0给出问题的维度,这意味着它需要正确的长度。很好的选择beta0导致一个快速、可靠的模型,而一个糟糕的选择可能导致长时间的计算,或导致一个不充分的模型。
选择商品是很难给出建议的beta0.如果你认为向量的某些分量应该是正的或负的,设置beta0拥有这些特征。如果你知道其他分量的近似值,把它们包括进去beta0.但是,如果您不知道合适的值,可以尝试使用随机向量,例如
beta0 = randn(据nvar, 1);% or beta0 = 10*rand(nVars,1);
将非线性模型与数据拟合
使用表或数据集数组拟合非线性回归模型的语法资源描述是
mdl = fitnlm(资源描述、modelfun beta0)
使用数字数组拟合非线性回归模型的语法X和数值响应向量y是
mdl = fitnlm (X, y, modelfun beta0)
有关表示输入参数的信息,请参见准备数据,表示非线性模型,选择初始向量.
fitnlm假设响应变量在表或数据集数组中资源描述是最后一列。要改变这种情况,请使用ResponseVar命名响应列的名称-值对。
拟合非线性模型的质量检验与调整
有一些诊断图可以帮助您检查模型的质量。plotDiagnostics (mdl)给出了各种各样的图,包括杠杆和库克的距离图。plotResiduals (mdl)给出了拟合模型和数据之间的差异。
还有一些性质mdl这与模型质量有关。mdl。RMSE给出了数据与拟合模型之间的均方根误差。mdl.Residuals.Raw给出原始残差。mdl。诊断包含多个字段,例如利用和CooksDistance,它可以帮助你识别特别有趣的观察结果。
这个例子展示了如何使用诊断、残差和切片图来检验一个拟合的非线性模型。
加载示例数据。
负载反应
建立一个非线性模型的速率作为函数反应物使用hougen.m函数。
beta0 = 1(5、1);mdl = fitnlm(反应物,...率、@hougen beta0);
制作数据和模型的杠杆图。
plotDiagnostics (mdl)
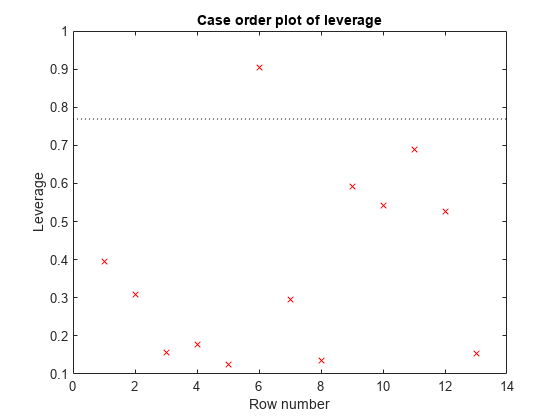
有一点杠杆率很高。确定点的位置。
[~, maxl] = max (mdl.Diagnostics.Leverage)
maxl = 6
检查残差图。
plotResiduals (mdl“安装”)
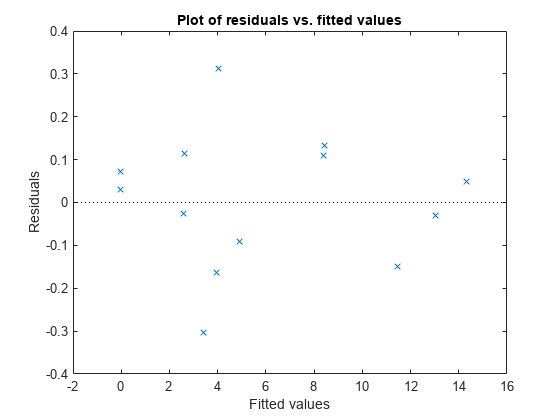
没有什么是出类拔萃的。
使用切片图来显示每个预测因子对模型的影响。
plotSlice (mdl)
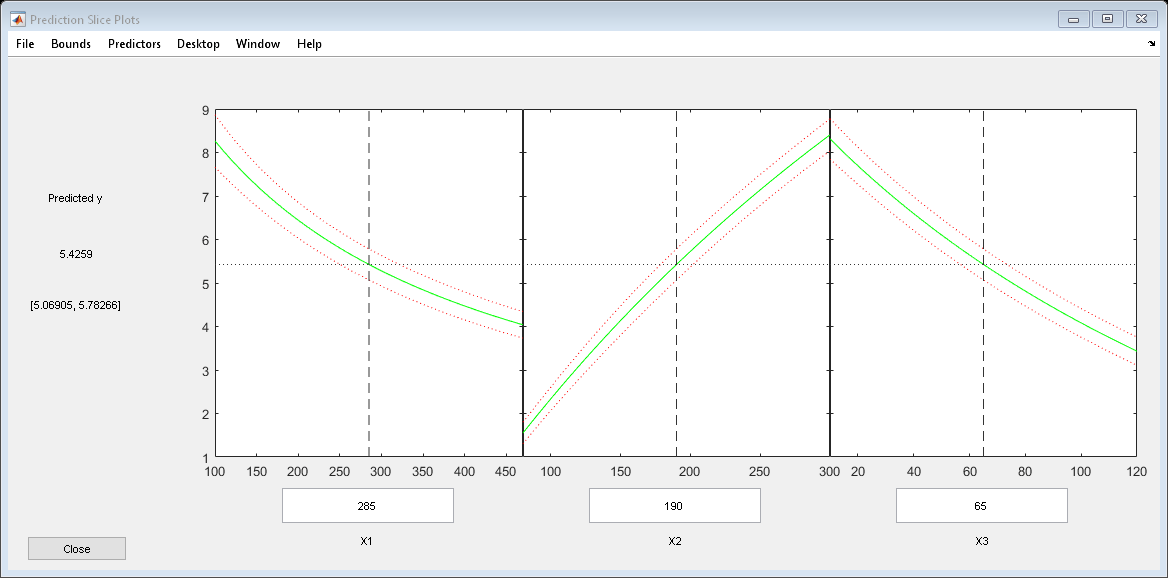
您可以拖动垂直的蓝色虚线,以查看一个预测器的更改对响应的影响。例如,将X2线向右拖动,注意到X3线的斜率发生了变化。
使用非线性模型预测或模拟响应
这个例子展示了如何使用这些方法预测,函数宏指令,随机预测和模拟对新数据的反应。
从柯西分布随机生成一个样本。
rng (“默认”) X = rand(100,1);X = tan(X - /2);
根据模型生成响应Y = b1*(/2 + atan(x - b2) / b3)并在回应中加入噪音。
Modelfun = @(b,x) b(1) *...(pi/2 + atan((x - b(2))/b(3)))y = modelfun([12 5 10],X) + randn(100,1);
从任意参数开始拟合模型b=(1 1 1)。
β = [1 1 1];%随便猜测mdl = fitnlm (X, y, modelfun beta0)
mdl =非线性回归模型:y ~ b1*(pi/2 + atan((x - b2)/b3)) Estimated Coefficients: Estimate SE tStat pValue ________ _______ ______ __________ b1 12.082 0.80028 15.097 3.3151e-27 b2 5.0603 1.0825 4.6747 9.50633 -06 b3 9.64 0.46499 20.732 2.0382e-37观测次数:100,误差自由度:971.02 R-Squared: 0.92, Adjusted R-Squared 0.918 F-statistic vs. zero model: 6.45e+03, p-value = 1.72e-111
拟合值在参数的几个百分比内[12,5,10]。
检查健康。
plotSlice (mdl)
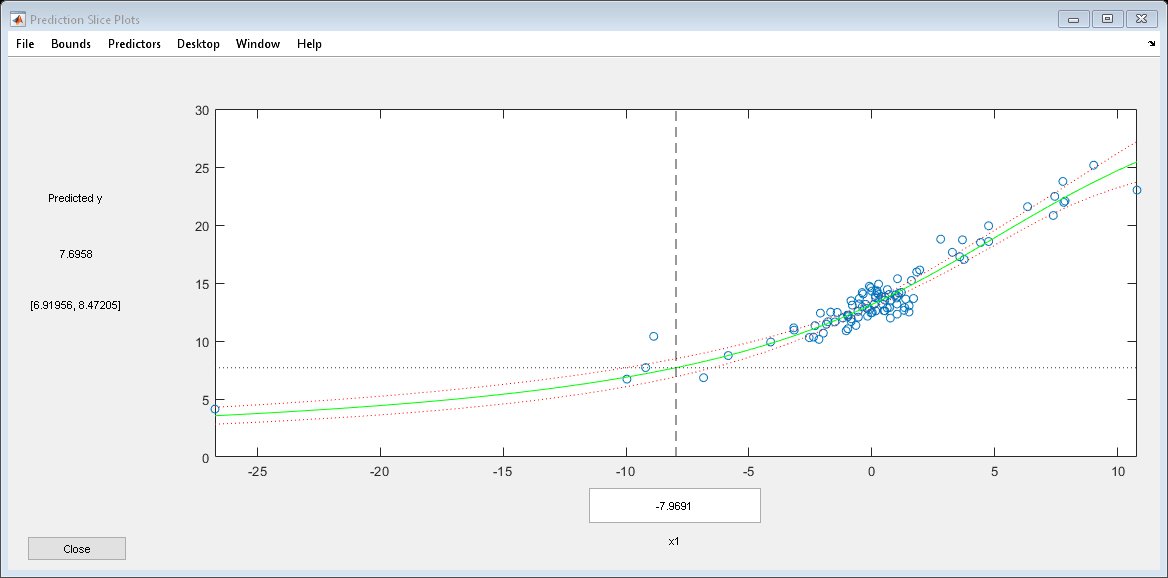
预测
的预测方法预测平均响应,如果需要,给出置信范围。找到关于点的预测响应值和预测响应置信区间X值(-15;5。12)。
Xnew =(-15; 5。12);[ynew, ynewci] =预测(mdl Xnew)
ynew =3×15.4122 18.9022 26.5161
ynewci =3×24.8233 6.0010 18.4555 19.3490 25.0170 28.0151
置信区间反映在切片图中。
函数宏指令
的函数宏指令方法预测平均响应。函数宏指令在从数据集数组构造模型时,使用通常比预测更方便。
从数据集数组创建非线性模型。
ds =数据集({X,“X”}, {y,“y”});mdl2 = fitnlm (ds, modelfun beta0);
找到预测的模型响应(CDF)在X值(-15;5。12)。
Xnew =(-15; 5。12);ynew =函数宏指令(mdl2 Xnew)
ynew =3×15.4122 18.9022 26.5161
随机
的随机方法模拟新的随机响应值,等于平均预测加上一个与训练数据具有相同方差的随机扰动。
Xnew =(-15; 5。12);Xnew ysim =随机(mdl)
ysim =3×16.0505 19.0893 25.4647
重新运行随机方法。改变的结果。
Xnew ysim =随机(mdl)
ysim =3×16.3813 19.2157 26.6541
你也可以从以下列表中选择一个网站:
