使用引导和过滤的历史模拟来评估市场风险
这个例子展示了如何使用过滤历史模拟(FHS)技术来评估一个假设的全球股票指数投资组合的市场风险,这是传统历史模拟和蒙特卡罗模拟方法的替代方法。FHS结合了相对复杂的基于模型的波动处理(GARCH)和资产收益概率分布的非参数规范。FHS的一个吸引人的特点是它能够产生在原始投资组合收益序列中没有发现的相对较大的偏差(损失和收益)。
本例首先采用非对称GARCH模型,从组合收益序列中提取过滤后的模型残差和条件波动率,从该模型中形成独立同分布(i.i.d.)标准化残差序列。FHS保留了历史模拟的非参数性质,通过从标准化残差中自举(抽样与替换)。然后,这些自引导的标准化残差被用来生成未来资产回报的时间路径。最后,该模拟评估了一个月内假想的全球股票投资组合的风险价值(VaR)。
这个例子只是众多备选方案中的一个,并不意味着要支持任何特定的风险管理哲学。有关另一种选择,请参见标题为的示例运用极值理论和copula理论评估市场风险。
检查全球股权指数数据的日常关闭
原始数据由跨越交易日期27-九九393年至2003年7月14日至7月14日至2003年的以下代表性股票指数的日常收盘价值2665年的日常闭幕价值观。
加拿大:TSX Composite (Ticker ^GSPTSE)法国:CAC 40 (Ticker ^FCHI)德国:DAX (Ticker ^GDAXI)日本:Nikkei 225 (Ticker ^N225)英国:FTSE 100 (Ticker ^GSPC)美国:S&P 500 (Ticker ^GSPC)
负载data_globalidx1.进口每日指数收盘
以下绘图说明了每个索引的相对价格运动。每个索引的初始水平已被标准化为Unity,以便于比较相对性能,并且没有明确考虑股息调整。
figure plot(日期,ret2price(price2ret(Data))) datetick(数据)“x”)xlabel('日期')ylabel('指数值') 标题 (“相对日常指数关闭”)传奇(系列,'地点'那'西北')

为后续建模做准备,指定投资组合的权重向量。虽然假设的是一个同等权重的投资组合,但您可以改变权重向量来检查任何其他的投资组合组合,甚至单个国家。请注意,在整个风险范围内,投资组合的权重是固定的,并且模拟忽略了重新平衡投资组合所需的任何交易成本(假定每天的重新平衡过程是自我筹资的)。
nIndices =大小(数据,2);指数% #权重= repmat(1 / nindices,nindices,1);%同样加权的组合
鉴于权重,从各个指标的每日返回中形成投资组合对数回报系列(有时称为几何或持续复合的返回)。虽然索引返回是对数的,但是通过首先将各个对数返回转换为算术返回(价格变化除以初始价格)来构建产品组合返回系列,然后加权各个算术返回以获得投资组合的算术返回,最终转换回到投资组合对数返回。随着日常数据和短var Horizo n,重复的转换几乎没有差异,但对于较长的时间段来差异可能是显着的。
返回= price2ret(数据,[],“周期”)*重量;%算术回报returns = log(1 +返回);%对数返回t =大小(返回,1);%历史样本大小
绘制假设组合的日常关闭值以及相应的回报序列进行比较。
图形子图(2,1,1)绘图(日期,Ret2price(返回))DateTick(“x”)xlabel('日期')ylabel('关闭水平') 标题('每日投资组合关闭') subplot(2,1,2) plot(日期(2:end),返回)datetick(“x”)xlabel('日期')ylabel(“返回”) 标题(“每日投资组合对数回报”)

过滤投资组合返回
引导的FHS方法需要观察到大致独立和相同分布。然而,大多数金融回报系列表现出一定程度的自相关,更重要的是,异源性瘢痕状况。
例如,产品组合返回的样本自相关函数(ACF)揭示了一些轻度串行相关性。
figure autocorr(返回)标题('返回的样本ACF')

然而,平方返回的样本ACF示出了方差的持久程度,并且意味着GARCH建模可以显着地使得随后的引导方法中使用的数据。
figure autocorr(返回。^ 2)标题('Squared Returns的样本ACF')

为了产生一系列的i.i.d.观察,拟合一个一阶自回归模型的条件均值的投资组合收益

条件方差的非对称指数GARCH (EGARCH)模型
![$$ log [\ sigma ^ 2_t] = \ kappa + \ alpha log [\ sigma ^ 2_ {t-1}] + \ phi(| z_ {t-1} | - e [| z_ {t-1} |])+ \ psi z_ {t-1} $$](http://www.tatmou.com/help/examples/econ/win64/Demo_RiskFHS_eq03036858494399792428.png)
第一阶自回归模型补偿自相关,而Egarch模型补偿了异源性瘢痕度。特别地,Egarch模型还将不对称(杠杆)包含到方差方程中(见[6]).
此外,每个指数的标准化残差被建模为标准化的Student's t分布,以补偿通常与股票回报相关的肥尾。这是

以下代码段估计AR(1)+ eGARCH(1,1)模型,并从投资组合回报中提取过滤的残差和条件方差。
型号= Arima('AR'南,'分配'那'T'那“方差”egarch (1,1));选择= optimoptions (@fmincon,'展示'那'离开'那'诊断'那'离开'那......“算法”那'SQP'那'tolcon',1E-7);Fit =估计(模型,返回,'选项'、选择);%适合模型[残差,variances] =推断(适合,返回);%推断残差和差异
ARIMA(1,0,0)模型(t分布):Value standardror TStatistic PValue __________ _____________ __________ __________ Constant 0.00021377 0.00012471 1.7142 0.086488 AR{1} 0.1855 0.019906 9.3187 1.1777e-20 DoF 12.649 2.7038 4.6784 2.8909e-06 EGARCH(1,1)条件方差模型(t分布):值标准误差TStatistic PValue _________ _____________ __________ __________ Constant -0.13366 0.030071 -4.4449 8.7926e-06 GARCH{1} 0.0.9639 0.0030907 319.15 0 ARCH{1} 0.13383 0.019006 7.0417 1.8995e-12杠杆{1}-0.091885 0.012152 -7.5615 3.9836e-14 DoF 12.649 2.7038 4.6784 2.8909e-06
比较模型残差和从原始回报中滤除的相应条件标准偏差。下图清楚地说明了过滤残留物中存在的挥发性(异源性瘢痕度)的变化。
图形子图(2,1,1)绘图(日期(2:结束),残差)DateTick(“x”)xlabel('日期')ylabel('剩余的') 标题 ('过滤残留')子图(2,1,2)绘图(日期(2:结束),sqrt(variances))datetick(“x”)xlabel('日期')ylabel('挥发性') 标题 ('过滤条件标准偏差')

通过POSTFOLIO REPTRING系列过滤了模型残差,通过相应的条件标准偏差标准化每个残差。这些标准化残差代表底层零平均值,单位方差,即i.i.d.系列。I.I.D.属性对于自动启动很重要,并允许采样程序安全地避免从连续观察串行依赖的人群中取样的陷阱。
标准化熟节=残差./ sqrt(variances);
要结束本节,请检查标准化残留和平方标准化残留的ACF。将标准化残差的ACF与RAW返回的相应ACF进行比较显示,标准化残差现在大约是I.I.D.,从而更能适应随后的自动启动。
图自动磁盘(标准化熟)标题(“标准化残差的样本ACF”)图形自动错误(标准化熟)。^ 2)标题('平方标准化残差的样本ACF')


使用FHS模拟全球索引产品组合
如上所述,FHS引导标准化残差以生成未来资产返回的路径,因此没有关于这些返回的概率分布的参数假设。引导过程产生i.i.d.标准化残留物与由上面的Ar(1)+γ-+肉质(1,1)过滤过程中获得的残留物一致。
以下代码段模拟了22个交易日的一个月地平线的标准化残差的20,000个独立随机试验。
s = randstream.getGlobalStream();重置(s)ntrials = 20000;%#独立随机试验地平线= 22;%var预测地平线bootstrapperesiduals =标准化残差(unidrnd(T, horizon, nTrials));
使用引导标准化的残差作为i.i.d.输入噪声过程,通过OuthoMetrics Toolbox™重新引入在原始产品组合返回系列中观察到的自相关和异源性瘢痕度筛选功能。为了充分利用当前信息,指定必要的预先模型残差,差异和返回,以便每个模拟路径从常见的初始状态演变。
y0 =返回(结束);% Presample回报z0 =残差(结束)./ sqrt(variances(end));%预先定位模型标准化残差V0 =方差(结束);% Presample方差portfolioreturns =过滤器(FIT,BootstrappedResivs,......'y0',y0,'z0',z0,'v0',v0);
总结结果
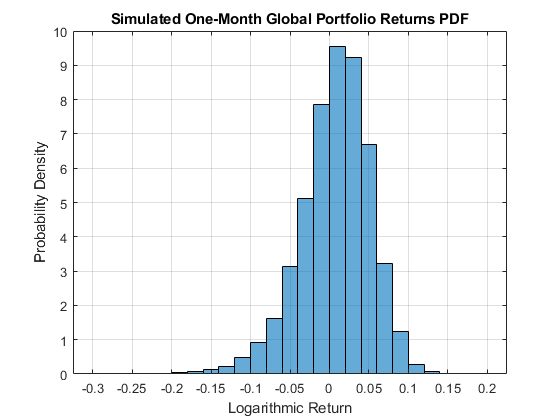
模拟了全球指数投资组合的回报,报告了在一个月风险范围内的各种置信水平的最大增益和损失,以及var。此外,绘制了产品组合累积回报的经验累积分布函数(CDF)和概率密度函数(PDF)。
由于您正在使用每日对数返回,因此风险地平线上的累积返回只是每个中间期间的返回的总和。
cumulativereturns = sum(portfolioreturns);var = 100 * stantile(cumulativereturns,[0.0 0.05 0.01]');DISP('')fprintf('最大模拟损失:%8.4f%s \ n',-100 * min(cumulativereturns),“%”)fprintf(最大模拟增益:%8.4f%s\n\n',100 * max(cumulativereturns),“%”)fprintf('模拟90 %% var:%8.4f%s \ n',var(1),“%”)fprintf('模拟95 %% var:%8.4f%s \ n',var(2),“%”)fprintf('模拟99 %% var:%8.4f%s \ n',var(3),“%”)图H = CDFPLOT(Cumulativereturns);H.Color =.'红色的';包含('对数返回')ylabel('可能性') 标题 ('模拟一个月全球投资组合返回CDF')图箱= -0.3:0.02:0.2;直方图(Cumulativereturns,垃圾箱,“归一化”那'pdf')xlabel('对数返回')ylabel('概率密度') 标题 ('模拟一个月全球投资组合返回PDF'网格)上
最大仿真损失:39.7598%最大模拟增益:15.2458%模拟90%var:-5.0145%模拟95%var:-7.2182%模拟99%var:-12.4882%

参考
[1]Barone-Adesi, G., K. Giannopoulos,和L. Vosper。"非线性投资组合中不含相关性的VaR "期货市场。卷。1999年,第583-602页。
[2]Brandolini,D.,M. Pallotta和R. Zenti。“资产管理公司的风险管理:一个实际的案例。”在瑞士卢加诺的EMFA 2001上提出。2000年。
[3]Chercoftersen,P.F.财务风险管理要素。沃尔瑟姆,马:学术出版社,2002年。
[4]Dowd,K。测量市场风险。West Sussex:John Wiley&Sons,2005。
[5]麦克尼尔,A.和R.弗雷。异方差金融时间序列尾部相关风险测度的估计:一种极值方法经验金融杂志。卷。7,2000,第271-300页。
[6]纳尔逊,D.B。“资产回报中有条件的异源性娱乐:一种新方法。”费雪。。卷。59,2,1991,第291页,第347-370。
您还可以从以下列表中选择一个网站:
