口语数字识别小波散射和深度学习
这个例子展示了如何使用机器和深度学习技术对语音数字进行分类。在本例中,使用支持向量机(SVM)和长短期记忆(LSTM)网络使用小波时间散射进行分类。金宝app您还可以应用贝叶斯优化来确定合适的超参数,以提高LSTM网络的精度。此外,该示例说明了一种使用深度卷积神经网络(CNN)和梅尔频率谱图的方法。
数据
克隆或下载免费语音数据集(FSDD),可在https://github.com/Jakobovski/free-spoken-digit-dataset。FSDD是一个开放的数据集,这意味着它可以随着时间的推移而增长。本示例使用2019年1月29日提交的版本,该版本包含从4个扬声器获得的2000个数字0到9的英语录音。在这个版本中,两个讲话者的母语是美国英语,一个讲话者是带比利时法语口音的非英语讲话者,一个讲话者是带德国口音的非英语讲话者。数据采样频率为8000 Hz。
使用audioDatastore管理数据访问并确保将记录随机划分为训练集和测试集。设置位置属性设置为计算机上FSDD录音文件夹的位置,例如:
pathToRecordingsFolder = fullfile (tempdir,“free-spoken-digit-dataset-master”,“录音”);位置= pathToRecordingsFolder;
点audioDatastore去那个地方。
广告= audioDatastore(位置);
辅助函数助手标签创建一个从FSDD文件标签的分类排列。对于源代码助手标签列在附录中。列出类和每个类的例子数量。
ads.Labels = helpergenLabels(广告);总结(ads.Labels)
1 300 2 300 3 300 4 300 5 300 6 300 7 300 8 300 9 300
FSDD数据集由10个平衡的类组成,每个类有200个记录。FSDD中的录音时间不等。FSDD并不是非常大,所以读取FSDD文件并构建信号长度的直方图。
LenSig=0(numel(ads.Files),1);nr=1;而hasdata(广告)位数=读(广告);LenSig(NR)= numel(数字);NR = NR + 1;结束重置(广告)直方图(LenSig)网格在包含(的信号长度(样本)) ylabel (“频率”)

直方图显示,记录长度的分布积极地偏斜。对于分类,本示例使用的8192个样本的公共信号长度,保守性值,该值保证了截断较长录音不会切断语音内容。如果信号是长度小于8192个样本(1.024秒)越大,记录被截断为8192个样本。如果信号是长度小于8192个样本,该信号被prepadded并用零出的8192个样本的长度对称postpadded。
小波时间散射
使用waveletScattering(小波工具箱)使用0.22秒的不变比例创建小波时间散射框架。在本例中,通过对所有时间样本的散射变换求平均值来创建特征向量。若要使每个时间窗口的散射系数达到足够的平均值,请设置OversamplingFactor以2以产生散射系数为每个路径相对于所述下采样临界值的数量的四倍的增加。
科幻小说= waveletScattering (“SignalLength”, 8192,'InvarianceScale', 0.22,......“SamplingFrequency”, 8000,“OversamplingFactor”2);
将FSDD分为训练集和测试集。将80%的数据分配给训练集,保留20%给测试集。训练数据用于基于散射变换训练分类器。测试数据用于验证模型。
rng默认;广告=洗牌(广告);[adsTrain,adsTest] = splitEachLabel(广告,0.8);countEachLabel(adsTrain)
ans =10×2表标签计数uuuuuuuuuuuuuuuuuu0 240 1 240 2 240 3 240 4 240 5 240 6 240 7 240 8 240 9 240
计数标签(adsTest)
ans =10×2表标签计数_____ _____ 0 60 1 60 2 60 3 60 4 60 5 60 6 60 7 60 8 60 9 60
辅助函数helperReadSPData截短或数据焊盘到8192的长度,并且通过标准化其最大值每个记录。对于源代码helperReadSPData列在附录中。创建一个8192 × 1600矩阵,其中每一列都是语音数字录音。
Xtrain = [];scatds_Train =变换(adsTrain @ (x) helperReadSPData (x));而hasdata(scatds_Train) smat = read(scatds_Train);Xtrain =猫(2 Xtrain smat);结束
对测试集重复这个过程。得到的矩阵是8192 × 400。
Xtest = [];scatds_Test =变换(adsTest @ (x) helperReadSPData (x));而hasdata(scatds_Test) smat = read(scatds_Test);Xtest =猫(2 Xtest smat);结束
将小波散射变换应用到训练集和测试集。
应变= sf.featureMatrix(Xtrain);STEST = sf.featureMatrix(XTEST);
获取训练集和测试集的平均散射特征。排除零阶散射系数。
TrainFeatures =应变(2:,:,);TrainFeatures =挤压(平均(TrainFeatures, 2))的;TestFeatures =圣(2:,:,);TestFeatures =挤压(平均(TestFeatures, 2))的;
支持向量机分类器
现在,每个记录的数据都已缩减为一个特征向量,下一步是使用这些特征对记录进行分类。创建一个具有二次多项式核的SVM学习者模板。将SVM与训练数据相匹配。
模板= templateSVM (......“KernelFunction”,多项式的,......'PolynomialOrder'2,......“KernelScale”,“自动”,......'BoxConstraint'1,......“标准化”,真正的);classificationSVM = fitcecoc (......TrainFeatures,......adsTrain。标签,......“学习者”模板,......“编码”,'onevsone',......“类名”分类({'0';'1';' 2 ';“3”;“4”;“5”;“6”;“7”;“8”;“9”}));
利用k-fold交叉验证,根据训练数据预测模型的泛化精度。将训练组分成五组。
partitionedModel = crossval (classificationSVM,“KFold”5);[validationPredictions, validationScores] = kfoldPredict(partitionedModel);validationAccuracy = (1 - kfoldLoss(partitionedModel,'LossFun','ClassifError')) * 100
validationAccuracy = 97.4167
估计的泛化精度约为97%。使用训练过的支持向量机来预测测试集中的口语数字类。
predLabels=predict(classificationSVM,TestFeatures);testAccuracy=sum(predLabels==adsTest.Labels)/numel(predLabels)*100
testAccuracy = 97.1667
使用混淆图总结测试集中模型的性能。使用列和行摘要显示每个类别的精度和召回率。混淆图底部的表格显示每个类别的精度值。混淆图右侧的表格显示召回率值。
图(“单位”,“正常化”,“位置”,[0.2 0.2 0.5 0.5]);ccscat = confusionchart (adsTest.Labels predLabels);ccscat。Title =“小波散射分类”;ccscat。ColumnSummary =“列规格化”;ccscat.RowSummary =“row-normalized”;

散射变换结合SVM分类器对测试集中的语音数字进行分类,准确率为98%(或2%的错误率)。
长短期记忆(LSTM)网络
LSTM网络是一种递归神经网络(RNN)。rnn是专门用于处理顺序或时间数据(如语音数据)的神经网络。因为小波散射系数是序列,它们可以作为LSTM的输入。通过使用散射特性而不是原始数据,可以减少网络需要学习的可变性。
修改用于LSTM网络的训练和测试散射特征。排除零阶散射系数并将特征转换为单元阵列。
TrainFeatures =应变(2:,:,);TrainFeatures = squeeze(num2cell(TrainFeatures,[1 2]));TestFeatures =圣(2:,:,);TestFeatures = squeeze(num2cell(TestFeatures, [1 2]));
构建一个具有512个隐藏层的简单LSTM网络。
[inputSize,〜] =尺寸(TrainFeatures {1});YTrain = adsTrain.Labels;numHiddenUnits = 512;numClasses =元素个数(独特(YTrain));层= [......sequenceInputLayer inputSize lstmLayer (numHiddenUnits,“OutputMode”,“最后”) fulllyconnectedlayer (numClasses) softmaxLayer classificationLayer;
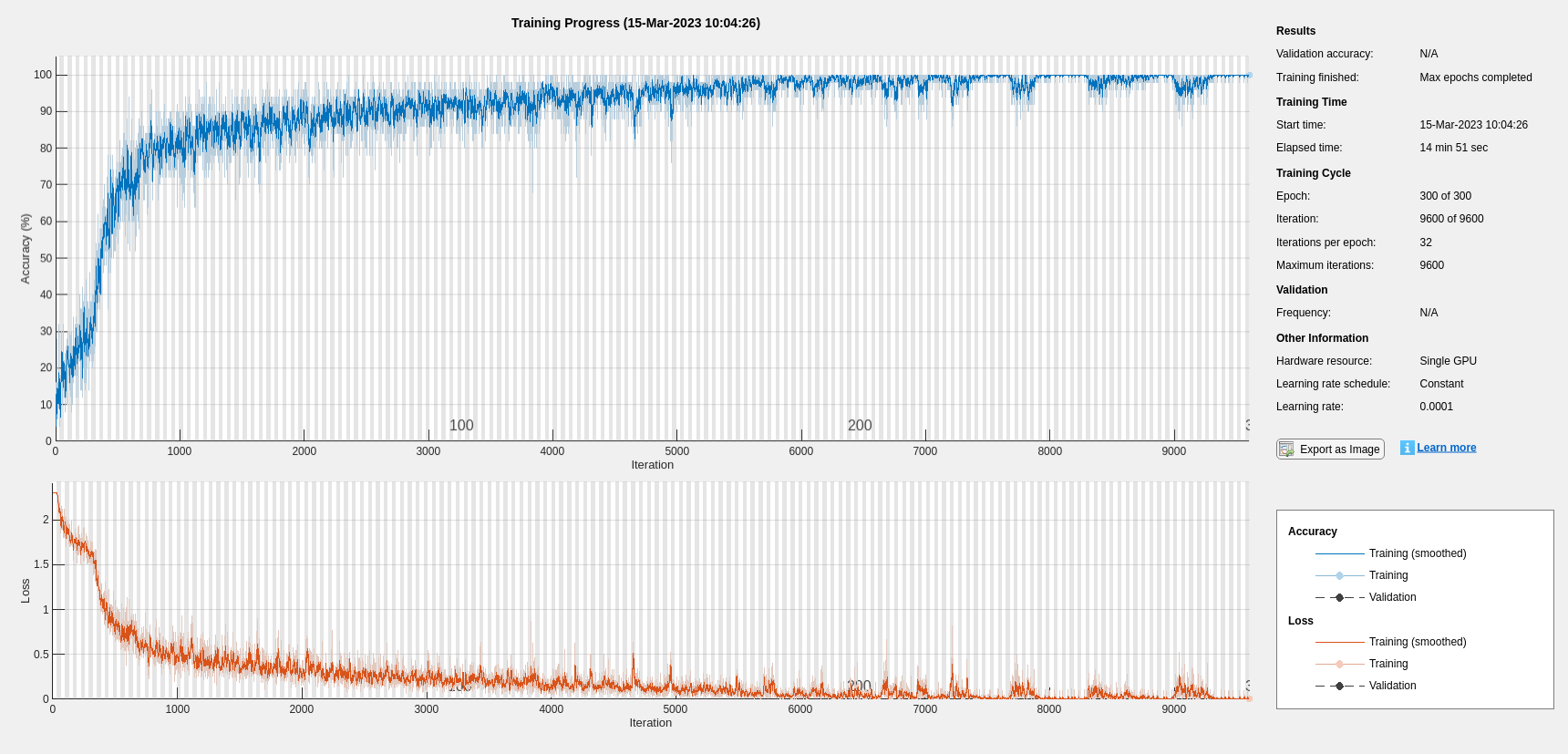
设置超参数。使用Adam优化和最小批量大小50。将最大历元数设置为300。使用1e-4的学习速率。如果不想使用绘图跟踪进度,可以关闭培训进度绘图。默认情况下,如果有GPU可用,培训将使用GPU。否则,它将使用CPU。有关更多信息,请参阅seetrainingOptions(深度学习工具箱).
maxEpochs = 300;miniBatchSize=50;选项=培训选项(“亚当”,......“InitialLearnRate”,0.0001,......'maxepochs',maxEpochs,......“MiniBatchSize”miniBatchSize,......“SequenceLength”,“最短”,......“洗牌”,“every-epoch”,......“详细”假的,......“情节”,'培训 - 进步');
培训网络。
净= trainNetwork(TrainFeatures,YTrain,层,选项);
predLabels =分类(净,TestFeatures);testAccuracy =总和(predLabels == adsTest.Labels)/ numel(predLabels)* 100
testAccuracy = 96.3333
贝叶斯优化
确定合适的超参数设置通常是训练深度网络最困难的部分之一。为了缓解这一问题,您可以使用贝叶斯优化。在本例中,您使用贝叶斯技术优化隐藏层的数量和初始学习率。创建一个新目录来存储包含信息的MAT文件有关超参数设置和网络以及相应错误率的说明。
YTrain = adsTrain.Labels;欧美= adsTest.Labels;如果〜存在(”结果/”,“dir”mkdir)结果结束
初始化要优化的变量及其值范围。因为隐藏层的数量必须是一个整数,设置“类型”到“整数”.
optVars = [optimizablevvariable (“InitialLearnRate”(1 e-5, 1 e 1),“转换”,“日志”)优化变量(“NumHiddenUnits”,[10, 1000],“类型”,“整数”));
贝叶斯优化是计算密集型的,可能需要几个小时才能完成。对于这个例子的目的,集optimizeCondition到假下载和使用预先确定的优化超参数设置。如果你设置optimizeCondition到真正的,目标函数helperBayesOptLSTM使用贝叶斯优化最小化。目标函数,列在附录中,是给定特定超参数设置的网络的错误率。加载设置的目标函数最小值为0.02(2%的错误率)。
ObjFcn=HelperBayesTopLstm(列车特征、YTrain、TestFeatures、YTest);optimizeCondition=false;如果optimizeCondition BayesObject = bayesopt(ObjFcn,optVars,......“MaxObjectiveEvaluations”15岁的......“IsObjectiveDeterministic”假的,......“使用并行”,真的);其他的url =“http://ssd.mathworks.com/金宝appsupportfiles/audio/SpokenDigitRecognition.zip”;downloadNetFolder = TEMPDIR;netFolder =完整文件(downloadNetFolder,“SpokenDigitRecognition”);如果~存在(netFolder“dir”) disp ('下载预训练网络(1文件- 12mb)…'解压缩(url, downloadNetFolder)结束负载(fullfile (netFolder'0.02.mat'));结束
正在下载预训练网络(1个文件-12 MB)。。。
如果执行贝叶斯优化,将生成如下图,以跟踪具有相应超参数值和迭代次数的目标函数值。可以增加贝叶斯优化迭代的次数,以确保达到目标函数的全局最小值。

使用隐藏单元数和初始学习率的优化值,并重新训练网络。
numHiddenUnits = 768;numClasses =元素个数(独特(YTrain));层= [......sequenceInputLayer inputSize lstmLayer (numHiddenUnits,“OutputMode”,“最后”) fulllyconnectedlayer (numClasses) softmaxLayer classificationLayer;maxEpochs = 300;miniBatchSize=50;选项=培训选项(“亚当”,......“InitialLearnRate”2.198827960269379 e-04......'maxepochs',maxEpochs,......“MiniBatchSize”miniBatchSize,......“SequenceLength”,“最短”,......“洗牌”,“every-epoch”,......“详细”假的,......“情节”,'培训 - 进步');净= trainNetwork(TrainFeatures,YTrain,层,选项);predLabels =分类(净,TestFeatures);testAccuracy =总和(predLabels == adsTest.Labels)/ numel(predLabels)* 100
testAccuracy = 97.5000
如图所示,使用贝叶斯优化可以得到精度更高的LSTM。
使用梅尔频率谱图的深度卷积网络
作为另一种方法,以口语数字识别的任务,使用基于梅尔频率频谱深刻的卷积神经网络(DCNN)到FSDD数据集进行分类。使用相同的信号截断/填充的步骤,所述散射变换。类似地,通过由最大绝对值除以每个信号样本归一化每个记录。为了保持一致性,使用相同的训练集和测试集作为散射变换。
设置梅尔频率谱图的参数。使用与散射变换相同的窗口或帧,持续时间为0.22秒。将windows之间的跳转设置为10毫秒。使用40个频段。
segmentDuration = 8192 * (1/8000);frameDuration = 0.22;hopDuration = 0.01;numBands = 40;
重置训练和测试数据存储。
重置(adsTrain);重置(adsTest);
辅助函数helperspeechSpectrograms的定义,使用melSpectrogram对记录长度进行标准化,对振幅进行标准化,得到梅尔频谱图。使用梅尔-频率谱图的对数作为输入到DCNN。为了避免对0取对数,在每个元素上加一个小的。
epsil = 1E-6;XTrain = helperspeechSpectrograms(adsTrain,segmentDuration,frameDuration,hopDuration,numBands);
计算语音谱图……处理了500个文件2400个处理了1000个文件2400个处理了1500个文件2400个处理了2000个文件2400个…完成了
XTrain = log10(XTrain + epsil);XTest = helperspeechSpectrograms (adsTest segmentDuration、frameDuration hopDuration, numBands);
计算语音频谱...加工500个文件出的600 ...完成
XTest = log10(XTest + epsil);YTrain = adsTrain.Labels;欧美= adsTest.Labels;
定义DCNN架构
构造一个小的DCNN作为层的数组。使用卷积和批处理归一化层,并使用最大池化层对特征映射进行向下采样。为了减少网络记忆训练数据的特定特征的可能性,在最后一个完全连接层的输入中添加少量的dropout。
sz=尺寸(XTrain);specSize=sz(1:2);imageSize=[specSize 1];numClasses=numel(类别(YTrain));dropoutProb=0.2;numF=12;layers=[imageInputLayer(imageSize)卷积2dLayer(5,numF,“填充”,“相同”maxPooling2dLayer(3,“大步走”,2,“填充”,“相同”)卷积2层(3,2*numF,“填充”,“相同”maxPooling2dLayer(3,“大步走”,2,“填充”,“相同”) convolution2dLayer(3、4 * numF,“填充”,“相同”maxPooling2dLayer(3,“大步走”,2,“填充”,“相同”) convolution2dLayer(3、4 * numF,“填充”,“相同”) batchNormalizationLayer reluLayer卷积2dlayer (3,4*numF,“填充”,“相同”) batchNormalizationLayer reluLayer maxPooling2dLayer(2) dropoutLayer(dropoutProb) fulllyconnectedlayer (numClasses) softmaxLayer classificationLayer(“类”类别(YTrain));];
设置在训练网络的超参数来使用。使用50迷你批量大小和1E-4的学习速度。指定亚当优化。因为数据的该示例中的量相对较小,设置执行环境,以'中央处理器'您还可以通过将执行环境设置为“图形”或“自动”.有关更多信息,请参阅trainingOptions(深度学习工具箱).
miniBatchSize=50;选项=培训选项(“亚当”,......“InitialLearnRate”,1E-4,......'maxepochs'30岁的......“MiniBatchSize”miniBatchSize,......“洗牌”,“every-epoch”,......“情节”,'培训 - 进步',......“详细”假的,......“ExecutionEnvironment”,'中央处理器');
培训网络。
trainedNet = trainNetwork(XTrain,YTrain,层,选项);
使用经过训练的网络来预测测试集的数字标签。
[Ypredicted,聚合氯化铝]=分类(trainedNet XTest,“ExecutionEnvironment”,'中央处理器');cnnAccuracy = (Ypredicted = =次)/元素个数之和(欧美)* 100
cnnAccuracy = 98.1667
总结在测试组与混乱图表训练网络的性能。显示的精度和通过使用列和行摘要召回为每个类。在混乱图表底部表显示精度值。该表的混乱图表的右侧显示召回值。
图(“单位”,“正常化”,“位置”,[0.2 0.2 0.5 0.5]);ccDCNN = confusionchart(欧美,Ypredicted);ccDCNN。Title =“DCNN的困惑图”;ccDCNN。ColumnSummary =“列规格化”;ccDCNN.RowSummary =“row-normalized”;
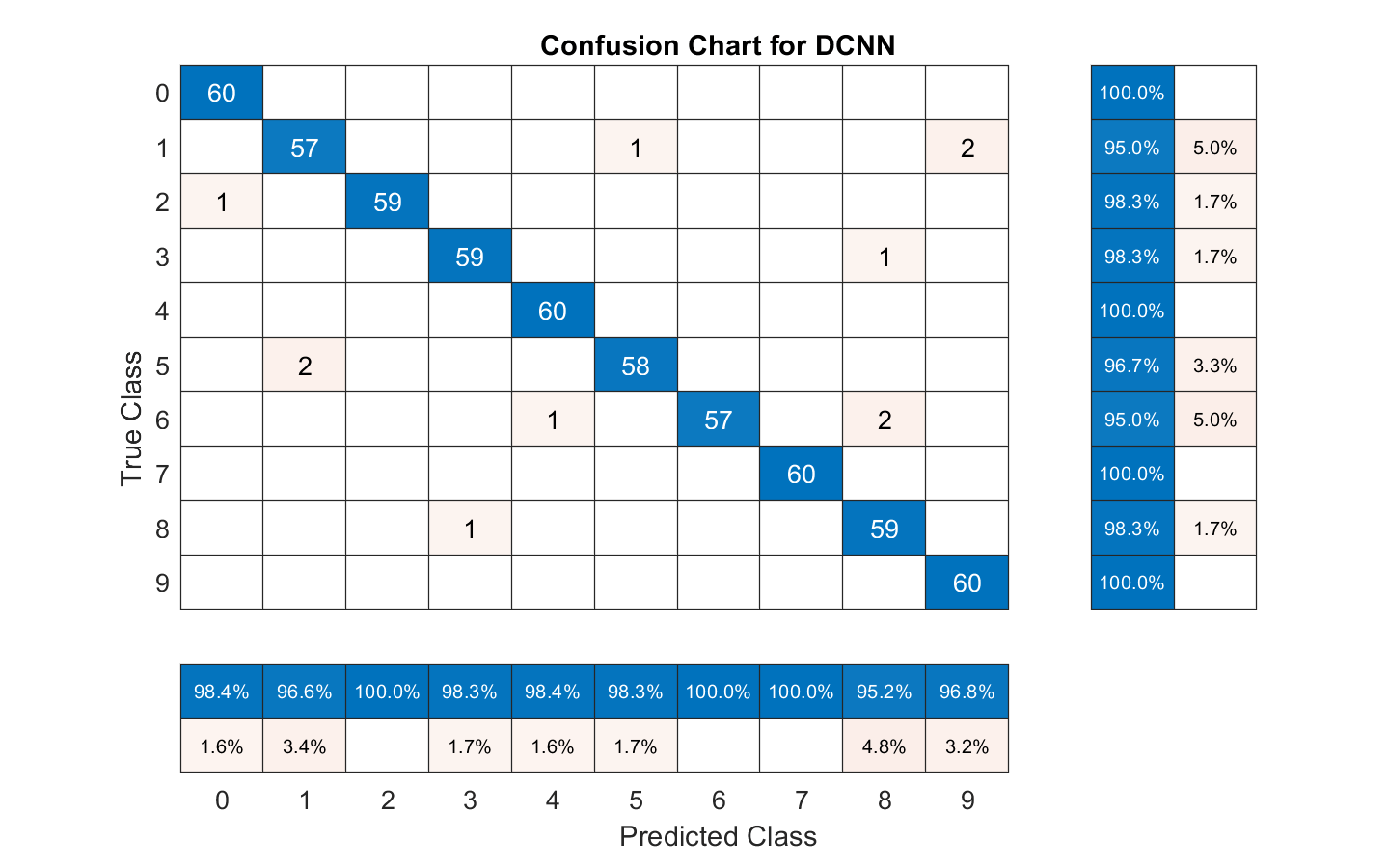
使用梅尔频率谱图作为输入的DCNN对测试集中的语音数字进行分类,准确率约为98%。
总结
这个例子展示了如何使用不同的机器和深度学习方法来分类语音数字在FSDD。该例子说明了小波散射与支持向量机和LSTM的配对。采用贝叶斯方法优化LSTM超参数。最后,示例演示了如何使用带有梅尔频率谱图的CNN。
本示例的目标是演示如何使用MathWorks®工具以根本不同但互补的方式处理问题。所有工作流都使用audioDatastore管理来自磁盘的数据流,并确保适当的随机化。
本例中使用的所有方法在测试集上的表现都相当好。本例不打算在各种方法之间进行直接比较。例如,您也可以在CNN中使用贝叶斯优化进行超参数选择。这是一种额外的策略,在使用小训练集(如本版本)进行深度学习时非常有用FSDD的n是使用数据扩充。操作如何影响类并不总是已知的,所以数据扩充并不总是可行的。然而,对于语音,通过audioDataAugmenter.
在小波时间散射的情况下,你也可以尝试一些修改。例如,您可以改变变换的不变尺度,改变每个滤波器组的小波滤波器数量,并尝试不同的分类器。
附录:辅助函数
函数标签= helpergenLabels(广告)%此函数仅用于小波工具箱示例。它可能是%在未来的版本中更改或删除。TMP =细胞(numel(ads.Files),1);表达式=“[0 - 9]+ _”;为nf = 1:numel(ads.Files) idx = regexp(ads.Files{nf},expression);tmp {nf} = ads.Files {nf} (idx);结束标签=分类(tmp);结束
函数x=helperReadSPData(x)%此函数仅供小波工具箱使用示例。它可能会改变%将在未来的版本中被删除。N=努美尔(x);如果N > 8192 x = x(1:8192);eleesif.N < 8192 pad = 8192-N;前置液=地板(垫/ 2);postpad =装天花板(垫/ 2);X = [0 (prepad,1);x;0 (postpad 1)];结束x=x./最大值(abs(x));结束
函数x = helperBayesOptLSTM(X_train, Y_train, X_val, Y_val)该函数仅用于基于小波散射和深度学习的语音数字识别%它可能会在将来的版本中更改或删除。x = @valErrorFun;函数[valError,cons, fileName] = valErrorFun(optVars)% % LSTM架构[inputSize,〜] =尺寸(X_train {1});numClasses = numel(唯一的(Y_train));层= [......sequenceInputLayer inputSize bilstmLayer (optVars。NumHiddenUnits,“OutputMode”,“最后”)%从优化变量中使用隐藏层的数量fullyConnectedLayer (numClasses) softmaxLayer classificationLayer];%训练期间未显示绘图选择= trainingOptions (“亚当”,......“InitialLearnRate”, optVars。InitialLearnRate,......%从优化变量使用初始学习速率值'maxepochs', 300,......“MiniBatchSize”30岁的......“SequenceLength”,“最短”,......“洗牌”,'绝不',......“详细”、假);训练网络net=列车网络(X\u列车、Y\u列车、层、选项);% %训练精度X_val_P = net.classify(X_val);accuracy_training =总和(X_val_P == Y_val)./ numel(Y_val);valError = 1 - accuracy_training;%%将网络和选项的结果保存在结果文件夹中的MAT文件中,以及错误值文件名= fullfile ('结果'num2str (valError) +“.mat”);保存(文件名,“净”,“valError”,“选项”) cons = [];结束% end用于内部函数结束% end用于外部函数
函数X = helperspeechSpectrograms(广告、segmentDuration frameDuration、hopDuration numBands)该函数仅用于基于小波散射和深度学习的语音数字识别%它可能会在将来的版本中更改或删除。%% helperspeechSpectrograms(广告、segmentDuration frameDuration、hopDuration numBands)%计算的语音频谱用于数据存储的广告文件。%segmentDuration是语音片断的总持续时间(秒),%frameDuration每个谱图帧的持续时间,所述hopDuration%时间偏移在每个谱图帧之间,和numBands的数量%频段。disp (“语音谱图计算……”);numHops=ceil((分段持续时间-帧持续时间)/跳持续时间);numFiles=length(ads.Files);X=zero([numBands,numHops,1,numFiles],“单一”);为i = 1:numFiles [x,info] = read(ads);x = normalizeAndResize (x);fs = info.SampleRate;frameLength =圆(frameDuration * fs);hopLength =圆(hopDuration * fs);规范= melSpectrogram (x, fs,......“窗口”汉明(frameLength“周期性”),......'OverlapLength'frameLength - hopLength......“FFTLength”, 2048,......“NumBands”numBands,......“FrequencyRange”[4000]);%如果声谱图小于numHops,则输入声谱图%X的中间。W =尺寸(规格,2);左地板=((numHops-W)/ 2)+1;IND =左:左+ W-1;X(:,IND,1,I)=规范;如果MOD(I,500)== 0 DISP(“加工”+我+“文件用完了”+(数字文件)结束结束disp (“……完成”);结束%--------------------------------------------------------------------------函数x = normalizeAndResize (x)该函数仅用于基于小波散射和深度学习的语音数字识别%它可能会在将来的版本中更改或删除。N=努美尔(x);如果N > 8192 x = x(1:8192);eleesif.N < 8192 pad = 8192-N;前置液=地板(垫/ 2);postpad =装天花板(垫/ 2);X = [0 (prepad,1);x;0 (postpad 1)];结束x=x./最大值(abs(x));结束
版权所有2018,The MathWorks, Inc.
你也可以从以下列表中选择一个网站: