主要内容
比较了LMS算法与归一化LMS算法的收敛性能
自适应滤波器使其滤波系数与未知系统的系数相匹配。目标是最小化未知系统输出与自适应滤波器输出之间的误差信号。对于相同的输入,当这两个输出收敛并且非常匹配时,系数被称为非常匹配。这种状态下的自适应滤波器类似于未知系统。这个例子比较了归一化LMS (NLMS)算法和没有归一化的LMS算法的收敛速度。
未知的系统
创建一个dsp。FIRFilter表示未知系统。通过信号x作为未知系统的输入。所需的信号d是未知系统(FIR滤波器)输出和加性噪声信号的和吗n.
filt = dsp.FIRFilter;filt。分子= fircband(12,[0 0.4 0.5 1],[1 10 0 0],[1 0.2],...{' w '“c”});x = 0.1 * randn (1000 1);n = 0.001 * randn (1000 1);D = filt(x) + n;
自适应滤波器
创建两个dsp。LMSFilter对象,其中一个集合为LMS算法,另一个集合为标准化LMS算法。选择自适应步长0.2,设置自适应滤波器的长度为13次。
μ= 0.2;lms_nonnormalized = dsp。LMSFilter (13,“StepSize”亩,...“方法”,“LMS”);lms_normalized = dsp。LMSFilter (13,“StepSize”亩,...“方法”,“归一化LMS”);
传递一次输入信号x和期望的信号dLMS算法的变化。的变量e1和e2分别表示期望信号与归一化滤波器和非归一化滤波器输出之间的误差。
(e1, ~ ~) = lms_normalized (x, d);(e2, ~ ~) = lms_nonnormalized (x, d);
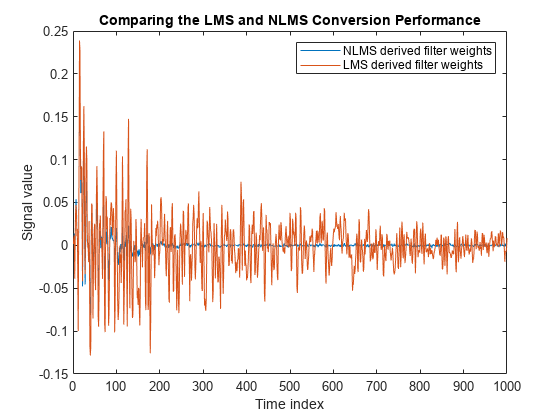
绘制两种变化的错误信号。NLMS变量的误差信号收敛到零的速度要比LMS变量的误差信号快得多。规范化版本适应的迭代要少得多,其结果几乎与非规范化版本一样好。
情节((e1, e2));标题(“LMS和NLMS转换性能的比较”);传奇(“NLMS导出的过滤器权重”,...“LMS导出的滤波器权重”,“位置”,“东北”);包含(“时间指数”) ylabel (的信号值)
另请参阅
对象
相关的话题
参考文献
海耶斯(Monson H. Hayes)统计数字信号处理与建模.霍博肯:John Wiley & Sons, 1996,第493 - 552页。
[2]微积分,西门,自适应滤波器理论.上鞍河,新泽西州:Prentice-Hall, Inc., 1996。
你也可以从以下列表中选择一个网站: