时间序列回归7:预测
这个例子展示了从多元线性回归模型中生成条件预测和无条件预测的基本设置。这是时间序列回归的一系列例子中的第7个,之前的例子已经介绍过了。
介绍
许多经济学中的回归模型是为了解释的目的而建立的,以理解相关经济因素之间的相互关系。这些模型的结构通常是由理论提出的。规范分析比较了模型的各种扩展和限制,以评估各个预测器的贡献。显著性检验在这些分析中尤为重要。建模的目标是实现对重要依赖项的详细说明和精确校准的描述。可以使用一个可靠的解释模型,通过确定在更多的定性分析中要考虑的因素,为规划和政策决定提供资料。
回归模型也用于定量预测。这些模型通常是由可能相关的预测器的初始集(可能是空的,也可能相当大)构建的。探索性数据分析和预测因子选择技术在这些分析中尤为重要。在这种情况下,建模的目标是准确地预测未来。一个可靠的预测模型可以用来确定投资决策中涉及的风险因素,以及它们与未来违约率等关键结果的关系。
在实践中,区分所研究的回归模型的类型是很重要的。如果预测模型是通过探索性分析建立的,那么它的整体预测能力是可以评估的,但是单个预测因子的重要性是无法评估的。特别是,使用相同的数据来构建一个模型,然后对其组件进行推断是具有误导性的。
本例主要讨论多元线性回归(MLR)模型的预测方法。这些方法本质上是多元的,根据预测变量的过去值和现在值来预测响应。因此,这些方法与单变量建模中使用的最小均方误差(MMSE)方法本质上是不同的,在单变量建模中,预测是基于单个序列的自历史。
我们首先从前面的示例加载相关数据时间序列回归VI:残差诊断:
负载Data_TSReg6
有条件的预测
回归模型描述由,或产生的响应有条件的上,预测变量的相关值。如果一个模型已经成功地捕获了数据生成过程(DGP)的基本动态,那么它可以用于探索预测数据是假设的而不是观察到的偶发情况。
本系列示例中考虑的模型已经使用预测数据进行了校准和测试X0,以时间计量t,以及响应数据y0,以时间计量t+ 1。数据的时移意味着这些模型在预测器的条件下提供了响应的提前一步的点预测。
为了进一步预测未来,唯一需要做的调整就是估计数据变化较大的模型。例如,要提前两步预测,需要测量响应数据t+ 2 (y0(2:结束))可以对实时测量的预测数据进行回归t(X0(1:结束-1))。当然,以前的模型分析必须重新进行以确保可靠性。
为了举例说明,我们使用M0模型生成2006年违约率的条件点预测,给出变量中提供的2005年预测因子的新数据X2005:
betaHat0 = M0.Coefficients.Estimate;yHat0 = [1,X2005] * betaHat0;d =时间(结束);XM =分钟([X0(:); X2005' ]);XM = MAX([X0(:); X2005' ]);图保存上情节(日期,X0,“线宽”,2)情节(D: D + 1, (X0(最终:);X2005),* - - - - - -。,“线宽”,2)补([D D D+1 D+1],[Xm Xm Xm],“b”,“FaceAlpha”,0.1)从传奇(predNames0'位置','NW')xlabel(“年”)ylabel(的预测水平)标题('{\bf新预测数据}')轴紧网格上
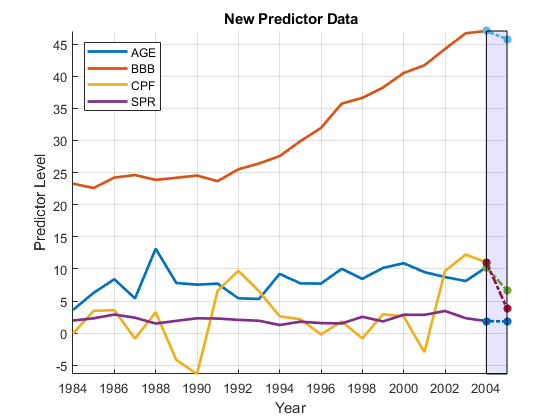
YM =分钟([Y0; yHat0]);YM = MAX([Y0; yHat0]);图保存上情节(日期,y0,“k”,“线宽”2);情节(D: D + 1, y0(结束);yHat0),“*同意”,“线宽”,2)填充([D D D+1 D+1],[Ym Ym Ym Ym],“b”,“FaceAlpha”,0.1)从传奇(respName0'位置','NW')xlabel(“年”)ylabel(“响应级别”)标题(“{\ bf预测响应}”)轴紧网格上

我们看到SPR从2004年到2005年,风险因素大致保持不变,而风险因素略有下降年龄和BBB危险因素被减少的收入抵消了论坛。论坛具有负的模型系数,因此下降与风险增加相关。最终的结果是预测违约率的跃升。
无条件的预测
在缺乏新的预测数据(无论是测量的还是假设的)的情况下无条件的可能需要对响应进行预测。
一种方法是创建响应的动态、单变量模型,如ARIMA模型,独立于预测器。ARIMA模型依赖于从一个时间段到下一个时间段的序列中存在的自相关性,该模型可以利用这些自相关性进行预测。ARIMA模型在文档的其他地方进行了讨论。
或者,可以建立预测因子的动态、多变量模型。这允许预测器的新值被预测,而不是被观察。然后,回归模型可以根据预测因子的预测来预测响应。
稳健多元预测是由向量自回归(VAR)模型。基于VAR模型使得关于模型变量之间的关系的形式,没有结构的假设。它只是假定,每个变量潜在的影响其他。这样就形成了一个动态回归方程系统,每个变量都出现在一个方程的左边,所有变量的滞后值都相同,可能还有一个截距出现在所有方程的右边。这样做的目的是让回归分析找出哪些项实际上是重要的。
例如,默认率模型中预测器的VAR(3)模型应该是这样的:
模型中系数的数量等于变量的数量乘以自回归滞后的数量乘以方程的数量,再加上截距的数量。即使只有几个变量,具有指定良好滞后结构的模型也可以快速增长到无法使用小数据样本进行估计的大小。
由于每个方程都有相同的回归量,因此使用VAR模型进行逐方程OLS估计的效果很好。这是真的,不管任何交叉方程协方差可能出现在创新。此外,纯自回归估计在数值上是非常稳定的。
然而,估计值的数值稳定性依赖于所建模变量的平稳性。差异的、平稳的预测变量导致了对差异的可靠预测。然而,可能需要无差异的预测数据来预测回归模型的响应。整合预测差异有可能产生扭曲的预测水平(例如,[2])。然而,标准的建议是在VAR中使用固定变量,假设短期内将产生最小的重新纳入误差。
VAR的估计和预测是通过函数来实现的估计和预测。下面从产生违约率无条件点预测在2005年M0回归模型:
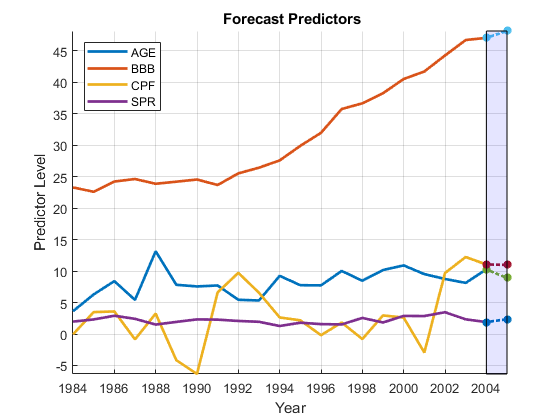
使用VAR(1)模型对不同的预测因子进行估计% undifferenced岁| |):numLags = 1;D1X0PreSample = D1X0 (1: numLags,:);D1X0Sample = D1X0 (numLags + 1:最终,);numPreds0 = numParams0-1;VARMdl = varm (numPreds0 numLags);EstMdl =估计(VARMdl D1X0Sample,“Y0”,D1X0PreSample);%预测D1X0中的预测因子:地平线= 1;ForecastD1X0 =预测(EstMdl,地平线,D1X0);%对差分预测进行积分,得到未差分预测:ForecastX0 (1) = ForecastD1X0 (1);%的年龄ForecastX0 (2:4) = X0(最终,2:4)+ ForecastD1X0 (2:4);%其他预测XM =分钟([X0(:); ForecastX0(:)]);XM = MAX([X0(:); ForecastX0(:)]);图保存上情节(日期,X0,“线宽”,2)情节(D: D + 1, (X0(最终:);ForecastX0),* - - - - - -。,“线宽”,2)补([D D D+1 D+1],[Xm Xm Xm],“b”,“FaceAlpha”,0.1)从传奇(predNames0'位置','NW')xlabel(“年”)ylabel(的预测水平)标题(“{\ bf预报预测}”)轴紧网格上
%预测回归模型的响应:ForecastY0 = [1, ForecastX0] * betaHat0;Ym = min ([y0, ForecastY0]);YM = max ([y0, ForecastY0]);图保存上情节(日期,y0,“k”,“线宽”2);情节(D: D + 1, y0(结束);ForecastY0),“*同意”,“线宽”,2)填充([D D D+1 D+1],[Ym Ym Ym Ym],“b”,“FaceAlpha”,0.1)从传奇(respName0'位置','NW')xlabel(“年”)ylabel(“响应级别”)标题(“{\ bf预测响应}”)轴紧网格上
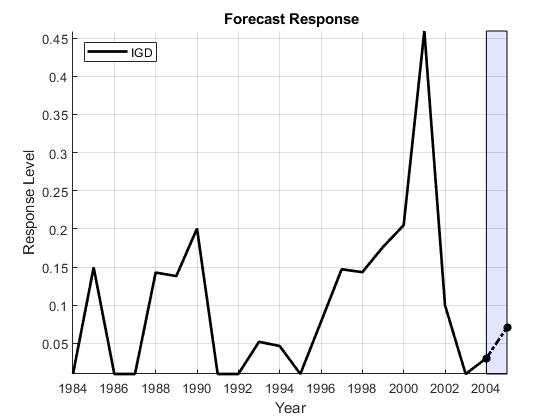
结果是一个无条件的预测,类似于2005年实际数据的条件预测。预测取决于VAR模型中使用的滞后量,numLags。在本例中讨论了选择适当滞后长度的问题时间序列回归IX:滞后顺序选择。
由预测是nonstochastic,从这个意义上说,它使用了样本之外的零价值创新。生成一个随机预测,用具体的结构在创新,使用模拟要么过滤器。
预测误差
无论如何获得新的预测数据,来自MLR模型的预测都将包含错误。这是因为MLR模型本身只预测响应的期望值。例如,MLR模型
预测 使用
出现错误有两个原因:
预测不包含创新 。
抽样误差产生 这和 。
如示例中所述时间序列回归II:共线性和估计量方差,预测误差 被降低,如果
样本大小是较大的。
预测因子的变化更大。
更接近它的平均值。
最后一项表明,当预测更接近用于估计模型的样本值分布的中心时,预测会得到改善。这导致了非恒定宽度的区间预测。
假设有正常的、同方差的创新,点预测可以转换成 使用标准公式(例如,[1])。如示例中所述时间序列回归VI:残差诊断然而,在存在自相关或异方差创新的情况下,标准公式会变得偏颇和低效。在这种情况下,可以使用适当的一系列创新来模拟区间预测,但通常建议重新指定一个模型,以便尽可能地对创新进行标准化。
为了进行预测评估,通常会保留一部分数据,并使用初始子样本对模型进行估计。基本性能测试将子样本外预测的均方根误差(RMSE)与包含响应常数的最后一个样本内值的简单基线预测的RMSE进行比较。如果模型预测在基线预测的基础上没有显著提高,那么有理由怀疑模型没有提取DGP中的相关经济力量。
例如,下面的测试的性能M0模型:
numTest = 3;有待检验的观测值的百分比%的培训模式:X0Train = X0 (1: end-numTest,:);y0Train = y0 (1: end-numTest);M0Train = fitlm (X0Train y0Train);%测试集:X0Test = X0 (end-numTest + 1:最终,);y0Test = y0 (end-numTest + 1:结束);%的预测错误:y0Pred =预测(M0Train X0Test);DiffPred = y0Pred-y0Test;DiffBase = y0Pred-y0 (end-numTest);%的预测比较:RMSEPred =√(DiffPred * DiffPred) / numTest)
RMSEPred = 0.1197
RMSEBase = SQRT((DiffBase'* DiffBase)/ numTest)
RMSEBase = 0.2945
模型预测确实显示出相对于基线预测的改进。但是,使用不同的值重复测试是有用的numTest。2001年的一次有影响力的观察,也就是数据结束前的三次观察,使情况变得复杂。
如果一个模型通过了基线测试,就可以用完整的样本重新估计它,如M0。该测试有助于区分模型的适合性和捕获DGP动态的能力。
摘要
要从回归模型生成新的响应值,需要预测器的新值。当假设或观察到新的预测值时,使用回归方程外推响应数据。对于无条件外推,必须像VAR模型一样预测新的预测值。预测的质量既取决于模型的样本内拟合,也取决于模型对DGP的忠实度。
任何预测模型的基本假设都是模型所描述的经济数据模式将持续到未来。这是一个关于DGP稳定性的假设。然而,推动经济进程的社会机制从来不是稳定的。预测模型的价值,特别是通过探索性数据分析建立的模型,可能是短暂的。健全经济理论的基础将提高模型的寿命,但必须承认预测过程的不稳定性。在某种程度上,这种不确定性在预测误差的模型中得到了体现。
计量经济学的实践表明,简单的预测模型往往效果最好。
参考
[1]迪堡,F. X.预测的元素。哦,梅森:汤姆森高等教育,2007年。
[2]格兰杰,C.,和P.纽博尔德。“预测转化系列。”皇家统计学会期刊。B辑,第38卷,1976年,第189-203页。
你也可以从以下列表中选择一个网站:
