训练条件生成对抗网络(CGAN)
这个例子展示了如何训练一个条件生成对抗网络来生成图像。
生成式对抗网络(generative adversarial network, GAN)是一种深度学习网络,它可以生成与输入训练数据具有相似特征的数据。
GAN由两个一起训练的网络组成:
发电机 - 给定随机值的向量作为输入,该网络生成具有与训练数据相同结构的数据。
鉴别器 - 包含来自两个训练数据的观察,并且产生的数据从数据发生器的给定批次中,该网络试图观测作为分类
“真正的”或“生成”。

A.有条件的生成式对抗网络(generative adversarial network, CGAN)是一种在训练过程中利用标签的GAN。
发电机 - 给定标签和随机数组作为输入,该网络生成具有与与相同标签对应的训练数据观察相同结构的数据。
鉴别器——给定一批包含训练数据和生成器生成数据的观测值的标记数据,该网络试图将这些观测值分类为
“真正的”或“生成”。

为了训练一个有条件的GAN,需要同时训练两个网络,以使两个网络的性能最大化:
火车生成器生成“愚弄”鉴别者的数据。
训练鉴别器区分真实数据和生成数据。
为了最大限度地提高发生器的性能,当给定所生成的标记数据时,最大限度地提高鉴别器的损耗。也就是说,生成器的目标是生成鉴别器分类的标记数据“真正的”。
为了最大限度地提高鉴别器的性能,当给定几批真实数据和生成的标记数据时,尽量减少鉴别器的损失。也就是说,鉴别器的目的是不被生成器“愚弄”。
理想情况下,这些策略会产生一个生成器,生成与输入标签相对应的令人信服的真实数据,以及一个已经学习了每个标签的训练数据特征的强特征表示的鉴别器。
负荷训练数据
下载并提取鲜花数据集[1]。
URL =.“http://download.tensorflow.org/example_images/flower_photos.tgz”;downloadFolder = tempdir;文件名= fullfile (downloadFolder,“flower_dataset.tgz”);imageFolder = fullfile (downloadFolder,“flower_photos”);如果~存在(imageFolder“目录”) disp (“花下载数据集(218 MB)......”) websave(文件名,url);解压(文件名,downloadFolder)结束
创建一个包含鲜花照片的图像数据存储。
datasetFolder = fullfile (imageFolder);imd = imageDatastore (datasetFolder,...“IncludeSubfolders”,真的,...“LabelSource”那“foldernames”);
查看类个数。
类=类别(imds.Labels);numClasses = numel(类)
numclasses = 5
增加数据以包括随机水平翻转,并将图像大小调整为64 * 64。
增量= imageDataAugmenter ('RandXReflection',真正的);augimds = augmentedImageDatastore([64 64],imds,'dataaugmentation',增强因子);
定义发电机网络
定义下面的双输入网络,它生成图像给定大小为100的随机向量和相应的标签。

这个网络:
尺寸100的随机向量转换为4×4×1024阵列。
将分类标签转换为嵌入向量,并将其重塑为4乘4数组。
串接从沿着通道维度中的两个输入端所得到的图像。输出是一个4×4×1025阵列。
Upscales所得阵列64由64×3使用一系列与批标准化和RELU层转置卷积层的阵列。
将此网络架构定义为一个层图,并指定以下网络属性。
对于分类输入,使用50的嵌入维。
用于转置卷积层,指定为5×5的过滤器对每个层数目减少的滤波器,2的步幅,和
“相同”产量的裁剪。对于最终的转置卷积层,指定一个3个5 × 5滤波器,对应生成图像的3个RGB通道。
在网络的末端,包括一个tanh层。
要投射和重塑噪声输入,使用自定义层projectAndReshapeLayer,附连到本实施例中作为支撑文件。金宝app当projectAndReshapeLayer对象使用完全连接的操作放大输入并将输出重塑为指定的大小。
要将标签输入网络,请使用featureInputLayer对象,并指定一个功能。嵌入和重塑标签输入,使用自定义层embedAndReshapeLayer,附连到本实施例中作为支撑文件。金宝app当embedAndReshapeLayer对象转换使用嵌入和完全连接的操作的分类标签到指定的尺寸的一个通道的图像。
numlattentinputs = 100;EmbeddingDimension = 50;numFilters = 64;filterSize = 5;projectionsize = [4 4 1024];tallersgenerator = [featureinputlayer(numlatentinputs,'名字'那“噪音”)ProjectAndreshapelayer(Projectionsize,NumlattentInputs,'名字'那'proj');concatenationLayer (3 2'名字'那“猫”);transposedConv2dLayer (filterSize 4 * numFilters,'名字'那“tconv1”) batchNormalizationLayer ('名字'那“bn1”)剥离('名字'那'relu1') transposedConv2dLayer (2 * numFilters filterSize,'走吧'2,“裁剪”那“相同”那'名字'那“tconv2”) batchNormalizationLayer ('名字'那“bn2”)剥离('名字'那“relu2”) transposedConv2dLayer (filterSize numFilters,'走吧'2,“裁剪”那“相同”那'名字'那“tconv3”) batchNormalizationLayer ('名字'那“bn3”)剥离('名字'那“relu3”) transposedConv2dLayer (filterSize 3'走吧'2,“裁剪”那“相同”那'名字'那“tconv4”)tanhLayer('名字'那的双曲正切));lgraphGenerator = layerGraph (layersGenerator);[featureInputLayer(1,'名字'那“标签”)EmbedandReshapelayer(投影化(1:2),EmbeddingDimension,Numcrasses,'名字'那“循证”));lgraphGenerator = addLayers (lgraphGenerator层);lgraphGenerator = connectLayers (lgraphGenerator,“循证”那“猫/平方英寸”);
要使用自定义训练循环训练网络并启用自动分化,将图层图转换为adlnetwork.对象。
dlnetGenerator = dlnetwork (lgraphGenerator)
dlnetGenerator =带有属性的dlnetwork: Layers: [16×1 net.cnn.layer. layer] Connections: [15×2 table] Learnables: [19×3 table] State: [6×3 table] InputNames: {'noise' 'labels'} OutputNames: {'tanh'}
定义鉴别器网络
定义以下双输入网络,它对给定的一组图像和相应的标签进行分类并生成64 × 64图像。

创建一个网络,以64 × 64 × 1图像和相应的标签作为输入,并使用一系列带有批处理归一化和泄漏ReLU层的卷积层输出标量预测评分。使用dropout为输入图像添加噪声。
对于丢弃层,请指定丢弃概率为0.75。
对于卷积层,指定5 × 5滤波器,并为每个层增加滤波器的数量。还指定步幅为2和每个边的输出填充。
对于泄漏RELU层,指定0.2的比例。
对于最后一层,指定一个带有4 × 4滤波器的卷积层。
dropoutProb = 0.75;numFilters = 64;规模= 0.2;inputSize = [64 64 3];filterSize = 5;layersDiscriminator = [imageInputLayer(inputSize,“归一化”那“没有”那'名字'那“图像”)dropoutLayer(dropoutProb,'名字'那“辍学”) concatenationLayer (3 2'名字'那“猫”)convolution2dLayer(filterSize,numFilters,'走吧'2,“填充”那“相同”那'名字'那“conv1”)漏髓范围(秤,'名字'那'lrelu1') convolution2dLayer (2 * numFilters filterSize,'走吧'2,“填充”那“相同”那'名字'那“conv2”) batchNormalizationLayer ('名字'那“bn2”)漏髓范围(秤,'名字'那“lrelu2”) convolution2dLayer (filterSize 4 * numFilters,'走吧'2,“填充”那“相同”那'名字'那“conv3”) batchNormalizationLayer ('名字'那“bn3”)漏髓范围(秤,'名字'那“lrelu3”) convolution2dLayer (filterSize 8 * numFilters,'走吧'2,“填充”那“相同”那'名字'那“conv4”) batchNormalizationLayer ('名字'那“bn4”)漏髓范围(秤,'名字'那'lrelu4'1) convolution2dLayer(4日,'名字'那“conv5”));lgraphDiscriminator = layerGraph (layersDiscriminator);[featureInputLayer(1,'名字'那“标签”)EmbedandReshapelayer(Inputsize(1:2),EmbeddingDimension,Numcrasses,'名字'那“循证”));Lgraphdiscriminator = Addlayers(Lgraphdiscriminator,层);LgraphDiscriminator = ConnectLayers(Lgraphdiscriminator,“循证”那“猫/平方英寸”);
要使用自定义训练循环训练网络并启用自动分化,将图层图转换为adlnetwork.对象。
dlnetDiscriminator = dlnetwork (lgraphDiscriminator)
dlnetdiscriminator =具有属性的DLnetwork:图层:[17×1 nnet.cnn.layer.layer]连接:[16×2表]了解:[19×3表]状态:[6×3表]输入名称:{'图像''Labels'} OutputNames:{'conv5'}
定义模型梯度和损失函数
创建函数modelGradients,列于模型梯度函数这个例子的一部分,它以生成器和鉴别器网络、一小批输入数据和一个随机值数组作为输入,并返回相对于网络中的可学习参数和生成的图像数组的损失梯度。
指定培训选项
500个纪元的128个小批量列车。
numepochs = 500;minibatchsize = 128;
指定ADAM优化选项。对于两个网络,使用:
学习率为0.0002
梯度衰减系数为0.5
平方梯度衰减因子为0.999
learnRate = 0.0002;gradientDecayFactor = 0.5;squaredGradientDecayFactor = 0.999;
每100次迭代更新培训进度图。
validationFrequency = 100;
如果鉴别器学习区分真实的和生成的图像太快,那么生成器可能无法训练。为了更好地平衡鉴别器和生成器的学习,可以随机翻转一部分真实图像的标签。指定翻转系数为0.5。
flipfactor = 0.5;
火车模型
使用自定义训练循环训练模型。在训练数据上循环并在每次迭代时更新网络参数。要监视培训进度,请使用已停用的随机值阵列显示一批生成的图像以输入生成器和网络分数。
使用minibatchqueue在培训过程中对小批量图像进行处理和管理。为每个mini-batch:
使用自定义迷你批处理预处理功能
Preprocessminibatch.(在本例的最后定义)在范围内重新缩放图像[1]。丢弃任何具有少于128个观察的部分迷你批次。
使用尺寸标签格式化图像数据
“SSCB”(spatial, spatial, channel, batch)。使用维度标签格式化标签数据
“公元前”(批处理、通道)。在可用的GPU上进行训练。当
“OutputEnvironment”选择minibatchqueue是'auto'那minibatchqueue将每个输出转换为gpuArray如果GPU可用。使用GPU需要并行计算工具箱™和GPU支持的设备。金宝app有关支持的设备的信息,请参阅金宝appGPU通金宝app过发布支持(并行计算工具箱)。
当minibatchqueue对象,默认情况下,将数据转换为dlarray具有底层类型的对象单。
augimds。MiniBatchSize = MiniBatchSize;executionEnvironment =“汽车”;兆贝可= minibatchqueue (augimds,...“MiniBatchSize”,miniBatchSize,...“PartialMiniBatch”那“丢弃”那...“MiniBatchFcn”@preprocessData,...“MiniBatchFormat”, {“SSCB”那“公元前”},...“OutputEnvironment”, executionEnvironment);
初始化为亚当优化的参数。
velocityDiscriminator = [];trailingAvgGenerator = [];trailingAvgSqGenerator = [];trailingAvgDiscriminator = [];trailingAvgSqDiscriminator = [];
初始化的训练进度的情节。创建人物并调整它有宽度的两倍。
f =数字;F.Position(3)= 2 * F.Position(3);
创建生成的图像和得分图的次要情节。
imageAxes =情节(1、2、1);scoreAxes =情节(1、2、2);
初始化Scors Plot的动画行。
lineScoreGenerator = animatedline (scoreAxes,“颜色”0.447 - 0.741 [0]);lineScoreDiscriminator = animatedline (scoreAxes,“颜色”, [0.85 0.325 0.098]);
自定义图表的外观。
传奇(“发电机”那鉴频器的);ylim([0 1])包含(“迭代”) ylabel (“分数”网格)在
为了监控训练进展,创建一个由25个随机向量和一组对应的标签1到5(对应于类)重复5次的保留批。
numvalidationimagesperclass = 5;zvalidation = randn(numlatentinputs,numvalidationImages perclass * numclasses,“单一”);TValidation = single(repmat(1:numClasses,[1 numValidationImagesPerClass]));
将数据转换为dlarray对象并指定维度标签“CB”(频道,批处理)。
dlzvalidation = dlarray(zvalidation,“CB”);dlTValidation = dlarray (TValidation,“CB”);
对于GPU训练,将数据转换为gpuArray对象。
如果(executionEnvironment = =“汽车”&& canusegpu)||executionenvironment ==.“图形”dlzvalidation = gpuarray(dlzvalidation);DLTValidation = GPUARRAY(DLTValidation);结束
训练条件GAN。对于每个epoch,洗牌数据并在小批数据上循环。
为每个mini-batch:
使用
dlfeval和modelGradients函数。使用
adamupdate函数。画出两个网络的比分。
在每一个
验证频繁迭代,显示一批生成的图像为固定的保留发生器输入。
培训可能需要一些时间来运行。
迭代= 0;开始=抽动;%循环纪元。对于时代= 1:numEpochs重置和洗牌数据。洗牌(兆贝可);%循环小批。而Hasdata (mbq) iteration = iteration + 1;%读取小批数据。[DLX,DLT] =下一个(活度);为发电机网络产生潜在的输入。转换为%dlarray并指定维标签'cb'(通道,批次)。%如果在GPU上训练,则将潜在输入转换为gpuArray。Z = randn (numLatentInputs miniBatchSize,“单一”);dlZ = dlarray (Z,“CB”);如果(executionEnvironment = =“汽车”&& canusegpu)||executionenvironment ==.“图形”dlZ = gpuArray (dlZ);结束%使用Model梯度和发电机状态进行评估的% dlfeval和模型梯度函数%的例子。[gradientsGenerator, gradientsDiscriminator, stateGenerator, scoreGenerator, scoreDiscriminator] =...dlfeval(@modelGradients, dlnetGenerator, dlnetDiscriminator, dlX, dlT, dlZ, flipFactor);dlnetGenerator。状态= stateGenerator;%更新鉴别网络参数。[dlnetDiscriminator, trailingAvgDiscriminator trailingAvgSqDiscriminator] =...Adamupdate(DLNETDISCRIMINATOR,梯度DISCRIMINATOR,...TrailIghaVGDIscriminator,Trailingavgsqdiscriminator,迭代,...learnRate,gradientDecayFactor,squaredGradientDecayFactor);%更新生成网络参数。[dlnetGenerator, trailingAvgGenerator trailingAvgSqGenerator] =...adamupdate (dlnetGenerator gradientsGenerator,...Trailighavggenerator,trailighavgsqgenerator,迭代,...learnRate,gradientDecayFactor,squaredGradientDecayFactor);%每次validationFrequency迭代,使用%保留发电机输入。如果mod(iteration,validationFrequency) == 0 || iteration == 1%生成图像使用保留发生器输入。dlXGeneratedValidation =预测(dlnetGenerator dlZValidation dlTValidation);在[0 1]范围内平铺并重新缩放图像。i = Imtile(提取数据(DLXGeneratedValidation),...“GridSize”,[numvalidationImagesperclass numclasses]);我= Rescale(i);%显示图像。次要情节(1、2、1);图像(imageAxes,我)xticklabels ([]);yticklabels ([]);标题(“生成的图像”);结束%更新分数图。次要情节(1、2、2)addpoints (lineScoreGenerator,迭代,...双(收集(extractdata (scoreGenerator))));addpoints (lineScoreDiscriminator迭代,...双(聚(ExtractData由(scoreDiscriminator))));%用培训进度信息更新标题。D =持续时间(0,0,toc(开始),“格式”那“hh: mm: ss”);标题(...”时代:“+ epoch +”、“+...“迭代”+迭代+”、“+...”经过:“+ drawnow字符串(D))结束结束
这里,鉴别器已经学习了强大的特征表示,其识别生成图像之间的真实图像。反过来,发电机已经学习了类似强的特征表示,其允许它生成类似于训练数据的图像。每列对应于单个类。
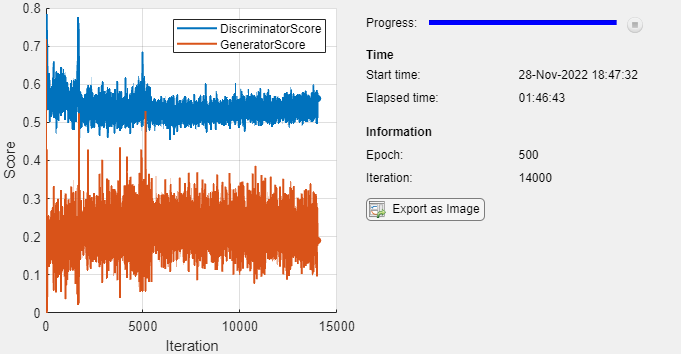
训练图显示了发电机和鉴别器网络的分数。了解有关如何解释网络分数的更多信息,请参阅监控GAN培训进度,识别常见故障模式。
生成新的图片
要生成特定类的新图像,请使用预测函数在生成器上使用dlarray对象,该对象包含与所需类相对应的一批随机向量和标签数组。将数据转换为dlarray对象并指定维度标签“CB”(频道,批处理)。对于GPU预测,将数据转换为gpuArray对象。要同时显示图像,请使用inmtile.函数并使用重新调整函数。
创建的对应于所述第一类的随机值的36个矢量阵列。
numObservationsNew = 36;idxClass = 1;Z = randn (numLatentInputs numObservationsNew,“单一”);T = repmat(单(idxClass),[1 numObservationsNew]);
将数据转换为dlarray具有维标签的对象“SSCB”(空间、空间、通道、批处理)。
dlZ = dlarray (Z,“CB”);DLT = dlarray(T,“CB”);
要使用GPU生成图像,还将数据转换为gpuArray对象。
如果(executionEnvironment = =“汽车”&& canusegpu)||executionenvironment ==.“图形”dlZ = gpuArray (dlZ);dlT = gpuArray (dlT);结束
使用预测使用发电机网络功能。
dlxgenerated =预测(Dlnetgenerator,DLZ,DLT);
在绘图中显示生成的图像。
图I = imtile(ExtractData由(dlXGenerated));我= Rescale(i);imshow(I)称号(”类:“+类(idxClass))

这里,生成器网络生成调节在指定类上的图像。
模型梯度函数
这个函数modelGradients作为输入发电机和鉴别器dlnetwork.对象dlnetGenerator和dlnetDiscriminator中,小批量的输入数据的dlX,对应的标签DLT.,以及一个随机值数组dlZ,并返回损失相对于网络中可学习参数、生成器状态和网络得分的梯度。
如果鉴别器学习区分真实的和生成的图像太快,那么生成器可能无法训练。为了更好地平衡鉴别器和生成器的学习,可以随机翻转一部分真实图像的标签。
函数[gradientsGenerator, gradientsDiscriminator, stateGenerator, scoreGenerator, scoreDiscriminator] =...modelGradients(dlnetGenerator,dlnetDiscriminator,DLX,DLT,DLZ,flipFactor)%用鉴别器网络计算真实数据的预测。dlYPred =正向(dlnetDiscriminator,DLX,DLT);%计算的预测以与鉴别器网络产生的数据。[dlXGenerated, statgenerator] = forward(dlnetGenerator, dlZ, dlT);dlYPredGenerated = forward(dlnetDiscriminator, dlXGenerated, dlT);%计算概率。probgenerated = sigmoid(dlypredgenerated);probreal = sigmoid(dlypred);%计算生成器和鉴别器分数。scoreGenerator =平均值(probGenerated);scoreDiscriminator =(均值(probReal)+平均(1-probGenerated))/ 2;%翻转标签。numObservations =大小(dlYPred 4);idx = randperm(numObservations,floor(flipFactor * numObservations));proreal (:,:,:,idx) = 1 - proreal (:,:,:,idx);%计算的GAN损失。[lossGenerator, lossDiscriminator] = ganLoss(probReal, probGenerated);%对于每个网络,计算相对于损失的梯度。gradientsGenerator = dlgradient(lossGenerator, dlnetGenerator。可学的,“RetainData”,真正的);梯度Discriminator = Dlgradient(LockDiscriminator,DLNetDiscriminator.Learnables);结束
氮化镓损失函数
发电机的目标是生成数据,所述鉴别器归类为“真正的”。为了最大化发电机的图像被鉴别器分类的概率,最小化负对数似函数。
考虑到输出 鉴别的:
输入图像属于类的概率是多少
“真正的”。输入图像属于类的概率是多少
“生成”。
注意乙状结肠手术
发生在modelGradients函数。发电机的损耗函数为
在哪里 包含所生成的图像的鉴相器输出的概率。
鉴别器的目的是不被生成器“愚弄”。为了最大限度地提高鉴别器在真实图像和生成图像之间成功鉴别的概率,最小化相应的负对数似然函数的和。给出了该鉴别器的损失函数
在哪里 包含真实图像的鉴别器输出概率。
函数[lossGenerator, lossDiscriminator] = ganLoss(scoresReal,scoresGenerated)%计算鉴别器网络的损耗。lossGenerated = -mean(log(1 - scoresGenerated));lossReal =意味着(日志(scoresReal));%合并损失鉴别网络。lossDiscriminator = lossReal + lossGenerated;%计算发电机网络的损耗。lossGenerator =意味着(日志(scoresGenerated));结束
小批量预处理功能
当Preprocessminibatch.函数使用以下步骤进行预处理的数据:
从输入单元阵列中提取图像和标记数据并将其连接到数字阵列中。
重新归类图像在范围内
[1]。
函数[X,T] = preprocessData(XCELL,T-细胞)%从单元格提取图像数据并连接X = CAT(4,Xcell {:});%从单元格中提取标签数据并连接T =猫(1,T细胞{:});%在[-1 1]范围内重新缩放图像。X =重新调节(X, 1, 1,“InputMin”0,“InputMax”,255);结束
参考资料
另请参阅
adamupdate|dlarray|dlfeval|dlgradient|dlnetwork.|向前|预测
相关的话题
你也可以从以下列表中选择一个网站:
