检测
检测音频信号中的语音边界
句法
描述
例子
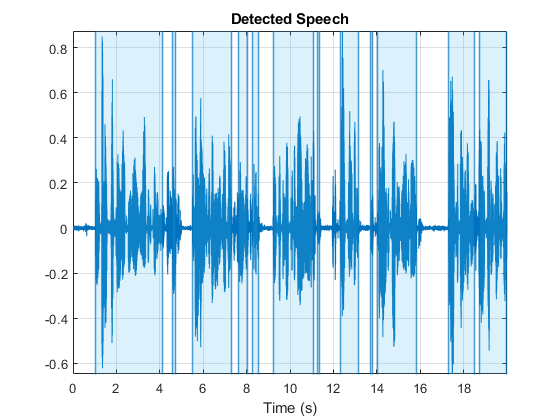
情节检测到语音的区域
读取音频信号。将音频信号剪辑到20秒。
[AudioIn,FS] = audioread('rainbow-16-8-mono-114secs.wav');AudioIn = AudioIn(1:20 * FS);
称呼检测。指定没有输出参数以显示检测到的语音区域的曲线。
检测expeech(AudioIn,FS);
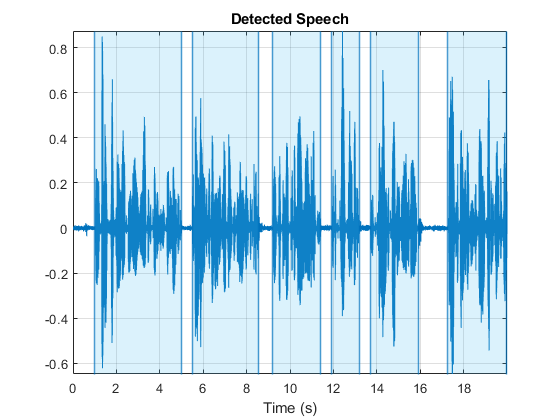
这检测函数使用基于能量和频谱传播的阈值算法。你可以修改窗户那overtaplenth, 和合作微调算法以满足您的特定需求。
WindowDuration =.0.074;%秒numwindowsamples = round(windowduration * fs);Win =汉明(Numwindowsamples,'定期');百分比=
35.;重叠= round(numwindowsamples * perciencoverlap / 100);mergeduration =.
0.44;Mergedist = round(Mergeduration * FS);检测echeech(AudioIn,FS,“窗户”,赢,“overlaplength”,交叠,“Mergedistance”,合并主义者)



重用决策阈值
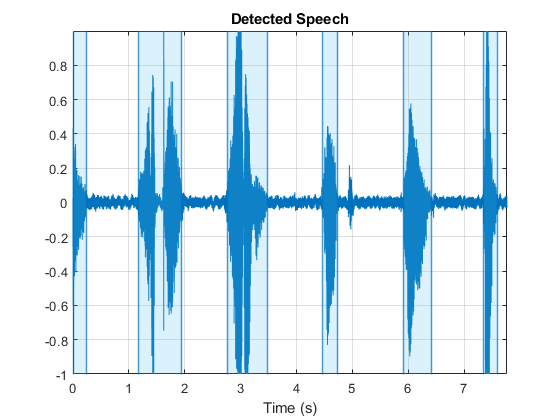
阅读包含语音的音频文件。将音频信号拆分为上半部和下半部分。
[AudioIn,FS] = audioread('Counting-16-44p1-mono-15secs.wav');FirstHalf = AudioIn(1:楼层(Numel(AudioIn)/ 2));secondhalf = audioin(numel(firsthalf):结束);
称呼检测在音频信号的前半部分。指定两个输出参数以返回对应于检测到的语音区域的索引以及用于该决定的阈值。
[语音indices,阈值] =检测echech(FirstHalf,FS);
称呼检测在下半部分,没有输出参数来绘制检测到的语音区域。指定从前一个呼叫确定的阈值检测。
检测expeech(第二个,FS,'门槛',阈值)
使用大数据集
重用语音检测阈值在使用大数据集时提供显着的计算效率,或者在部署深度学习或机器学习管道以进行实时推断时。下载并提取数据集[1]。
URL =.'https://storage.googleapis.com/download.tensorflow.org/data/speech_commands_v0.01.tar.gz';downloadfolder = tempdir;datasetfolder = fullfile(DownloadFolder,'google_speech');如果〜存在(DataSetFolder,'dir')disp('下载数据集(1.9 GB)...')Untar(URL,DataSetFolder)结尾
创建一个音频数据存储来指向录制。使用文件夹名称作为标签。
广告= audiodataStore(DataSetFolder,'insertumbfolders',真的,'labelsource'那'foldernames');
为此示例的目的,将数据集减少95%。
广告= SpliteachLabel(广告,0.05,'排除'那'_背景噪音');
创建两个数据存储:一个用于培训和一个用于测试。
[adstrain,adstest] = splitheachlabel(广告,0.8);
计算训练数据集的平均阈值。
阈值=零(Numel(adstrain.files),2);为了II = 1:numel(adstrain.files)[isausin,adsinfo] =读取(adstrain);[〜,阈值(ii,:)] =检测echech(AudioIn,Adsinfo.Samplevere);结尾阈值verage =平均值(阈值,1);
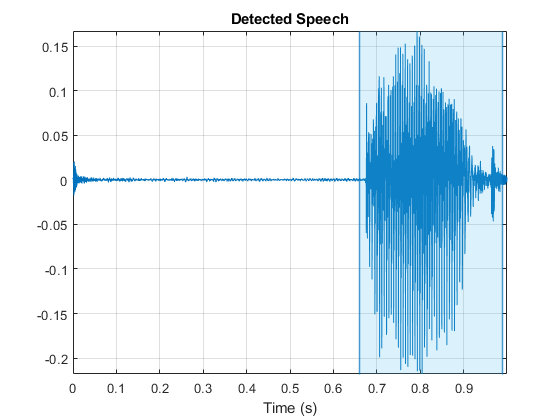
使用预先计算的阈值从测试数据集中检测文件上的语音区域。为三个文件绘制检测到的区域。
[Acioin,Adsinfo] =读(adstest);检测echech(AudioIn,Adsinfo.Samplerate,'门槛',阈值verage);

[Acioin,Adsinfo] =读(adstest);检测echech(AudioIn,Adsinfo.Samplerate,'门槛',阈值verage);

[Acioin,Adsinfo] =读(adstest);检测echech(AudioIn,Adsinfo.Samplerate,'门槛',阈值verage);
参考
[1]守望者,皮特。“语音命令:单词语音识别的公共数据集。”分布到Tensorflow。Creative Commons归因4.0许可证。
从语音信号中删除静音区域
阅读音频文件并收听它。绘图谱图。
[AudioIn,FS] = audioread('Counting-16-44p1-mono-15secs.wav');声音(AudioIn,FS)谱图(AudioIn,Hann(1024,'定期'),512,1024,FS,'yaxis')

对于机器学习应用程序,您通常希望从音频信号中提取功能。打电话给光谱产物在音频信号上的功能,然后绘制直方图显示光谱熵的分布。
熵= Spectralentropy(AudioIn,FS);numbins = 40;直方图(熵,酸尼斯,'正常化'那'可能性') 标题(“音频信号的光谱熵”)
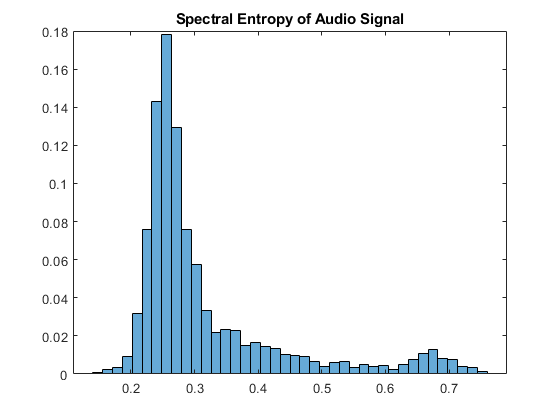
根据您的应用程序,您可能希望仅从语音区域中提取光谱熵。由此产生的统计数据是扬声器的更具特征,并且频道的特征更少。称呼检测在音频信号中,然后创建一个仅包含检测到的语音区域的新信号。
语音indices =检测echech(AudioIn,FS);SpeemSignal = [];为了II = 1:尺寸(语音indices,1)SpeechSignal = [SpeemSignal; AudioIn(SpeepIndices(II,1):语音indices(II,2))];结尾
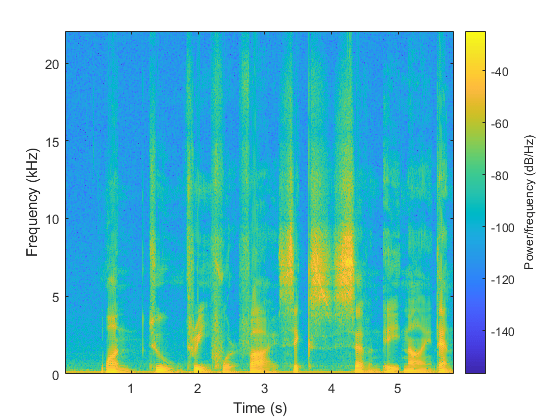
听听语音信号并绘制频谱图。
声音(SpeemSignal,FS)频谱图(SpeechSignal,Hann(1024,'定期'),512,1024,FS,'yaxis')
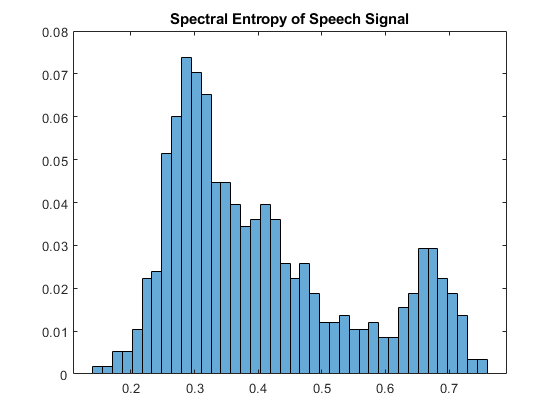
打电话给光谱产物在语音信号上的功能,然后绘制直方图显示光谱熵的分布。
熵= Spectralentropy(SpeechSignal,FS);直方图(熵,酸尼斯,'正常化'那'可能性') 标题(“语音信号的光谱熵”)
输入参数
输出参数
算法
这检测算法基于[1],虽然修改使得阈值的统计数据是短期能量和光谱传播,而不是短期能量和光谱质心。图和步骤提供了算法的高级概述。有关详细信息,请参阅[1]。
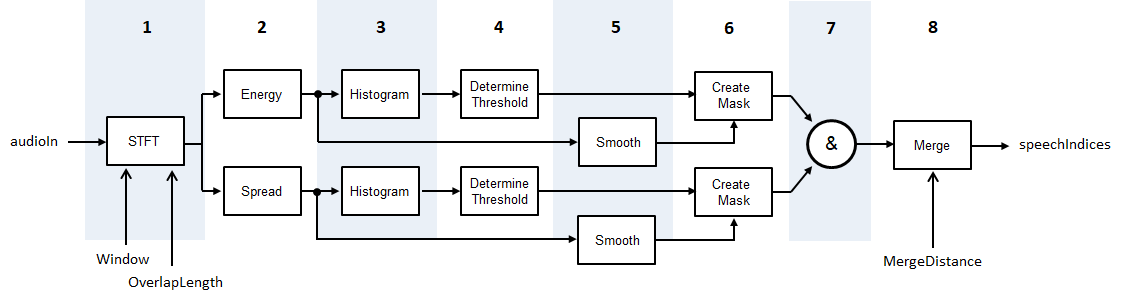
使用指定的音频信号将音频信号转换为时频表示
窗户和overtaplenth。为每个帧计算短期能量和光谱扩展。根据条件计算光谱差距
光谱覆盖。为短期能量和光谱传播分布而创建直方图。
对于每个直方图,根据阈值 , 在哪里m1和m2是第一和第二局最大的最大值。W.设定为
5.。通过连续的五元素移动中值过滤器通过连续的五元件,横跨频谱扩散和短期能量都是平滑的。
通过将短期能量和光谱传播与各自的阈值进行比较来创建掩模。要将帧声明为包含语音,则必须高于其阈值。
掩模组合。对于被宣布为语音的帧,短期能量和光谱扩展必须高于它们各自的阈值。
由于它们之间的距离小于
合作。
参考
[1] Giannakopoulos,Theodoros。“2009年雅典大学在Matlab实施的沉默去除和演讲信号分割的方法。
扩展能力
您还可以从以下列表中选择一个网站: