使用LSTM网络对性别进行分类
这个例子展示了如何使用深度学习对说话者的性别进行分类。该示例使用双向长短时记忆(BiLSTM)网络和Gammatone倒谱系数(gtcc)、基音、谐波比和几个光谱形状描述符。
介绍
基于语音信号的性别分类是许多音频系统的重要组成部分,例如自动语音识别、说话人识别和基于内容的多媒体索引。
此示例使用长期短期内存(LSTM)网络,一种复发性神经网络(RNN)非常适合研究序列和时间序列数据。LSTM网络可以在序列的时间步长之间学习长期依赖性。LSTM层(lstmlayer.(深度学习工具箱))可以在向前方向上看时间序列,而双向LSTM层(双层膜(深度学习工具箱))可以查看向前和向后方向的时间序列。此示例使用双向LSTM层。
该示例将LSTM网络与γCepstrum系数序列进行培训(GTCC.),音高估计(抛),谐波比(Halmonicratio.),以及一些光谱形状描述符(光谱描述符).
要加速培训过程,请在带GPU的计算机上运行此示例。如果您的机器有GPU和并行计算工具箱™,那么Matlab©自动使用GPU进行培训;否则,它使用CPU。
用预先训练的网络分类性别
在详细介绍培训过程之前,您将使用预先培训过的网络在两个测试信号中对说话人的性别进行分类。
加载预先训练的网络以及用于特征归一化的预先计算的向量。
加载(“genderIDNet.mat”那'genderidnet'那'M'那');
用公扬声器加载测试信号。
[audioIn,Fs]=音频读取('malespeech.flac'); 声音(音频输入,Fs)
在信号中隔离语音区域。
边界=检测echech(AudioIn,FS);AudioIn = AudioIn(边界(1):边界(2));
创建一个audiofeatureextractor.从音频数据中提取功能。您将使用相同的对象提取培训的功能。
Extractor = audiofeatureextractor(......“采样率”,财政司司长,......“窗户”,汉明(圆形(0.03*Fs),“定期”),......“overlaplength”,圆形(0.02 * fs),............“GTCC”,真的,......“gtccdelta”,真的,......“gtccDeltaDelta”,真的,............“光谱描述输入”那“melspectrum”那......“Spectralcentroid”,真的,......“光谱性”,真的,......“spectralflux”,真的,......“spectralslope”,真的,............“沥青”,真的,......“halmonicratio”,真的);
从信号中提取特征并使它们标准化。
特点=提取物(提取器,AUDION);特征=(特征。' - m)./ s;
对信号进行分类。
性别=分类(性别数据网、特征)
性别=分类男性
用女性扬声器对另一个信号进行分类。
[audioIn,Fs]=音频读取('femaleSpeech.flac'); 声音(音频输入,Fs)
边界=检测echech(AudioIn,FS);AudioIn = AudioIn(边界(1):边界(2));特点=提取物(提取器,AUDION);特征=(特征。' - m)./ s;分类(Genderidnet,功能)
ans=分类女性
预处理培训音频数据
在使用特征向量序列时,此示例中使用的Bilstm网络最佳地工作。为了说明预处理流水线,此示例通过单个音频文件的步骤。
读取包含语音的音频文件的内容。发言人性别是男性。
[AudioIn,FS] = audioread('Counting-16-44p1-mono-15secs.wav'); 标签={'男性'};
绘制音频信号,然后使用它侦听声音命令。
TimeVector =(1 / FS)*(0:尺寸(AudioIn,1)-1);图绘图(TimeVector,AudioIn)Ylabel(“振幅”)xlabel(“时间”) 标题(“样本音频”) 网格在…上

声音(AudioIn,FS)
语音信号具有静音片段,不包含与扬声器的性别有关的有用信息。使用侦探讲话找到音频信号中的语音段。
语音indices =检测echech(AudioIn,FS);
创建一个audiofeatureextractor.从音频数据中提取功能。语音信号在性质中是动态的,随时间变化。假设语音信号在短时间比例上静止,并且它们的处理通常在20-40毫秒的窗口中进行。使用20毫秒重叠指定30毫秒的窗口。
Extractor = audiofeatureextractor(......“采样率”,财政司司长,......“窗户”,汉明(圆形(0.03*Fs),“定期”),......“overlaplength”,圆形(0.02 * fs),............“GTCC”,真的,......“gtccdelta”,真的,......“gtccDeltaDelta”,真的,............“光谱描述输入”那“melspectrum”那......“Spectralcentroid”,真的,......“光谱性”,真的,......“spectralflux”,真的,......“spectralslope”,真的,............“沥青”,真的,......“halmonicratio”,真的);
从每个音频段提取特征。输出从audiofeatureextractor.是A.numfeaturevectors.-经过-numfeatures.大批。这sequenceInputlayer.在此示例中使用需要时间沿第二维度。释放输出阵列,使时间沿着第二维度。
FeatureVectorSegment={};为了II = 1:大小(语音indices,1)featurevectorsse {end + 1} =(提取器(提取器,AudioIn(Indioin(II,1):语音indices(ii,2))))';结尾numsegments = size(featurevectorsse段)
numsegments =1×21 11.
[numFeatures,NumFeatureVectorSegment1]=大小(FeatureVectorSegment{1})
numFeatures=45
NumFeatureVectorsSegment1 = 124.
复制标签,使它们与段一对一的对应关系。
标签=重复(标签,大小(语音索引,1))
标签=1×11电池{'male'} {'male'} {'male'} {'male'} {'male'} {'male'} {'male'} {'male'} {'male'} {'male'} {'male'} {'male'}{'男性'}
使用时sequenceInputlayer.,使用一致长度的序列通常是有利的。将特征向量的阵列转换为特征向量的序列。使用每个序列20个特征向量,5个特征向量重叠。
featurevectorspersequence = 20;featurevectoroverlap = 5;hoplength = featurevectorspersequence - featurevectorovelap;IDX1 = 1;featurestrain = {};severnpersegment = zeros(numel(featurevectorsse),1);为了II = 1:NUMER(FeatureVectorsSegment)SeverPersegersegment(ii)= max(bloor(floor(sceasevectorsse {ii},2) - featurevectorspersequence)/ hoplength)+ 1,0);IDX2 = 1;为了j = 1:sementpersegment(ii)featurestrain {idx1,1} = featurevectorssegment {ii}(:, idx2:idx2 + featurevectorspersequence - 1);IDX1 = IDX1 + 1;IDX2 = IDX2 + HopLength;结尾结尾
有关简洁,请求功能HelperFeatureVector2sequence.封装上述处理并在整个示例的其余部分中使用。
复制标签,使其与训练集一一对应。
标签=重复(标签、序列片段);
预处理管道的结果是数列- 1个细胞阵列numfeatures.-经过-featurevectorspersequence.矩阵。标签是A.数列-by-1阵列。
numsequence = numel(featurestrain)
numsequence = 27.
[NumFeatures,FeatureVectorsPersequence] =尺寸(FeatureStrain {1})
numfeatures = 45.
featurevectorspersequence = 20.
NumSequence=numel(标签)
numsequence = 27.
该图提供了每个检测到的语音区域使用的特征提取的概述。
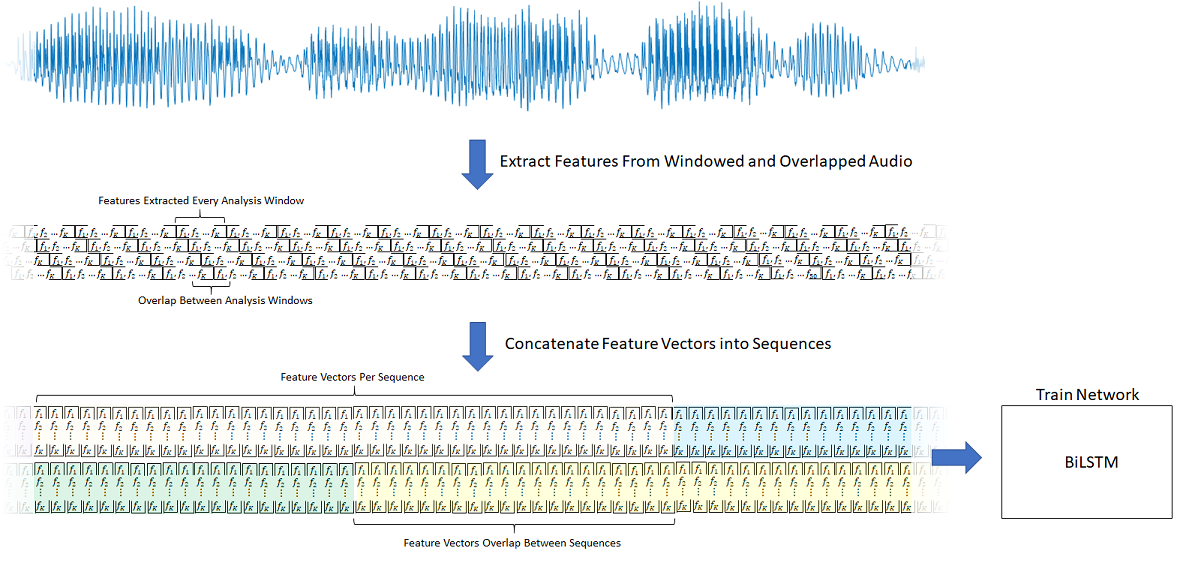
创建培训和测试数据存储
此示例使用Mozilla公共语音数据集的子集[1]。DataSet包含48 kHz的主题录制短句。下载DataSet和Untar下载文件。放路径数据库到数据的位置。
URL =.'http://ssd.mathwands.com/金宝appsupportfiles/audio/commonvoice.zip';downloadfolder = tempdir;datafolder = fullfile(downloadlefolder,'commonvoice');如果〜存在(DataFolder,'dir')disp('下载数据集(956 MB)......')解压缩(URL,DownloadFolder)结尾
使用audiodatastore.创建培训和验证集的数据存储。使用可读读取与音频文件关联的元数据。
loc = fullfile(datafolder);adstrain = audiodatastore(fullfile(loc,“火车”),“包含子文件夹”,真的);MetadataTrain = Readtable(FullFile(FullFile(Loc,“火车”),“火车,tsv”),“文件类型”那“文本”);adstrain.labels = MetadataTrain.Cender;adsvalidation = audiodataStore(fullfile(loc,'验证'),“包含子文件夹”,真的);MetAdatavalidation = ReadTable(FullFile(FullFile(Loc,'验证'),“验证.TSV”),“文件类型”那“文本”);ADSValidation.Labels = MetAdataValidation.gender;
使用计数标签检查培训和验证集的性别分类。
计数标签(adsTrain)
ans =.2×2表标签数______ _____女性1000男性1000
countEachLabel(adsValidation)
ans =.2×2表标签数______ _____女性200男性200
要将网络与整个数据集一起培训并达到最高的准确性,请设置还原酶到错误的。快速运行此示例,设置还原酶到真的。
depentataset = false;如果还原酶%将训练数据集减少20倍adstrain = splitheachlabel(adstrain,round(numel(adstrain.files)/ 2/20));ADSValidation = SpliteachLabel(ADSValidation,20);结尾
创建培训和验证集
确定数据集中的音频文件的采样率,然后更新音频特征提取器的采样率,窗口和重叠长度。
[~,adsInfo]=读取(adsTrain);Fs=adsInfo.SampleRate;提取器.SampleRate=Fs;提取器。窗口=海明(圆形(0.03*Fs),“定期”); 提取器。重叠长度=圆形(0.02*Fs);
加快处理,分发多个工人的计算。如果您有并行计算工具箱™,则示例将数据存储区分区,以便在可用工人上并行发生特征提取。确定系统的最佳分区数。如果您没有并行计算工具箱™,则该示例使用单个工人。
如果〜isempty(ver(“平行”))&&〜oderataset pool = gcp;numpar = numpartitions(adstrain,pool);其他的numpar = 1;结尾
在循环中:
从音频数据存储读取。
检测语音区域。
从语音区域中提取特征向量。
复制标签,使它们与特征向量一对一的对应关系。
labelstrain = [];featurevectors = {};%循环最优分区数议案II = 1:numpar%分区数据存储subds=分区(adsTrain,numPar,ii);%preallocation.featurevectorsinsubds = {};segmentsperfile = zeros(numel(subds.files),1);分区数据存储中的文件遍历文件为了JJ = 1:numel(subds.files)%1.在单个音频文件中读取AudioIn =读(Subds);%2.确定与语音相对应的音频区域语音indices =检测echech(AudioIn,FS);%3.每个语音段的提取特征segmentsPerFile(jj)=大小(SpeechIndex,1);特征=单元(分段文件(jj),1);为了kk=1:size(speechindex,1)特征{kk}=(extract(extractor,audioIn)(speechindex(kk,1):speechindex(kk,2)));结尾featurevectorsinsubds = [featurevectorsinsubds;特征(:)];结尾featurevectors = [featurevectors; featurevectorsinsubds];%复制标签,使它们处于一对一的通勤具有特征向量的百分比。repedLabels=repelem(子标签、分段文件);labelsTrain=[labelsTrain;重复标记(:)];结尾
在分类应用中,良好的做法是使所有功能标准化为零平均值和单位标准偏差。
计算每个系数的均值和标准偏差,并使用它们来标准化数据。
AllFeatures = Cat(2,FeatureVectors {:});所有种(Isinf(Allfeatures))= Nan;m =均值(全部,2,'omitnan');s = std(全部,0,2,'omitnan');featurevectors = Cellfun(@(x)(x-m)./ s,featurevectors,'统一输出',假);为了II = 1:numel(featurevectors)idx = find(iSnan(featurevectors {ii}));如果~isempty(idx)特征向量{ii}(idx)=0;结尾结尾
将特征向量缓冲到具有10个重叠的20个特征向量的序列中。如果序列具有少于20个特征向量,请将其丢弃。
[FeatureStrain,TrainSequencePersegment] = HelperFeatureVector2序列(FeatureVectors,FeatureVectorsPersequence,FeatureVectoroverlap);
复制标签,使它们与序列一对一的对应关系。
LabelStrain = Repelem(Labelstrain,[训练序列{:}]);LabelStrain =分类(Labelstrain);
使用用于创建培训集的相同步骤创建验证集。
labelsvalidation = [];featurevectors = {};valsegmentsperfile = [];议案II = 1:numpar subds = partition(ADSValidation,NumPar,II);featurevectorsinsubds = {};valsegmentsperfileinsubds = zeros(numel(subds.files),1);为了jj=1:numel(subds.Files)audioIn=read(subds);语音指数=检测语音(音频输入,Fs);numSegments=大小(speechindex,1);特征=单元(valSegmentsPerFileInSubDS(jj),1);为了kk = 1:numsgments特征{kk} =(提取器(提取器,AudioIn(keighindices(kk,1):语音indices(kk,2))))';结尾featurevectorsinsubds = [featurevectorsinsubds;特征(:)];valsegmentsperfileinsubds(JJ)= Numegements;结尾RepedLabels = Repelem(Subds.Labels,ValSegmentsPerfileInsubds);LabelSvalidation = [LabelsValidation; RepedLabels(:)];featurevectors = [featurevectors; featurevectorsinsubds];valsegmentsperfile = [valsegmentsperfile; valsegmentsperfileinsubds];结尾featurevectors = Cellfun(@(x)(x-m)./ s,featurevectors,'统一输出',假);为了II = 1:numel(featurevectors)idx = find(iSnan(featurevectors {ii}));如果~isempty(idx)特征向量{ii}(idx)=0;结尾结尾[featuresValidation,ValsSequencePerSegment]=HelperFeatureVector2序列(featureVectors,FeatureVectorSequence,featureVectorOverlap);labelsValidation=repelem(labelsValidation[ValsSequencePerSegment{:}]);labelsValidation=分类(labelsValidation);
定义LSTM网络架构
LSTM网络可以学习序列数据的时间步长之间的长期依赖关系。此示例使用双向LSTM层双层膜查看向前和向后方向的序列。
指定输入大小为大小的序列numfeatures.。指定具有输出大小为50的隐藏双向LSTM层并输出序列。然后,指定具有50的输出大小的双向LSTM层,并输出序列的最后一个元素。此命令指示双向LSTM层将其输入映射到50个功能,然后为完全连接的图层准备输出。最后,通过包括完全连接的大小2层来指定两个类,然后是Softmax层和分类层。
层= [......sequenceInputLayer(大小(特征菌株{1},1))BilstLayer(50,“输出模式”那“顺序”)双层膜(50,“输出模式”那“最后”)全连接层(2)SoftMaxLayer分类层];
接下来,指定分类器的培训选项。放maxepochs.到4.因此,网络使4通过培训数据进行4。放小批量以使网络一次查看128个训练信号。具体说明绘图作为“培训 - 进展”当迭代次数增加时,生成显示培训进度的地块。放冗长的到错误的要禁用对应于图中所示的数据的表输出。指定洗牌作为“每个时代”在每个时代开始时播放训练序列。指定学习进度表到“分段”每次通过一定数量的时期(1)都通过指定因子(0.1)减少学习率。
此示例使用自适应时刻估计(ADAM)求解器。adam与经常性的神经网络(RNNS)相比,LSTMS比具有动量(SGDM)求解器的默认随机梯度下降更好。
minibatchsize = 256;验证频率=地板(Numel(Labelstrain)/小匹匹匹匹配);选项=培训选项(“亚当”那......“maxepochs”,4,......“最小批量大小”,小匹马,......“情节”那“培训 - 进展”那......“verbose”,错,......“洗牌”那“每个时代”那......“LearnRateSchedule”那“分段”那......“学习ropfactor”,0.1,......“LearnRateDropPeriod”,1,......“验证数据”,{特点过验证,labelsvalidation},......“验证频率”,验证频率);
训练LSTM网络
使用指定的培训选项和图层架构列车LSTM网络使用列车网络。因为训练集很大,培训过程可能需要几分钟。
net = trainnetwork(Featurestrain,labelstrain,图层,选项);
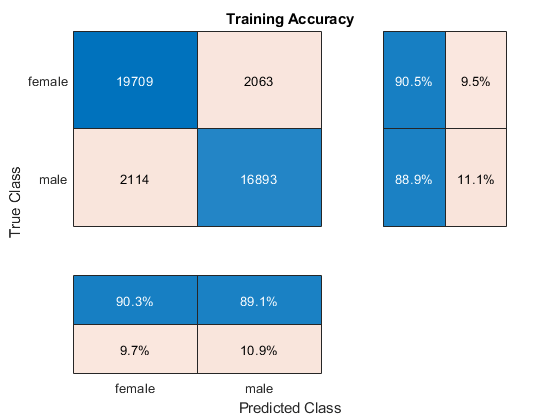
训练进度图的顶部子图表示训练准确性,这是每个迷你批处理上的分类准确性。当培训成功进行时,该值通常会增加100%。底部子图显示训练丢失,这是每个迷你批处理上的跨熵丢失。当培训成功进行时,该值通常会降低零。
如果训练不收敛,则该图可能会在不在某个向上或向下方向上培训的值之间振荡。这种振荡意味着训练准确性没有改善,训练损失没有减少。这种情况可以在培训开始时或经过训练准确性的一些初步提高。在许多情况下,更改培训选项可以帮助网络实现融合。减少小批量或减少初始学习率可能导致更长的培训时间,但它可以帮助网络了解更好。
将训练精度可视化
计算培训准确性,这表示分类器对培训的信号的准确性。首先,分类培训数据。
预测=分类(Net,FeatureStrain);
绘制混乱矩阵。使用列和行摘要显示两个类的精度并回忆。
图cm=混淆图(分类(标签序列),预测,'标题'那'训练准确性'); cm.摘要='列 - 归一化';cm.rowsummary ='行标准化';

可视化验证准确性
计算验证精度。首先,对训练数据进行分类。
[预测,概率] =分类(网络,特征过验证);
绘制混乱矩阵。使用列和行摘要显示两个类的精度并回忆。
图CM = ConfusionChart(分类(标签(LabelSvalidation),预测,'标题'那'验证设置精度'); cm.摘要='列 - 归一化';cm.rowsummary ='行标准化';
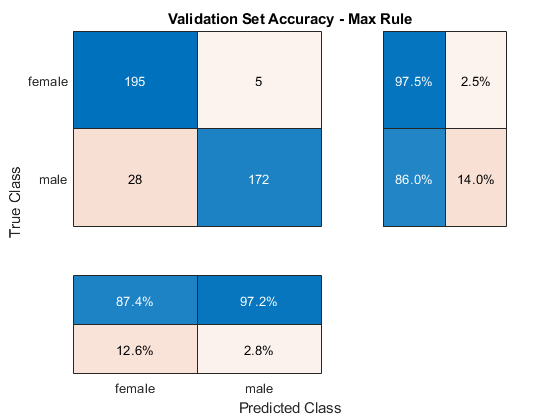
示例生成来自每个训练语音文件的多个序列。通过考虑对应于同一文件的所有序列的输出类,以及应用“最大规则”决定,可以选择更高的准确度,并且选择具有最高置信度分数的段的类。
确定验证集中每个文件生成的序列数。
sequencePerFile=零(大小(valSegmentsPerFile));ValsSequencePerSegmentMat=cell2mat(ValsSequencePerSegment);idx=1;为了II = 1:numel(valsegmentsperfile)severperfile(ii)= sum(valsequencepersegmentmat(idx:idx + valsegmentsperfile(ii)-1));idx = idx + valsegmentsperfile(ii);结尾
通过考虑从同一文件生成的所有序列的输出类来预测每个培训文件中的性别。
numFiles=numel(adsvalization.Files);actualGender=分类(adsValidation.Labels);预测端=实际端;分数=单元格(1,numFiles);计数器=1;cats=唯一(实际引导器);为了索引=1:numFiles得分{index}=概率(计数器:计数器+序列文件(索引)-1,:);m=最大值(平均值{index},1),[],1);如果m(1)> = m(2)预测性(指数)=猫(1);其他的预测指数=猫(2);结尾计数器=计数器+sequencePerFile(索引);结尾
对大多数规则预测的混淆矩阵可视化。
图CM = ConfusionChart(ActualGender,PredigeGender,'标题'那'验证设置精度 - max规则'); cm.摘要='列 - 归一化';cm.rowsummary ='行标准化';

参考
金宝app支持功能
功能[序列,semendpersegment] = HelperFeatureVector2序列(特征,FeatureVectorsPersequence,FeatureVectoroverlap)如果featurevectorspersequence <= featurevectoroverlap错误(“重叠特征向量的数量必须小于每个序列的特征向量的数量。”)结尾hoplength = featurevectorspersequence - featurevectorovelap;IDX1 = 1;序列= {};severnpersegment = cell(numel(特征),1);为了ii=1:numel(特征)sequencePerSegment{ii}=max(floor((尺寸(特征{ii},2)-featureVectorsPerSequence)/hopLength)+1,0);idx2=1;为了j=1:sequencePerSegment{ii}序列{idx1,1}=features{ii}(:,idx2:idx2+featureVectorsPerSequence-1);%#好的IDX1 = IDX1 + 1;IDX2 = IDX2 + HopLength;结尾结尾结尾
您还可以从以下列表中选择网站: