使用GPU结束到最终系统仿真加速度
此示例显示了四种技术的比较,该技术可用于使用Matlab®CommunicationGoolbox™软件中的系统对象加速误码率(BER)仿真。基于卷积编码的小系统说明了使用MATLAB®Coder™产品,并行循环执行使用的代码生成的效果par在并行计算工具箱™产品中,代码生成和par和基于GPU的系统对象。
系统对象此示例功能可用于通信工具箱产品。为了运行此示例,您必须具有MATLAB编码器许可证,并行计算工具箱许可证和足够的GPU。
系统设计与仿真参数
此示例使用简单的卷积编码系统来说明仿真加速度策略。系统使用随机消息比特使用兰迪.发射机使用速率为1/2的卷积编码器对这些比特进行编码,应用QPSK调制方案,然后传输这些符号。这些符号通过一个AWGN通道,信号损坏在这里发生。QPSK解调发生在接收机,并使用维特比算法解码损坏的比特。最后计算了误码率。系统中使用的System对象有:
comm.conoloolvolutionalencoder - 卷积编码
Comm.pskmodulator - QPSK调制
comm.awgnchannel - Awgn频道
Comm.pskdemodulator - QPSK解调(约LLR)
Comm.ViterBideCoder - Viterbi解码
收发器的代码可以找到:
沿误码率曲线的每个点表示上述收发器代码的许多迭代的结果。为了在合理的时间内获得准确的结果,模拟将收集每个信噪比(SNR)值(SNR)值的至少200位误差,并且在大多数5000数据包中。数据包代表2000个消息位。SNR为1 dB至5 dB。
Itercntthreshold = 5000;minerrthreshold = 200;MSGL = 2000;SNRDB = 1:5;
初始化
调用收发器函数一次以定量设置时间和对象构建开销。对象在每个功能中存储在持久变量中。
错误=零(长度(SNRDB),1);erats =零(长度(snrdb),1);Berplot = Cell(1,5);numframes = 500;%GPU版本并行运行500帧。viterbiTransceiverCPU(-10年,1,1);viterbiTransceiverGPU(-10、1、1、numframes);N = 1;%N跟踪哪个模拟变量正在运行
工作流程
此示例的工作流程是:
运行系统对象的基线模拟
使用MATLAB编码器生成一个MEX函数进行仿真
使用parcol并行运行误码率仿真
将生成的MEX功能与Parcol结合起来
使用基于GPU的系统对象
FPRINTF(1,“误码率加速分析示例\n\n”);
基线模拟
为建立各种加速度策略的参考点,仅使用System对象生成误码率曲线。无线电收发机的密码已经输入了viterbiTransceiverCPU.m.
FPRINTF(1,'***基线 - 标准系统对象模拟*** \ n');%为每个SNRDB仿真创建随机流s = randstream.create('MRG32K3A'那“NumStreams”, 1......'celloutpul',真的,“NormalTransform”那“反转”);RandStream.setGlobalStream (s {1});ts = tic;为了II = 1:NUMER(SNRDB)FPRINTF(1,'迭代数%d,信噪比(dB) = %d\n'第二,snrdb (ii));[errs(ii),iter (ii)] = viterbitranscivercpu (snrdb(ii), minErrThreshold, iterCntThreshold);结尾BER = ERRS./(MSGL * erters);baseTime = toc (ts);berplot {N} = 1;desc {n} =“基线”;ReportResultScommsysGPU(N,Basetime,Basetime,“基线”);
代码生成
使用MATLAB编码器,可以使用优化的C代码生成MEX文件,该代码与预编译的MATLAB代码匹配。因为Viterbitransceivercpu.功能符合MATLAB代码生成子集,可以编译成MEX功能而无需修改。
您必须拥有MATLAB编码器许可证来运行该示例的此部分。
FPRINTF(1,' \ n * * *基线+ codegen * * * \ n”);n = n + 1;%增加模拟计数器%创建编码器对象并关闭检查会导致低电平% 表现。FPRINTF(1,'生成代码......');config_obj = coder.config (墨西哥人的);config_obj.enabledebugging = false;config_obj.integryChecks = false;config_obj.responsiventsChecks = false;config_obj.echoExpressions = false;%生成MEX文件Codegen(“viterbiTransceiverCPU.m”那'-config'那“config_obj”那'-args', {snrdb(1), minErrThreshold, iterCntThreshold})“。\ n”);%运行一次以消除启动开销。viterbiTransceiverCPU_mex(-10年,1,1);s = RandStream.getGlobalStream;重置(年代);%使用生成的MEX函数viterbitranscivercpu_mex%模拟循环。ts = tic;为了II = 1:NUMER(SNRDB)FPRINTF(1,'迭代数%d,信噪比(dB) = %d\n'第二,snrdb (ii));[errs(ii),erers(ii)] = Viterbitransceivercpu_mex(SNRDB(II),MinerRreshold,Itercntthreshold);结尾BER = ERRS./(MSGL * erters);trialtime = toc(ts);berplot {N} = 1;desc {n} ='codegen';reportResultsCommSysGPU (N trialtime baseTime'基线+ codegen');
Parfor—并行循环执行
使用par,Matlab并行地执行所有SNR值的收发器代码。这需要打开并行池并添加一个par环形。
您必须具有并行计算工具箱许可证来运行该示例的此部分。
FPRINTF(1,' \ n * * *基线+ parfor * * * \ n”);FPRINTF(1,'访问多个CPU核心... \ n');如果isempty (gcp (“nocreate”pool =游泳池;poolWasOpen = false;其他的池= GCP;poolwasopen = true;结尾nw = pool.numworkers;n = n + 1;%增加模拟计数器snrn = numel(snrdb);mt = minerrthreshold / nw;它= Itercntthreshold / nw;errn = zeros(nw,snrn);ITRN = Zeros(NW,SNRN);%复制SNRDB.snrdb_rep = repmat (snrdb, nW, 1);%为每个工人创建一个独立的流s = randstream.create('MRG32K3A'那“NumStreams”,nw,......'celloutpul',真的,“NormalTransform”那“反转”);%跑前parjj = 1:西北RandStream.setGlobalStream (s {jj});viterbiTransceiverCPU(-10年,1,1);结尾FPRINTF(1,'开始吧...');ts = tic;parjj = 1:西北为了II = 1:SNRN [ERR,ITR] = ViterbitransceiverCPU(SNRDB_REP(JJ,II),MT,IT);errN (jj, ii) =犯错;ITRN(JJ,II)= ITR;结尾结尾BER = SUM(ERRN)./(MSGL * SUM(ITRN));trialtime = toc(ts);FPRINTF(1,'完成。\ n');berplot {N} = 1;desc {n} =“议定书”;reportResultsCommSysGPU (N trialtime baseTime'基线+ parcon');
议程和代码生成
您可以结合使用最后两种技术来获得额外的加速。编译后的MEX函数可以在par环形。
您必须拥有MATLAB编码器许可证和并行计算工具箱许可证才能运行示例的这一部分。
FPRINTF(1,'\ n ***基线+ codegen + parcom *** \ n');n = n + 1;%增加模拟计数器%跑前parjj = 1:西北RandStream.setGlobalStream (s {jj});viterbiTransceiverCPU_mex (1 1 1);%使用相同的mex文件结尾FPRINTF(1,'开始吧...');ts = tic;parjj = 1:西北为了ii=1:snrN [err, itr] = viterbiTransceiverCPU_mex(snrdb_rep(jj,ii), mT, iT);errN (jj, ii) =犯错;ITRN(JJ,II)= ITR;结尾结尾BER = SUM(ERRN)./(MSGL * SUM(ITRN));trialtime = toc(ts);FPRINTF(1,'完成。\ n');berplot {N} = 1;desc {n} =“codegen + parfor”;reportResultsCommSysGPU (N trialtime baseTime'基线+ codegen + parcol');
GPU.
系统对象Viterbitransceivercpu.功能使用可在GPU上执行。基于gpu的版本包括:
convolutionalencoder—卷积编码
comm.gpu.pskmodulator - QPSK调制
com .gpu. awgnchannel—AWGN通道
comm.gpu.pskdemodulator - QPSK解调(约LLR)
comm.gpu.viterbidecoder - Viterbi解码
在一次处理大量数据时,GPU最有效。基于GPU的系统对象可以在单个呼叫中处理多个帧对步骤方法。这numframes.变量表示每个呼叫处理的帧数。这是类似的par除了并行度是基于每个对象,而不是perViterbitransceivercpu.呼叫基础。
您必须具有并行计算工具箱许可证和CUDA®1.3能够的GPU运行该示例的这一部分。
FPRINTF(1,' \ n * * * * * * GPU \ n”);n = n + 1;%增加模拟计数器试一试dev = parallel.gpu.gpudevice.current;FPRINTF(......'检测到GPU(%s,%d多处理器,计算能力%s)\ n'那......dev.Name、dev.MultiprocessorCount dev.ComputeCapability);sg = parallel.gpu.RandStream.create ('MRG32K3A'那“NumStreams”, 1“NormalTransform”那“反转”);parallel.gpu.RandStream.setGlobalStream (sg);ts = tic;为了II = 1:NUMER(SNRDB)FPRINTF(1,'迭代数%d,信噪比(dB) = %d\n'第二,snrdb (ii));[errs(ii),iter (ii)] = viterbitranssceivergpu (snrdb(ii), minErrThreshold, iterCntThreshold, numframes);结尾BER = ERRS./(MSGL * erters);trialtime = toc(ts);berplot {N} = 1;desc {n} =“图形”;reportResultsCommSysGPU (N trialtime baseTime“基数+ GPU”);FPRINTF(1,“。\ n”);抓%#OK%报告未找到适当的GPU。FPRINTF(1,['找不到合适的GPU或不能'那......'执行GPU代码。\ n']);结尾
分析
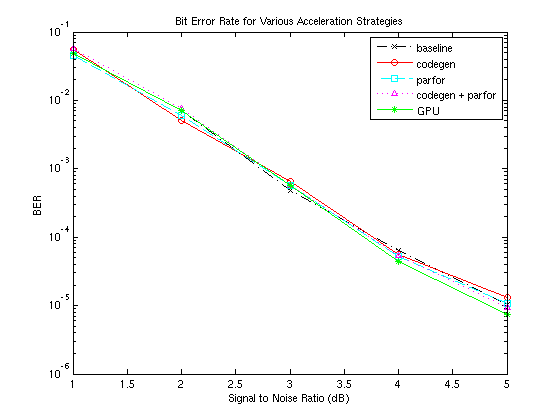
比较这些试验的结果,很明显,GPU比任何其他模拟加速技术都要快得多。这种性能提升需要对模拟代码进行非常温和的更改。然而,比特误码率性能没有损失,如下图所示。曲线上的微小差异是由于不同的随机数生成算法和/或对曲线上同一点的不同数量的数据进行平均的影响。
行= {“kx -。”那“ro - - - - - -”那'CS - '那“m ^:”那'G*-'};为了II = 1:Numel(DESC)半径(SNRDB,Berplot {II},行{II});抓住在;结尾抓住从;标题(“各种加速策略的误码率”);Xlabel(“信噪比(dB)”);ylabel('BER');传奇(DESC {:});
清理
将平行池留在原始状态。
如果〜poolwasopen删除(GCP);结尾
你也可以从以下列表中选择一个网站:
