使用高斯混合模型的说话人验证
说话人验证或身份验证的任务是验证一个给定的语音片段是否属于一个给定的说话人。在说话人验证系统中,存在一个所有其他说话人的未知集合,因此,话语属于验证对象的可能性与不属于验证对象的可能性进行比较。这与识别说话人的任务形成对比,在识别任务中,计算每个说话人的可能性,并对这些可能性进行比较。说话人验证和说话人识别都可以是文本依赖或文本独立的。在本例中,您使用高斯混合模型/通用背景模型(GMM-UBM)创建一个依赖文本的说话者验证系统。
显示了GMM-UBM系统的草图:
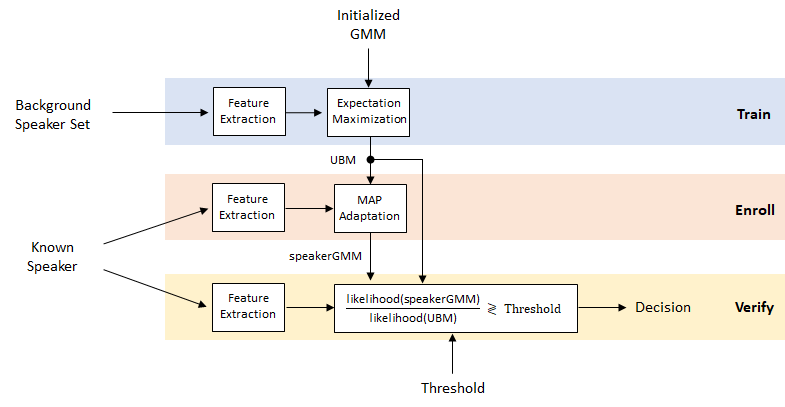
执行扬声器验证
为了实现这个示例,您将首先使用预先训练过的通用背景模型(UBM)执行发言者验证。该模型使用谷歌语音命令数据集中的“stop”进行训练[1].
垫文件,SpeakerverficationExampledata.mat.包括在UBM中,配置audioFeatureExtractor对象,以及用于对特征进行归一化的归一化因子。
负载speakerVerificationExampleData.mat于是afenormFactors
招收
如果您想测试注册自己,请设置enrollYourself来真的.你会被提示录下多次说“停止”。每个提示只说“停止”一次。增加记录的数量可以提高验证的准确性。
enrollYourself =假;如果enrollYourself numToRecord =
5;ID =
“自我”;helperAddUser (afe.SampleRate numToRecord ID);结束



创建一个audioDatastore对象指向本示例中包含的5个音频文件,如果您自己注册了,则指向您刚刚录制的音频文件。本示例中包含的音频文件是内部创建的数据集的一部分,并没有用于训练UBM。
广告= audioDatastore (pwd);
这个例子中包含的文件包括三个不同的人说了五次“停止”这个词:BFn(1),贝克海姆(3)rpalanim.(1).文件名为SpeakerID_RecordingNumber.将数据存储标签设置为相应的扬声器ID。
(~,文件名)= cellfun (@ (x) fileparts (x)的广告。文件,“UniformOutput”,错误的);文件名=分裂(文件名,“_”);扬声器= strcat(文件名(:,1));Ads.Labels =分类(扬声器);
从你的登记注册过程音箱使用所有,但一个文件。剩余文件将用来测试系统。
如果registration = ID;别的enrollLabel =“贝克海姆”;结束forEnrollment = ads.Labels = = enrollLabel;forEnrollment(找到(forEnrollment = = 1,1)) = false;adsEnroll =子集(广告,forEnrollment);adsTest =子集(广告,~ forEnrollment);
注册使用最大后验(MAP)适配所选择的扬声器。你可以找到招生算法的详细信息在后面的例子中.
speakerGMM = helperEnroll(于是,afe、normFactors adsEnroll);
验证
对于测试集中的每个文件,使用似然比检验和阈值来确定说话人是已登记的说话人还是冒名顶替者。
阈值=0.7;重置(adstest)尽管hasdata(adstest)fprintf('身份确认:%s\n',enrollLabel) [audioData,adsInfo] = read(adsTest);流('|扬声器身份:%s \ n',string(adsInfo.Label)) verificationStatus = helperVerify(audioData,afe,normFactors,speakerGMM,ubm,threshold);如果verificationStatus流(“|证实。\ n”);别的流(“|冒名顶替者!\ n”);结束结束

确认证实:BHM
|说话人身份:BFn
|骗子!
确认证实:BHM
|说话人身份:BHm
|确认的。
确认证实:BHM
|扬声器身份:rpalanim
|骗子!
示例的其余部分详细介绍了UBM的创建和注册算法,然后使用常用的报告指标评估系统。
创建通用背景模型
在这个例子中使用的UBM是使用训练[1].下载并提取数据集。
url =“https://storage.googleapis.com/download.tensorflow.org/data/speech_commands_v0.01.tar.gz”;downloadFolder = tempdir;datasetFolder = fullfile (downloadFolder,'google_speech');如果〜存在(DataSetFolder,“dir”)disp(“正在下载谷歌语音命令数据集(1.9 GB)……”)解压(URL,datasetFolder)结束
创建一个audioDatastore这指向了数据集。使用文件夹名称作为标签。文件夹名称指示数据集中说出的单词。
广告= audiodataStore(DataSetFolder,“Includesubfolders”,真的,'labelsource','foldernames');
子集数据集只包含单词“stop”。
广告=子集(广告,ADS.Labels ==分类(“停止”));
将标签设置为文件名中编码的唯一扬声器id。说话人的id有时以数字开头:添加一个“一个”到所有的ID,使名字更加可变友好。
(~,文件名)= cellfun (@ (x) fileparts (x)的广告。文件,“UniformOutput”,错误的);文件名=分裂(文件名,“_”);扬声器= strcat的(“一个”文件名(:1));Ads.Labels =分类(扬声器);
创建三个数据存储:一个用于注册,一个用于评估验证系统,一个用于培训UBM。招募至少有三种发音的演讲者。对于每个说话者,在登记组中放置两句话语。其他的将在测试集中。测试集由数据集中有三个或更多话语的所有说话人的话语组成。UBM训练集由剩余的话语组成。
numSpeakersToEnroll = 10;labelCount = countEachLabel(广告);forEnrollAndTestSet = labelCount {:,1}({labelCount:,2}> = 3);forEnroll = forEnrollAndTestSet(兰迪([1,numel(forEnrollAndTestSet)],numSpeakersToEnroll,1));TF = ismember(ads.Labels,forEnroll);adsEnrollAndValidate =子集(广告,TF);adsEnroll = splitEachLabel(adsEnrollAndValidate,2);adsTest =子集(广告,ismember(ads.Labels,forEnrollAndTestSet));adsTest =子集(adsTest,〜ismember(adsTest.Files,adsEnroll.Files));forUBMTraining =〜(ismember(ads.Files,adsTest.Files)| ismember(ads.Files,adsEnroll.Files)); adsTrainUBM = subset(ads,forUBMTraining);
10;labelCount = countEachLabel(广告);forEnrollAndTestSet = labelCount {:,1}({labelCount:,2}> = 3);forEnroll = forEnrollAndTestSet(兰迪([1,numel(forEnrollAndTestSet)],numSpeakersToEnroll,1));TF = ismember(ads.Labels,forEnroll);adsEnrollAndValidate =子集(广告,TF);adsEnroll = splitEachLabel(adsEnrollAndValidate,2);adsTest =子集(广告,ismember(ads.Labels,forEnrollAndTestSet));adsTest =子集(adsTest,〜ismember(adsTest.Files,adsEnroll.Files));forUBMTraining =〜(ismember(ads.Files,adsTest.Files)| ismember(ads.Files,adsEnroll.Files)); adsTrainUBM = subset(ads,forUBMTraining);

从培训数据存储读取并收听文件。重置数据存储。
[audioData, audioInfo] =阅读(adsTrainUBM);fs = audioInfo.SampleRate;声音(audioData fs)重置(adsTrainUBM)
特征提取
在特征提取管道在这个例子中,您可以:
标准化音频
用
检测从音频中删除非截止区域区域从音频中提取特征
规范化的特点
应用倒相均值归一化
首先,创建一个audioFeatureExtractor对象提取MFCC。指定40 ms的持续时间和10 ms跳跃。
windowDuration = 0.04;hopDuration = 0.01;windowSamples =圆(windowDuration * fs);hopSamples =圆(hopDuration * fs);overlapSamples = windowSamples - hopSamples;afe = audioFeatureExtractor (...'采样率',fs,...'窗户',汉恩(Windowsamples,“周期”),...“OverlapLength”,overlapSamples,......“mfcc”,真正的);
规范化的音频。
audioData = audioData. / max (abs (audioData));
使用检测函数用于定位音频剪辑中的语音区域。调用检测没有任何输出参数进行可视化的语音的检测到的区域。
detectSpeech (audioData fs);

调用检测一次。这一次,返回语音区域的索引,并使用它们从音频剪辑中删除非语音区域。
IDX = detectSpeech(audioData,FS);audioData = audioData(IDX(1,1):IDX(1,2));
调用提炼在这一点audioFeatureExtractor对象以从音频数据提取特征。大小输出提炼是numhops.——- - - - - -numFeatures.
特点=提取(afe audioData);[numHops, numFeatures] =大小(特性)
numHops = 66
numfeatures = 13.
通过全局均值和方差对特征进行归一化。该示例的下一部分将介绍全局均值和方差的计算。现在,只需使用已加载的预计算均值和方差。
features = (features' - normFactors.Mean) ./ normFactors.Variance;
应用局部倒相平均归一化。
feature = feature - mean(feature,'全部');
特征提取管道封装在辅助功能中,helperFeatureExtraction.
计算全局特征归一化因子
从数据集中提取所有功能。如果您有并行计算工具箱™,请确定数据集的最佳分区数,并在可用工人跨越计算。如果您没有并行计算工具箱™,请使用单个分区。
featuresAll = {};如果~ isempty(版本('平行线'))数参= 18;别的numPar = 1;结束
使用辅助函数,helperFeatureExtraction,从数据集中提取所有特征。调用helperFeatureExtraction如果第三个参数为空,则执行中描述的特征提取步骤特征提取除了全球均值和方差的正常化。
parforii = 1:numPar adsPart =分区(ads,numPar,ii);featuresPart =细胞(0,元素个数(adsPart.Files));为iii = 1:numel(adpart . files) audioData = read(adpart);featuresPart {3} = helperFeatureExtraction (afe audioData, []);结束featuresAll = [featuresAll, featuresPart];结束
使用“本地”配置文件启动并行池(Parpool)连接到并行池(工人数:6)。
Allfeatures = Cat(2,包括{:});
计算每个特征的平均值和方差。
normFactors。的意思= (allFeatures 2“omitnan”);normFactors。STD =性病(allFeatures, [], 2,“omitnan”);
初始化GMM
通用背景模型是一种高斯混合模型。定义混合物中组分的数量。[2]建议超过512个文本独立系统。组件权重开始均匀分布。
numComponents = 32;numComponentsα= 1 (1)/ numComponents;
32;numComponentsα= 1 (1)/ numComponents;

对象使用随机初始化亩和σ的每个GMM组件。建立用于存放必要的UBM信息的结构。
μ= randn (numFeatures numComponents);σ=兰德(numFeatures numComponents);于是=结构('ComponentPropopl'α,“亩”亩,“σ”σ);
使用期望最大化训练UBM
使GMM适合于训练集以创建UBM。使用期望最大化算法。
的最大期望算法是递归的。首先,定义停止准则。
maxiter = 20;targetloglikelihie = 0;tol = 0.5;Pastl = -inf;以前的日志可能性初始化
在一个循环中,使用期望最大化算法训练UBM。
抽搐为iter = 1:麦克斯特%的期望N = 0(1、numComponents);F = 0 (numFeatures numComponents);S = 0 (numFeatures numComponents);L = 0;parforII = 1:数参adsPart =分区(adsTrainUBM,数参,ⅱ);尽管hasdata(adsPart)audioData =读(adsPart);%提取特征特点= helperFeatureExtraction (audioData afe normFactors);%计算后验对数似然logLikelihood = helperGMMLogLikelihood(特性,于是);%计算后验概率归一化的logLikelihoodSum = helperLogSumExp (logLikelihood);gamma = exp(logLikelihood - logLikelihood)';%计算Baum-Welch统计n =总和(γ1);F =特征*伽马;S = (feature .*feature) * gamma;%在更新话语充分统计N = N + N;F = F + F;S = S + S;%更新对数似然L = L + sum(loglikehoodsum);结束结束打印当前日志可能性,如果符合条件则停止。L = L /元素个数(adsTrainUBM.Files);流('\ tIteration%d,对数似然=%0.3f \ N'iter,左)如果L > targetLogLikelihood || abs(pastL - L) < tol休息别的pastL = L;结束%最大化N = MAX(N,EPS);ubm.ComponentProportion = MAX(N /总和(N),EPS);ubm.ComponentProportion = ubm.ComponentProportion /总和(ubm.ComponentProportion);ubm.mu = bsxfun(@ rdivide,F,N);ubm.sigma = MAX(bsxfun(@ rdivide,S,N) - ubm.mu. ^ 2,EPS);结束
迭代1,对数似然= -826.174迭代2中,对数似然= -538.546迭代3,对数似然= -522.670迭代如图4所示,对数似然= -517.458迭代如图5所示,对数似然= -514.852迭代6,对数似然= -513.068迭代7,对数似然= -511.644迭代8,对数似然= -510.588迭代9,对数似然= -509.788迭代10,对数似然= -509.135迭代11,对数似然= -508.529迭代12,对数似然= -508.032
流(“UBM训练在%0.2f秒内完成。”toc)
UBM训练以32.31秒完成。
注册:最大后验概率(MAP)估计
一旦有了通用的背景模型,就可以注册扬声器并调整UBM以适应这些扬声器。[2]建议适应相关性因子16.相关因子控制将UBM的每个组件移动到扬声器GMM中的多少。
相关性or = 16;扬声器=唯一(Adsenroll.Labels);NumSpeakers = Numel(扬声器);gmmcellarray = cell(numspeakers,1);抽搐parforII = 1:NumPapers%数据存储的子集到你正在适应的扬声器。adsTrainSubset =子集(adsEnroll adsEnroll.Labels = =扬声器(2));N = 0(1、numComponents);F = 0 (numFeatures numComponents);s =零(NumFeatures,NumComponents);尽管hasdata(adsTrainSubset)audioData =读(adsTrainSubset);特点= helperFeatureExtraction (audioData afe normFactors);[N,F,S,L] = helperExpectation(功能,UBM);N = N + N;F = F + F;S = S + S;结束%确定最大可能性gmm = helperMaximization (N、F、S);%确定自适应系数alpha = N ./ (N + relevanceFactor);%适应手段gmm。亩= alpha.*gmm.mu + (1-alpha).*ubm.mu;%适应变化gmm.sigma = alpha。*(s./n)+(1-alpha)。*(ubm.sigma + ubm.mu. ^ 2) - gmm.mu. ^ 2;gmm.sigma = max(gmm.sigma,eps);%调整权重gmm。ComponentProportion =α。* (N / sum (N)) +(1α)。* ubm.ComponentProportion;gmm。ComponentProportion = gmm.ComponentProportion. /笔(gmm.ComponentProportion);gmmCellArray {2} = gmm;结束流('入学%0.2F秒内完成。\ N'toc)
注册在0.27秒内完成。
记账目的,的GMM的单元阵列转换成一个结构,与所述场是扬声器ID和值是所述GMM结构。
为i = 1:numel(gmmCellArray) enrolledGMMs.(string(speakers(i)))) = gmmCellArray{i};结束
评价
说话人误拒率
扬声器错误拒绝率(FRR)是给定的说话者被错误地拒绝率。使用已知的扬声器设置,以确定一组阈值的扬声器误拒绝率。
扬声器=唯一(Adsenroll.Labels);NumSpeakers = Numel(扬声器);llr =细胞(numSpeakers, 1);抽搐parforSpeakerIDX = 1:NumPeakers LocalGmm =注册仪器。(字符串(扬声器(扬声器))));adstestsubset =子集(adstest,adstest.labels ==扬声器(扬声器));llrperspaeer = zeros(numel(adstestsubset.files),1);为fileidx = 1:numel(adstestsubset.files)audiodata = read(adstestsubset);[x,numframes] = HelperFeatureextraction(AudioData,AFE,符号因素);loglikelihoophy = helpergmloglikelihion(x,localgmm);lspeaker = helperlogsupexp(loglikelihood);loglikelihipe = helpergmloglikelihike(x,ubm);lubm = Helperlogsupexp(loglikelihood);llrperspaeer(fileidx)=均值(MovMedian(Lspeaker - Lubm,3));结束llr {speakerIdx} = llrPerSpeaker;结束流('以%0.2f秒计算的误拒绝率。\n'toc)
假拒绝率在0.20秒内计算。
画出误拒率作为阈值的函数。
llr =猫(1、llr {:});阈值= -0.5:0.01:2.5;FRR =意味着(llr <阈值);情节(阈值,FRR * 100)标题('虚假拒绝率(FRR)')包含(“阈值”)ylabel('错误地拒绝(%)') 网格在

演讲者误接受
讲话者错误接受率(FAR)是指不属于讲话者的话语被错误接受为属于讲话者的比例。使用已知的说话人集来确定一组阈值的说话人FAR。使用与确定FRR相同的阈值集。
speakersTest =独特(adsTest.Labels);llr =细胞(numSpeakers, 1);抽搐parforlocalGMM = enrolledGMMs.(string(speakers(speakerIdx))));adsTestSubset =子集(adsTest adsTest.Labels ~ =扬声器(speakerIdx));llrperspaeer = zeros(numel(adstestsubset.files),1);为fileidx = 1:numel(adstestsubset.files)audiodata = read(adstestsubset);[x,numframes] = HelperFeatureextraction(AudioData,AFE,符号因素);loglikelihoophy = helpergmloglikelihion(x,localgmm);lspeaker = helperlogsupexp(loglikelihood);loglikelihipe = helpergmloglikelihike(x,ubm);lubm = Helperlogsupexp(loglikelihood);llrperspaeer(fileidx)=均值(MovMedian(Lspeaker - Lubm,3));结束llr {speakerIdx} = llrPerSpeaker;结束流('远远超过%0.2f秒。\ n'toc)
FAR的计算时间为22.64秒。
绘制FAR作为阈值的函数。
llr =猫(1、llr {:});远=意味着(llr >阈值);情节(阈值,远* 100)标题(“虚假录取率”)包含(“阈值”)ylabel('错误地拒绝(%)') 网格在

检测错误权衡(DET)
当您在扬声器验证系统中移动阈值时,您需要在FAR和FRR之间进行权衡。这被称为检测错误权衡(DET),通常用于二值分类问题。
x1 = * 100;100日元= FRR *;情节(x1, y1)网格在包含(“误接受率(%)”)ylabel(“误拒率(%)”)标题('检测错误权衡(Det)曲线')

等错误率(EER)
要比较多个系统,您需要一个结合FAR和FRR性能的单一指标。为此,您需要确定等错误率(EER),这是FAR和FRR曲线满足的阈值。在实践中,EER阈值可能不是最好的选择。例如,如果使用说话人验证作为有线传输的多身份验证方法的一部分,FAR很可能比FRR更重要。
[〜,EERThresholdIdx] =分钟(ABS(FAR - FRR));EERThreshold =阈值(EERThresholdIdx);EER =平均值([FAR(EERThresholdIdx),FRR(EERThresholdIdx)]);图(阈值,到目前为止,“k”,...FRR阈值,“b”,...EERThreshold,EER,“罗”,'markerfacecolor',“r”)标题(Sprintf('等错误率=%0.2F,阈值=%0.2F'无论何时,EERThreshold)包含(“阈值”)ylabel('错误率') 传奇(“虚假录取率”,'虚假拒绝率(FRR)',“等错误率(EER)”) 网格在

如果您更改了UBM训练的参数,请考虑使用新的通用背景模型保存MAT文件,audioFeatureExtractor,和规范因子。
重新保存=假;如果重新保存保存(“speakerVerificationExampleData.mat”,'UBM','afe',“normFactors”)结束

金宝app支持功能
将用户添加到数据集
功能helperAddUser (fs, numToRecord ID)%创建的音频设备读取器从音频设备阅读deviceReader = audioDeviceReader ('采样率'fs);%初始化变量numRecordings = 1;audioIn = [];%记录请求的号码尽管numRecordings <= numToRecord fprintf('说' stop '一次(记录%i的%i)…、numRecordings numToRecord)抽搐尽管toc<2 audioIn = [audioIn;deviceReader()];结束流('完整的。\ n')IDX =检测expeech(AudioIn,FS);如果isempty (idx)流('没有检测到的演讲。再试一次。\ n')别的audiowrite (sprintf (“% s_ % i.flac”,ID,numRecordings),audioIn,fs) numRecordings = numRecordings+1;结束[]暂停(0.2);结束%释放设备发行版(deviceReader)结束
招收
功能speakerGMM = helperEnroll(于是,afe、normFactors adsEnroll)%初始化NumComponents = Numel(UBM.ComponentProportProport);numfeatures = size(ubm.mu,1);N = 0(1、numComponents);F = 0 (numFeatures numComponents);S = 0 (numFeatures numComponents);numframes = 0;尽管hasdata (adsEnroll)%从注册数据存储读取audioData =读(adsEnroll);% 1。提取特征并应用特征归一化[特性,numFrames] = helperFeatureExtraction (audioData, afe normFactors);%2.计算后验概率。用它来确定%充分统计(计数,第一和第二时刻)[n,f,s] = HerlErexpation(特征,UBM);% 3。更新足够的统计数据N = N + N;F = F + F;S = S + S;NumFrames = NumFrames + NumFrames;结束%创建期望最大化的高斯混合模型speakerGMM = helperMaximization (N、F、S);%调整UBM以创建扬声器模型。使用关联因子16,%如[2]所提议相关性or = 16;%确定自适应系数alpha = N ./ (N + relevanceFactor);%适应手段speakerGMM。亩= alpha.*speakerGMM.mu + (1-alpha).*ubm.mu;%适应变化speakerGMM。σ= alpha.*(S./N) + (1-alpha).*(ubm.sigma + ubm.mu.^2) - speakerGMM.mu.^2; speakerGMM.sigma = max(speakerGMM.sigma,eps);%调整权重pakeergmm.componentpropoxt = alpha。*(n / sum(n))+(1-alpha)。* ubm.componentproport;pakeergmm.componentpropog mort = speakertmm.componentproport./sum(speakergmm.componentpropofoxt);结束
验证
功能verificationStatus = helperVerify (audioData afe、normFactors speakerGMM,于是,阈值)%提取特征X = helperFeatureExtraction(audioData,AFE,normFactors);%确定数似然的声音来自于GMM适应%演讲者post = helpergmloglikelihion(x,spageertmm);lspeaker = helperlogsumexp(post);%确定音频来自GMM适合所有人的对数可能性%的演讲者交= helperGMMLogLikelihood(X,UBM);Lubm = helperLogSumExp(后);%计算所有帧的比率。应用移动中值过滤器%来去除异常值,然后对所有帧取平均值llr =平均值(movmedian(lspeaker - lubm,3));如果llr > threshold verificationStatus = true;别的verificationStatus = false;结束结束
特征提取
功能(特性,numFrames) = helperFeatureExtraction (afe audioData, normFactors)%正常化audiodata = audiodata / max(abs(audiodata(:)));防nanaudioData (isnan (audioData)) = 0;%隔离语音段%本例中使用的数据集每个audioData有一个单词,如果更多的话%超过一个是语音部分被检测到,只需使用最长%检测。idx =检测echech(audiodata,afe.samplerge);如果Size (idx,1)>1 [~,seg] = max(idx(: 2) - idx(: 1));别的赛格= 1;结束audioData = audioData (idx(赛格,1):idx(赛格,2));%特征提取特点=提取(afe audioData);%功能正常化如果〜的isEmpty(normFactors)设有=(特征-normFactors.Mean ')./ normFactors.STD';结束特征=特征;%倒谱平均值减法(对于信道噪声)如果〜Isempty(符号因素)特征=特征 - 意思(功能,'全部');结束numFrames =大小(功能,2);结束
Log-sum-exponent
功能y = helperLogSumExp (x)%计算对数和指数,避免溢出a = max(x,[],1);y = a + sum(exp(bsxfun(@ minus,x,a)),1);结束
期望
功能[n,f,s,l] = Herverexpation(特征,GMM)Post = Helpergmloglikelihie(特征,GMM);对所有帧的可能性求和L = helperLogSumExp (post);%计算足够的统计数据γ= exp (post-L) ';N =总和(γ1);F =特征*伽马;S = (feature .*feature) * gamma;L = (L)之和;结束
最大化
功能gmm = helperMaximization(N,F,S)gmm。ComponentProportion = max (N / (N),每股收益);gmm。亩= bsxfun(@rdivide,F,N); gmm.sigma = max(bsxfun(@rdivide,S,N) - gmm.mu.^2,eps);结束
高斯多组分混合对数似然
功能L = helperGMMLogLikelihood(x,gmm) xMinusMu = repmat(x,1,1,numel(gmm. componentproportion)) - permute(gmm.mu,[1,3,2]); / /按顺序排列permuteSigma =排列(gmm.sigma[1、3、2]);Lunweighted = -0.5*(sum(log(permuteSigma),1) + sum(bsxfun(@times,xMinusMu,(bsxfun(@rdivide,xMinusMu,permuteSigma)),1) + size(gmm.mu,1)*log(2*pi));temp =挤压(排列(Lunweighted(1、3、2)));如果尺寸(temp,1)== 1%如果只有一帧,则尾随单例维度是%在置换中被移除。这就解释了边缘情况temp = temp ';结束L = bsxfun (@plus、临时、日志(gmm.ComponentProportion) ');结束
参考文献
[1]监狱长P。“语音指令:单字语音识别的公共数据集”,2017。可以从https://storage.googleapis.com/download.tensorflow.org/data/speech_commands_v0.01.tar.gz.版权所有Google 2017.语音命令DataSet在Creative Commons归因4.0许可下许可,可在此处提供:https://creativecommons.org/licenses/by/4.0/legalcode.
[2]雷诺兹,道格拉斯A.,托马斯·F·奎蒂里,和Robert B.邓恩。“说话人确认使用适合高斯混合模型。”数字信号处理10,不。1 - 3(2000): 19-41。https://doi.org/10.1006/dspr.1999.0361.
您还可以从以下列表中选择一个网站: