音频特征的顺序特征选择
这个例子展示了一个典型的特征选择工作流应用于语音数字识别任务。
在序列特征选择中,你在给定的特征集上训练一个网络,然后逐步增加或删除特征,直到达到最高的准确度[1].在本例中,您将使用自由语音数字数据集对语音数字识别任务应用顺序前向选择[2].
流语音数字识别
为了激发这个例子,首先加载一个预先训练过的网络audioFeatureExtractor用于训练网络对象,并对特征因子进行归一化处理。
加载(“network_Audio_SequentialFeatureSelection.mat”,“bestNet”,'afe',“标准化者”);
创建一个audiodevicereader.从麦克风读取音频。创造三个dsp。AsyncBuffer对象:一个用于缓冲从麦克风读取的音频,一个用于缓冲用于语音检测的输入音频的短期能量,一个用于缓冲预测。
FS = AFE.SAMPLEDE;devicereader = audiodevicereader(“SampleRate”fs,“SamplesPerFrame”,256);audiobuffer = dsp.asyncuffer(FS * 3);stebuffer = dsp.asyncubuffer(1000);predicationbuffer = dsp.asyncuffer(5);
创建一个图来显示流音频、网络在推理过程中输出的概率和预测。
无花果=图;streamAxes =次要情节(1,1);streamPlot =情节(0 (fs, 1));ylabel (“振幅”)Xlabel('时间'')标题('音频流')Streamaxes.xtick = [0,FS];Streamaxes.xticklabel = [0,1];stribexes.ylim = [-1,1];分析=子图(3,1,2);分析ZEDPLOT = PLOT(零(FS / 2,1));标题(分析了部分的)ylabel(“振幅”)Xlabel('时间''甘氨胆酸)组(,'xticklabel'[]) analyzedAxes。XTick = [0, fs / 2];analyzedAxes。XTickLabel = [0, 0.5];analyzedAxes。YLim = [1];probabilityAxes =情节(3、1,3);probabilityPlot =酒吧(0:9,0.1 * (10));轴([1,10,0,1])ylabel (“概率”)Xlabel(“类”)

执行流媒体数字识别(数字0到9)20秒。当循环运行时,说出其中一个数字并测试其准确性。
首先,定义一个短期能量阈值,在此阈值下假定一个信号不包含语音。
steThreshold = 0.015;idxVec = 1: fs;抽搐尽管toc < 20%从设备中读取音频帧。audioIn = deviceReader ();将音频写入缓冲区。写(audioBuffer audioIn);%当有200毫秒的数据未使用时,继续此循环。尽管audioBuffer。NumUnreadSamples > 0.2 * fs%从音频缓冲区读取1秒。1秒,800毫秒%表示重新读取旧数据,200ms表示新数据。audioToAnalyze =阅读(audioBuffer, fs, 0.8 * fs);%更新图形以绘制当前音频数据。streamPlot。YData = audioToAnalyze;ste =意味着(abs (audioToAnalyze));写(steBuffer, ste);如果steBuffer。NumUnreadSamples > 5 abc = sort(peek(steBuffer));steThreshold = abc(圆(0.4 *元素个数(abc)));结束如果ste> tethreshold.%使用detectspeech功能来确定一个语音区域%。Idx =检测echech(录音萼,FS);%如果存在语音区域,执行以下操作。如果~ isempty (idx)%零解出信号的所有部分除了演讲%区域,并修剪0.5秒。audioToAnalyze = HelperTrimOrPad (audioToAnalyze (idx (1,1): idx(1、2),fs / 2);%将音频正常化。audioToAnalyze = audioToAnalyze / max (abs (audioToAnalyze));%更新分析的段绘图analyzedPlot。YData = audioToAnalyze;%提取特征并转置,使时间为%在列。特点=(提取(afe audioToAnalyze) ';%将特征规格化。features = (features - normalize . mean) ./ normalize . standarddeviation;%调用分类,以确定概率和%获得标签。特性(isnan(特性))= 0;(标签,聚合氯化铝)= (bestNet、特性)进行分类;%用概率和获胜值更新图% 标签。probaultsplot.ydata = probs;写(预测缓冲,probs);如果predictionBuffer。NumUnreadSamples = = predictionBuffer。容量lastTen = peek(predictionBuffer);[~,决定]= max(平均(lastTen。*损害(大小(lastTen, 1)), 1));probabilityAxes.Title.String = num2str (decision-1);结束结束其他的%如果信号能量低于阈值,假设没有语音%检测。probabilityAxes.Title.String ='';probabilityPlot。YData = 0.1 * 1 (1);analyzedPlot。YData = 0 (f / 2、1);重置(predictionBuffer)结束drawnowlimitrate结束结束
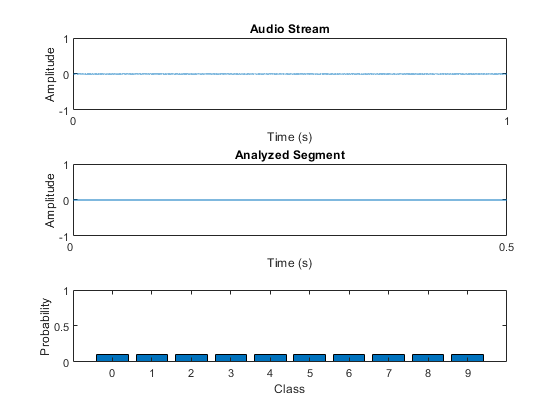
示例的其余部分说明了如何训练用于流检测的网络,以及如何选择输入网络的特征。
创建列车和验证数据集
下载自由语音数字数据集(FSDD)[2].FSDD由短音频文件组成,带有语音数字(0-9)。
url =“https://zenodo.org/record/1342401/files/Jakobovski/free-spoken-digit-dataset-v1.0.8.zip”;downloadFolder = tempdir;datasetFolder = fullfile (downloadFolder,'fsdd');如果〜存在(DataSetFolder,“dir”)流(“下载免费语音数字数据集…\n”解压缩(url, datasetFolder)结束
创建一个audioDatastore指向录音。获取数据集的采样率。
广告= audioDatastore (datasetFolder,'insertumbfolders',真正的);[~, adsInfo] =阅读(广告);fs = adsInfo.SampleRate;
文件名的第一个元素是文件中读出的数字。获取文件名的第一个元素,将它们转换为分类的,然后设置标签财产的audioDatastore.
(~,文件名)= cellfun (@ (x) fileparts (x)的广告。文件,'统一输出'、假);ads.Labels =分类(string (cellfun (@ (x) x(1),文件名)));
要将数据存储分割为开发集和验证集,请使用splitEachLabel.将80%的数据用于开发,其余20%用于验证。
[adsTrain, adsValidation] = splitEachLabel(广告,0.8);
设置音频特征提取器
创建一个audioFeatureExtractor对象提取超过30ms Windows的音频特征,更新速率为10ms。将本例中要测试的所有功能设置为真的.
Win =汉明(圆形(0.03 * fs),“周期”);overlapLength =圆(0.02 * fs);afe = audioFeatureExtractor (......“窗口”, 赢,......'overlaplencth'overlapLength,......“SampleRate”,fs,............“linearSpectrum”假的,......“melSpectrum”假的,......“barkSpectrum”假的,......'erbspectrum'假的,............“mfcc”,真的,......“mfccDelta”,真的,......“mfccDeltaDelta”,真的,......“gtcc”,真的,......“gtccDelta”,真的,......“gtccDeltaDelta”,真的,............'spectralcentroid',真的,......“spectralCrest”,真的,......“spectralDecrease”,真的,......“spectralEntropy”,真的,......“spectralFlatness”,真的,......“spectralFlux”,真的,......'spectarkurtosis',真的,......'spectralrolloffpoint',真的,......'spectrancewswness',真的,......“spectralSlope”,真的,......“spectralSpread”,真的,............“节”假的,......'halmonicratio'、假);
定义图层和培训选项
定义深度学习层列表(深度学习工具箱)和培训选项(深度学习工具箱)在此示例中使用。第一层,sequenceInputlayer.(深度学习工具箱),只是一个占位符。根据您在序列特性选择过程中测试的特性,第一层被替换为sequenceInputlayer.适当的大小。
numUnits =100.;层= [......sequenceInputLayer (1) bilstmLayer (numUnits“outputmode”,“最后一次”) full connectedlayer (numel(categories(adsTrain.Labels))) softmaxLayer classiationlayer];选择= trainingOptions (“亚当”,......“Learnrateschedule”,“分段”,......“洗牌”,“every-epoch”,......“详细”,错误的,......“MaxEpochs”, 20);

连续的特征选择
在序列特征选择的基本形式中,你在一个给定的特征集上训练一个网络,然后逐步增加或删除特征,直到准确率不再提高[1].
提出了选择
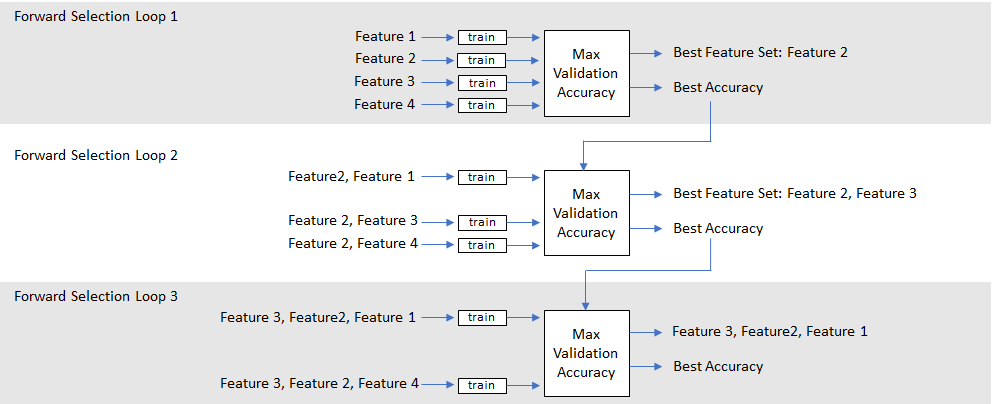
考虑一个简单的情况,对一组四个特性进行正向选择。在第一个前向选择环路中,通过训练网络来独立测试四个特征,并比较它们的验证精度。指出了导致最高验证精度的特征。在第二个向前选择循环中,来自第一个循环的最佳特征与每个剩余的特征相结合。现在每一对特征都用于训练。如果第二个循环中的精度没有比第一个循环中的精度提高,则选择过程结束。否则,将选择一个新的最佳特征集。向前选择循环继续,直到精确度不再提高。
逆向选择
在逆向特征选择中,你首先在一个由所有特征组成的特征集上进行训练,然后测试当你删除特征时准确性是否会提高。

运行顺序特征选择
辅助函数(HelperSFS,HelpertrainAndValidateNetwork, 和HelperTrimOrPad)实现前向或向后顺序特征选择。指定培训数据存储,验证数据存储,音频功能提取器,网络层,网络选项和方向。作为一般规则,如果您预计大型功能集,请选择“前进”或向后选择。
方向= “前进”;(日志,bestFeatures bestNet标准化者]= HelperSFS (adsTrain、adsValidation afe,层,选择,方向);
“前进”;(日志,bestFeatures bestNet标准化者]= HelperSFS (adsTrain、adsValidation afe,层,选择,方向);

使用'local'配置文件启动并行池(parpool)…连接到并行池(工人数量:6)。
的日志输出HelperFeatureExtractor是一个包含所有已测试特性配置和相应验证准确性的表。
日志
日志=48×2表准确度__________________________________ ________ "mfcc, gtcc" 97.333 "mfcc, mfccDelta, gtcc" 97 "mfcc, gtcc, spectralEntropy" 97 "mfcc, gtcc, spectralFlatness" 97 "mfcc, gtcc, spectralSpread" 97 "gtcc" 96.667 "gtcc, spectralCentroid" 96.667 "gtcc, spectralFlux" 96.667 "mfcc, gtcc,spectralRolloffPoint" 96.667 "mfcc, gtcc, spectralSkewness" 96.667 "gtcc, spectralEntropy" 96.333 "mfcc, gtcc, gtccDeltaDelta" 96.333 "mfcc, gtcc, spectralKurtosis" 96.333 "mfccDelta, gtcc" 96 "gtcc, gtccDelta" 96⋮
的bestFeatures输出HelperSFS包含具有设置为的最佳功能的结构真的.
bestFeatures
bestFeatures =结构体字段:mfcc: 1 mfccDelta: 0 mfccDeltaDelta: 0 gtcc: 1 gtccDelta: 0 gtccDeltaDelta: 0 spectralCentroid: 0 spectralCrest: 0 spectralDecrease: 0 spectralEntropy: 0 spectralFlatness: 0 spectralFlux: 0 spectralKurtosis: 0 spectralRolloffPoint: 0 spectralSkewness: 0 spectralSlope: 0 spectralSpread: 0
你可以设置audioFeatureExtractor使用结构体。
安全设置(afe bestFeatures)
Window: [240×1 double] OverlapLength: 160 SampleRate: 8000 FFTLength: [] SpectralDescriptorInput:'linearSpectrum' Enabled Features mfcc, gtcc, barkSpectrum, erbSpectrum, mfccDelta, mfccDeltaDelta gtccDelta, gtccDeltaDelta, spectralCentroid, spectralCrest, spectralDecrease, spectralEntropy, spectralFlatness, spectralFlux, spectralKurtosis, spectralRolloffPoint, spectralSkewness, spectralSkewness,如果要提取一个特征,将对应的属性设置为true。例如,obj。MFCC = true,将MFCC添加到已启用的特性列表中。
HelperSFS还输出最佳性能的网络和对应于所选功能的归一化因子。保存网络,配置audioFeatureExtractor,归一化因素,取消注释这一行:
%保存(“network_Audio_SequentialFeatureSelection.mat”、“bestNet”,“安全的”,“标准化者”)
结论
该示例说明了用于复发性神经网络(LSTM或BILSTM)的顺序特征选择的工作流程。它很容易适用于CNN和RNN-CNN工作流程。
金宝app支持功能
HelpertrainAndValidateNetwork
功能[Truelabels,PredightLabels,Net,Indantmizers] = HelpertrainAndValidateNetwork(adstrain,Adsvalidation,AFE,图层,选项)培训并验证一个网络。%%的输入:% adsTrain -指向训练集的audioDatastore对象% adsValidation - audioDatastore对象,指向验证集%afe - audiofeatureextractor对象。% layers - LSTM或BiLSTM网络的层%选项 - TrainingOptions对象%%输出:% trueLabels -验证集的真标签% predictedLabels -验证集的预测标签%网络培训网络%归一化器-被测特性的归一化因子版权所有2019 The MathWorks, Inc.。%将数据转换为高数组。tallTrain =高(adsTrain);tallValidation =高(adsValidation);%从训练集中提取特征。重新定位功能,以便% time是沿着行,以兼容sequenceInputLayer。FS = AFE.SAMPLEDE;Talltrain = Cellfun(@(x)Helpertrimorpad(x,fs / 2),塔特拉特,“UniformOutput”、假);tallTrain = cellfun (@ x (x) / max (abs (x)、[]“所有”)、tallTrain“UniformOutput”、假);tallFeaturesTrain = cellfun (@ (x)提取(afe x), tallTrain,“UniformOutput”、假);TallFeaturestain = Cellfun(@(x)x',tallfeaturestain,“UniformOutput”、假);%#OK[〜,featureStrain] = evalc(“收集(tallFeaturesTrain)”);%使用evalc抑制命令行输出。tallvalidation = Cellfun(@(x)Helpertrimorpad(x,fs / 2),tallvalidation,“UniformOutput”、假);tallValidation = cellfun (@ x (x) / max (abs (x)、[]“所有”),TallValidation,“UniformOutput”、假);tallFeaturesValidation = cellfun (@ (x)提取(afe x), tallValidation,“UniformOutput”、假);tallFeaturesValidation = cellfun (@ (x) x ', tallFeaturesValidation,“UniformOutput”、假);%#OK [〜,特点过验证] = evalc(“收集(tallFeaturesValidation)”);%使用evalc抑制命令行输出。%使用训练集来确定每一个的平均值和标准差%的特性。规范化培训和验证集。AllFeatures = Cat(2,FeatureStrain {:});m =均值(全部,2,'omitnan');S =性病(allFeatures 0 2,'omitnan');featuresTrain = cellfun (@ (x)(即x m)。/ S, featuresTrain,'统一输出'、假);为i = 1:numel(featuresTrain) idx = find(isnan(featuresTrain{ii}));如果~isempty(idx) featuresTrain{ii}(idx) = 0;结束结束特征idation = Cellfun(@(x)(x-m)./ s,companyvalidation,'统一输出'、假);为idx = find(isnan(featuresValidation{ii}));如果~isempty(idx) featresvalidation {ii}(idx) = 0;结束结束%复制列车和验证集的标签,以便它们在%与序列一一对应。labelsTrain = adsTrain.Labels;%更新输入层,显示被测试特性的数量。层(1)= sequenceInputLayer(大小(featuresTrain {1}, 1));%训练网络。网= trainNetwork (featuresTrain、labelsTrain层,选择);%评估网络。调用classification来获得每个标签的预测值% 顺序。predictedLabels =分类(净,featuresValidation);trueLabels = adsValidation.Labels;%将规范化因子保存为结构体。标准化者。意味着= M;标准化者。StandardDeviation = S;结束
HelperSFS
功能[Logbook,Bestfeatures,BestNet,Bestnormalizers] = allowersfs(adstrain,Adsvalidate,Afethis,图层,选项,方向)%%的输入:% adsTrain -指向训练集的audioDatastore对象%AdsValidate - AudioDataStore对象指向验证集%afe - audiofeatureextractor对象。将所有功能设置为true% layers - LSTM或BiLSTM网络的层%选项 - TrainingOptions对象%方向 - SFS方向,指定为“转发”或“向后”%%输出:%日志-包含功能配置测试和相应的验证准确性的表%bestfeatures - 结构可包含最佳功能配置% bestNet -具有最高验证精度的训练网络% bestnormalizer -最佳特征的特征归一化因子版权所有2019 The MathWorks, Inc.。afe = (afeThis)复印件;featuresToTest =字段名(信息(afe));N =元素个数(featuresToTest);bestValidationAccuracy = 0;%设置初始特性配置:全部打开,向后选择%或全部关闭,用于向前选择。featureConfig = info (afe);为我= 1:n如果strcmpi(方向,“落后”) featureConfig.(featuresToTest{i}) = true;其他的featureconfig。(featureestotest {i})= false;结束结束%初始化日志以跟踪特性配置和准确性。日志=表(featureConfig 0'variablenames',[“功能配置”,“准确性”]);%执行顺序特征评估。Wrapperidx = 1;bestaccuracy = 0;尽管wrapperIdx < = N%创建一个包含所有要测试的特性配置的单元格数组%在当前循环中。featureconfigstotest = cell(numel(featureasttist),1);为2 = 1:元素个数(featuresToTest)如果strcmpi(方向,“落后”) featureConfig.(featuresToTest{ii}) = false;其他的featureconfig。(featureestotest {ii})= true;结束featureconfigstotest {ii} = featureconfig;如果strcmpi(方向,“落后”) featureConfig.(featuresToTest{ii}) = true;其他的featureConfig。(featuresToTest {2}) = false;结束结束%循环遍历每个特性集。为2 = 1:元素个数(featureConfigsToTest)%确定要测试的当前特性配置。更新特性安全。currentConfig = featureConfigsToTest {2};currentConfig集(afe)%列车并获得当前的k折叠交叉验证精度%的功能配置。[Truelabels,PredightLabels,Net,Normanizers] = HelpertrainAndValidateNetwork(adstrain,Adsvalidate,AFE,图层,选项);valaccuracy =平均值(truelabels == predightlabels)* 100;如果valAccuracy > bestValidationAccuracy bestValidationAccuracy = valAccuracy;bestNet =净;bestNormalizers =标准化者;结束%更新日志结果=表(currentConfig valAccuracy,'variablenames',[“功能配置”,“准确性”]);日志=(日志;结果);% #好< AGROW >结束以最佳的精度确定和打印设置。如果精度%没有改善,结束运行。[a,b] = max(日志{:,'准确性'});如果a <= bestAccuracy wrapperIdx = inf;其他的wrapperIdx = wrapperIdx + 1;结束bestAccuracy =一个;%根据最近的获胜者更新特性到测试。获胜者= logbook {b,'功能配置'};fn =字段名(冠军);tf = structfun (@ (x) (x)赢家);如果strcmpi(方向,“落后”) featuresToRemove = fn(~tf);其他的featuresToRemove = fn (tf);结束为ii = 1:numel(featuresToRemove) loc = strcmp(featuresToTest,featuresToRemove{ii});featuresToTest (loc) = [];如果strcmpi(方向,“落后”) featureConfig.(featuresToRemove{ii}) = false;其他的featureConfig。(featuresToRemove {2}) = true;结束结束结束%对日志簿进行排序,使其更具可读性。:日志(1)= [];%删除占位符第一行。logbook = sortrows(logbook,{'准确性'},{“下”});bestFeatures =日志{1,'功能配置'};m =日志{:,'功能配置'};fn =字段名(m);myString =字符串(元素个数(m), 1);为wrapperidx = 1:numel(m)tf = structfun(@(x)(x),logbook {wrapperidx,'功能配置'});myString (wrapperIdx) = strjoin (fn (tf),“,”);结束日志=表(myString日志{:,'准确性'},'variablenames',[“特征”,“准确性”]);结束
HelperTrimOrPad
功能y = helpertrimorpad(x,n)%y = Helpertrimorpad(x,n)修剪或填充输入x到n个样本。如果x是%修剪,它在正面和背面平均修剪。如果x被填充,则是%在前面和后面相等地用零填充。奇数长度的修剪或%填充,从后面修剪或填充额外的样品。版权所有2019 The MathWorks, Inc.。一个=大小(x, 1);如果a < n frontPad = floor((n-a)/2);backPad = n - a - frontPad;(y = 0 (frontPad 1); x; 0(挤压垫,1)];elseifa> n正面=地板((a-n)/ 2)+1;回溯= a - n - fronttrim;y = x(Fronttrim:end-backtrim);其他的y = x;结束结束
参考文献
Jain, A.和D. Zongker。"特征选择:评估、应用和小样本性能"IEEE模式分析与机器智能汇刊。第19卷,第2期,1997年,153-158页。
[2] Jakobovski。“Jakobovski / Free-Spoken-Digit-Dataset。”GitHub, 2019年5月30日。https://github.com/Jakobovski/free-spoken-digit-dataset。
您还可以从以下列表中选择一个网站: