监控GAN培训进度,识别常见故障模式
培训GANs可能是一项具有挑战性的任务。这是因为发生器和鉴别网络在训练过程中相互竞争。事实上,如果一个网络学习得太快,那么另一个网络可能无法学习。这通常会导致网络无法收敛。为了诊断问题并在0到1的范围内监控生成器和鉴别器实现各自目标的程度,您可以绘制它们的分数。有关如何训练GAN并绘制生成器和鉴别器分数的示例,请参见训练生成对抗网络(GAN)。
鉴别器学习将输入图像分类为“真实”或“生成”。鉴别器的输出对应于一个概率 输入的图像属于类“real”。
生成器得分是所生成图像的鉴别器输出对应概率的平均值:
在哪里 包含生成图像的概率。
考虑到 是图像属于“生成”类的概率,判别器得分是输入图像属于正确类的概率的平均值:
在哪里 包含真实图像的鉴别器输出概率,并且传递给鉴别器的真实图像和生成图像的数量相等。
在理想情况下,两个分数都是0.5。这是因为鉴别器不能区分真假图像。然而,在实践中,这种场景并不是您能够获得成功的GAN的唯一情况。
为了监控训练的进展,你可以随着时间的推移直观地检查图像,并检查它们是否在改善。如果图像没有改善,那么您可以使用评分图来帮助诊断一些问题。在某些情况下,分数图可以告诉您继续培训没有意义,您应该停止,因为已经发生了一个失败模式,培训无法恢复。以下部分将告诉您在得分图和生成的图像中寻找什么,以诊断一些常见的故障模式(收敛故障和模式崩溃),并建议您可以采取哪些行动来改进训练。
收敛失败
在训练过程中,当发生器和鉴别器不能达到平衡时,就会发生收敛失败。
鉴频器占主导地位
当生成器得分达到0或接近0,而鉴别器得分达到1或接近1时,就会发生这种情况。
这幅图显示了鉴别器压倒发电机的一个例子。请注意,生成器的得分接近于零,并且不能恢复。在这种情况下,鉴别器正确地分类了大部分图像。反过来,发生器不能产生任何欺骗鉴别器的图像,因此无法学习。
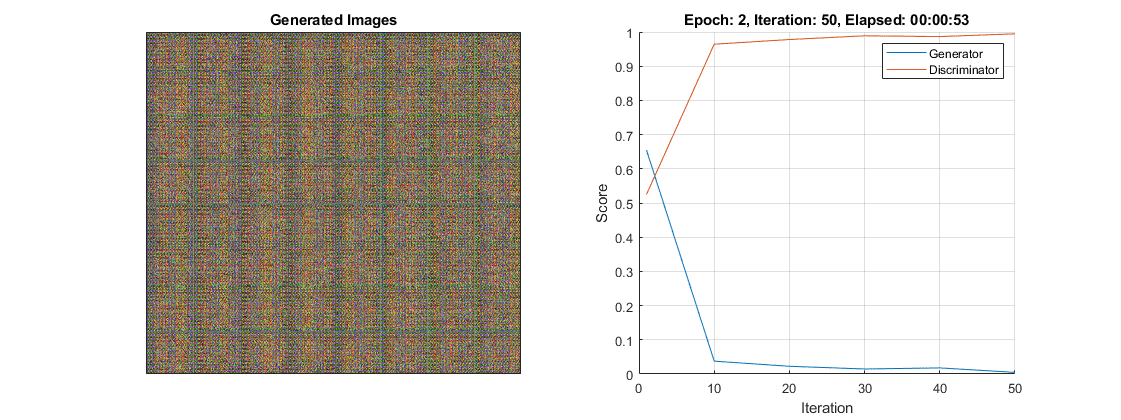
如果在多次迭代中,分数没有从这些值中恢复过来,那么最好停止训练。如果发生这种情况,那么尝试通过以下方法平衡生成器和鉴别器的性能:
通过给真实图像随机提供虚假标签来损害鉴别器(单侧标签翻转)
通过添加辍学层来损害鉴别器
通过增加卷积层中滤波器的数量来提高生成器创建更多特征的能力
通过减少滤波器的数量而损害鉴别器
有关如何翻转真实图像的标签的示例,请参见训练生成对抗网络(GAN)。
发电机占主导地位
当生成器得分达到1或接近1时,就会出现这种情况。
这幅图显示了一个发电机压倒鉴别器的例子。请注意,在多次迭代中,生成器得分变为1。在这种情况下,生成器几乎总是学会如何欺骗鉴别器。当这种情况发生在训练过程的早期,生成器很可能学习一个非常简单的特征表示,这很容易欺骗鉴别器。这意味着生成的图像可能非常差,尽管有很高的分数。注意,在这个例子中,鉴别器的分数并不是非常接近于零,因为它仍然能够正确地分类一些真实的图像。
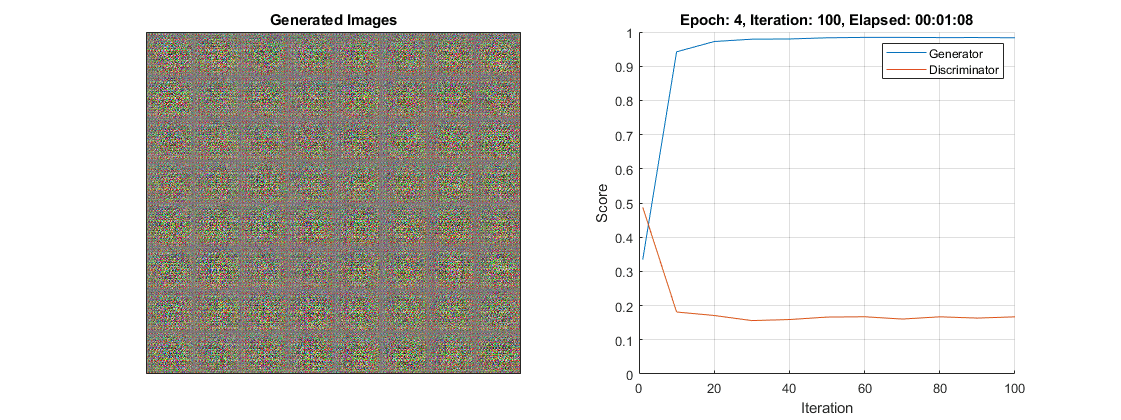
如果在多次迭代中,分数没有从这些值中恢复过来,那么最好停止训练。如果发生这种情况,那么尝试通过以下方法平衡生成器和鉴别器的性能:
通过增加滤波器的数量来提高鉴别器学习更多特征的能力
通过添加辍学层削弱生成器
通过减少滤波器的数量而损害发电机
模式崩溃
模式崩溃是指GAN产生具有许多重复(模式)的少量图像。当生成器无法学习丰富的特征表示时,就会发生这种情况,因为它学会将类似的输出与多个不同的输入关联起来。要检查模式崩溃,请检查生成的图像。如果输出的多样性很小,而且其中一些几乎是相同的,那么就可能存在模态崩溃。
这幅图显示了模态崩溃的一个例子。请注意,生成的图像图包含许多几乎相同的图像,尽管生成器的输入是不同的和随机的。
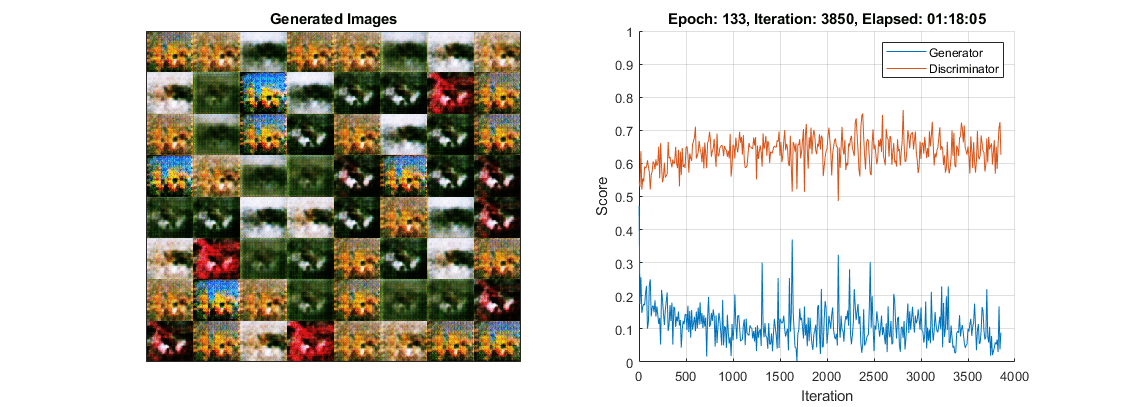
如果你观察到这种情况的发生,那么试着通过以下方法来提高发电机的能力,从而创造出更多不同的输出:
向生成器增加输入数据的维度
增加生成器的过滤器数量,以允许它生成更广泛的各种功能
通过给真实图像随机提供虚假标签来损害鉴别器(单侧标签翻转)
有关如何翻转真实图像的标签的示例,请参见训练生成对抗网络(GAN)。
另请参阅
adamupdate|dlarray|dlfeval|dlgradient|dlnetwork|向前|预测
相关的话题
你也可以从以下列表中选择一个网站:
