过滤器
利用矢量误差校正(VEC)模型滤波干扰
语法
描述
Tbl2=过滤器(Mdl,Tbl1Presample =Presample)Tbl2包含多元响应序列,其结果来自过滤输入表或时间表中的底层多元扰动序列Tbl1.过滤器中使用所需的预采样数据表或时间表初始化响应系列Presample.变量Tbl1是否与模式创新过程相关联Mdl.
过滤器中的变量Mdl。SeriesNames或者所有的变量Tbl1.选择不同的扰动变量Tbl1要对模型进行筛选,请使用DisturbanceVariables名称-值参数。过滤器选择相同的变量Presample属性,但可以选择不同的变量PresampleResponseVariables名称-值参数。
例子
用VEC模型滤波扰动数值矩阵
考虑以下七个宏观经济系列的VEC模型。然后,将模型与数据进行拟合,通过拟合模型对扰动进行滤波。以数值矩阵的形式提供扰动。
国内生产总值(GDP)
GDP隐性价格平减指数
员工薪酬
所有人的非农业务部门工作时间
实际联邦基金利率
个人消费支出
国内私人投资总额
假设协整秩为4和一个短期项是合适的,即考虑VEC(1)模型。
加载Data_USEconVECModel数据集。
负载Data_USEconVECModel
有关数据集和变量的更多信息,请输入描述在命令行。
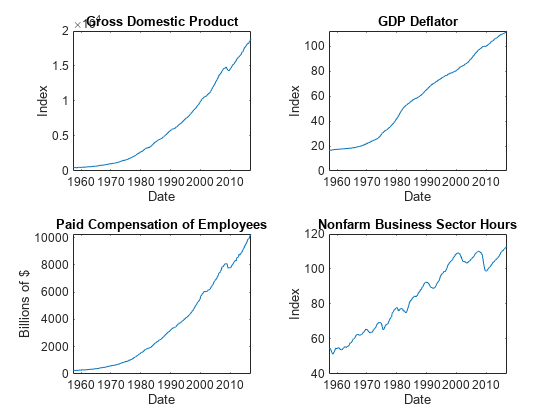
通过在单独的图上绘制序列来确定是否需要对数据进行预处理。
图平铺布局(2,2)nexttile plot(FRED.Time,FRED.GDP)“本地生产总值”) ylabel (“指数”)包含(“日期”nexttile plot(FRED.Time,FRED.GDPDEF)“GDP平减指数”) ylabel (“指数”)包含(“日期”nexttile plot(FRED.Time,FRED.COE)“雇员的已付补偿”) ylabel (“数十亿美元”)包含(“日期”nexttile的用法和样例:“非农业行业营业时间”) ylabel (“指数”)包含(“日期”)
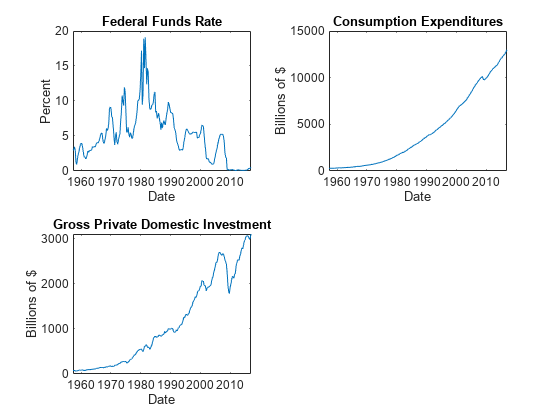
图tiledlayout(2,2) nexttile plot(FRED.Time,FRED.FEDFUNDS)“联邦基金利率”) ylabel (“百分比”)包含(“日期”nexttile plot(FRED.Time,FRED.PCEC)“消费支出”) ylabel (“数十亿美元”)包含(“日期”nexttile plot(FRED.Time,FRED.GPDI)“本地私人投资总额”) ylabel (“数十亿美元”)包含(“日期”)
通过应用对数变换,稳定除联邦基金利率外的所有系列。将生成的系列按100缩放,以便所有系列都在相同的比例上。
弗雷德。国内生产总值=100*log(FRED.GDP); FRED.GDPDEF = 100*log(FRED.GDPDEF); FRED.COE = 100*log(FRED.COE); FRED.HOANBS = 100*log(FRED.HOANBS); FRED.PCEC = 100*log(FRED.PCEC); FRED.GPDI = 100*log(FRED.GPDI);
使用简写语法创建VEC(1)模型。指定变量名。
Mdl = vecm(7,4,1);Mdl。SeriesNames = FRED.Properties.VariableNames
Mdl = vecm与属性:说明:“7维秩= 4 VEC(1)模型与线性时间趋势”SeriesNames:“GDP”“GDPDEF”“COE”…和4更NumSeries: 7等级:4 P: 2常数:[7×1的向量nan]调整:[7×4矩阵nan)协整:[7×4矩阵nan)影响:[7×7矩阵nan] CointegrationConstant:[4×1的向量nan] CointegrationTrend:[4×1的向量nan]短期的:{7×7矩阵nan}在滞后[1]的趋势:[7×1的向量nan]β:协方差矩阵[7×0]:[7×7矩阵nan)
Mdl是一个结果模型对象。所有属性包含南值对应于给定数据要估计的参数。
使用整个数据集和默认选项估计模型。默认情况下,估计使用第一个p= 2个观测数据作为预样本数据。
EstMdl =估计(Mdl,FRED.Variables)
EstMdl = vecm属性:描述:“7维Rank = 4 VEC(1)模型”SeriesNames:“GDP”“GDPDEF”“COE”…和4更多NumSeries: 7排名:4 P: 2常量:[14.1329 8.77841 -7.20359…调整:[7×4矩阵]协整:[7×4矩阵]影响:[7×7矩阵]协整常量:[-28.6082 109.555 -77.0912…and 1 more]' CointegrationTrend: [4×1 vector of zero] ShortRun: {7×7 matrix} at lag[1]趋势:[7×1 vector of zero] Beta: [7×0 matrix]协方差:[7×7 matrix]
EstMdl是估计的结果模型对象。它是完全指定的,因为所有参数都有已知值。默认情况下,估计通过从模型中去除协整趋势项和线性趋势项,对H1 Johansen VEC模型形式施加约束。从估计中排除参数相当于将相等约束施加到零。
生成一个numobs-by-7序列的随机高斯分布值,其中numobs数据中的观察数是负数吗p.
nummobs = size(FRED,1) - Mdl.P;rng (1)%用于再现性Z = randn(nummobs,Mdl.NumSeries);
为了模拟响应,通过估计模型对扰动进行滤波。指定第一个p= 2个观测数据作为预样本数据。
Y = filter(EstMdl,Z,Y0=FRED{1:2,:});
Y是一个238 × 7的模拟响应矩阵。中的变量名对应于列EstMdl。SeriesNames.
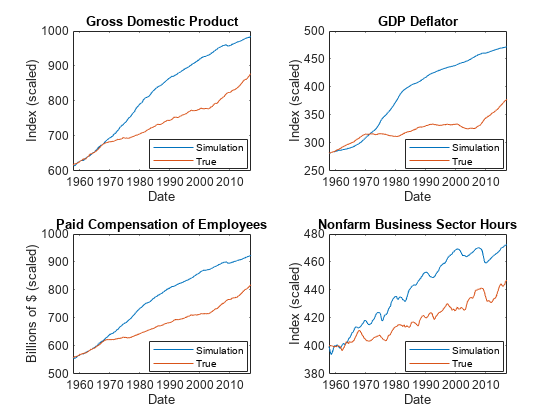
绘制模拟反应和真实反应。
图tiledlayout(2,2) nexttile plot(FRED.Time(3:end),[FRED.GDP(3:end) Y(:,1)]) title(“本地生产总值”) ylabel (”指数(了)”)包含(“日期”)传说(“模拟”,“真正的”,“位置”,“最佳”nexttile plot(FRED.Time(3:end),[FRED.GDPDEF(3:end) Y(:,2)]) title(“GDP平减指数”) ylabel (”指数(了)”)包含(“日期”)传说(“模拟”,“真正的”,“位置”,“最佳”) nexttile plot(FRED.Time(3:end),[FRED.COE(3:end) Y(:,3)])“雇员的已付补偿”) ylabel (“数十亿美元(按比例)”)包含(“日期”)传说(“模拟”,“真正的”,“位置”,“最佳”) nexttile plot(FRED.Time(3:end),[FRED.HOANBS(3:end) Y(:,4)])“非农业行业营业时间”) ylabel (”指数(了)”)包含(“日期”)传说(“模拟”,“真正的”,“位置”,“最佳”)
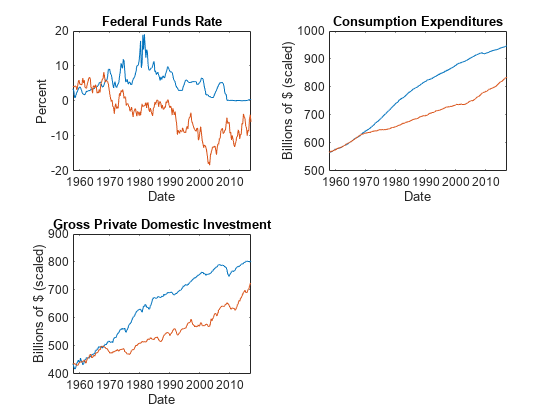
图tiledlayout(2,2) nexttile plot(FRED.Time(3:end),[FRED.FEDFUNDS(3:end) Y(:,5)]) title(“联邦基金利率”) ylabel (“百分比”)包含(“日期”) nexttile plot(FRED.Time(3:end),[FRED.PCEC(3:end) Y(:,6)]) title(“消费支出”) ylabel (“数十亿美元(按比例)”)包含(“日期”nexttile plot(FRED.Time(3:end),[FRED.GPDI(3:end) Y(:,7)]) title(“本地私人投资总额”) ylabel (“数十亿美元(按比例)”)包含(“日期”)
多干扰路径滤波
考虑三个假设响应序列的VEC(1)模型。
创新是均值为0的多元高斯分布和协方差矩阵
为参数值创建变量。
调整= [-0.3 0.3;-0.2 - 0.1;1 0];协整= [0.1 -0.7;-0.2 - 0.5;0.2 - 0.2);ShortRun = {[0.]0.1 - 0.2;0.2 -0.2 0;0.7 -0.2 0.3]}; Constant = [-1; -3; -30]; Trend = [0; 0; 0]; Covariance = [1.3 0.4 1.6; 0.4 0.6 0.7; 1.6 0.7 5];
创建一个结果模型对象使用适当的名称-值对参数表示VEC(1)模型。
Mdl = vecm(“调整”调整,协整的协整,...“不变”常数,“短期的”短期的,“趋势”的趋势,...协方差的协方差)
Mdl = vecm带属性:描述:“三维Rank = 2 VEC(1)模型”SeriesNames:“Y1”“Y2”“Y3”NumSeries: 3 Rank: 2 P: 2常数:[-1 -3 -30]'调整:[3×2矩阵]协整:[3×2矩阵]影响:[3×3矩阵]协整常量:[2×1向量的NaNs]协整趋势:[2×1向量的NaNs] ShortRun: {3×3矩阵}在滞后[1]趋势:[3×1向量的零]Beta: [3×0矩阵]协方差:[3×3矩阵]
Mdl是否有效地完全指定结果模型对象。即协整常数和线性趋势是未知的。然而,由于总体常数和趋势参数是已知的,模拟观测或预测不需要它们。
从三维高斯分布中生成100个观测值的1000条路径。numobs是数据中没有任何缺失值的观察数。
Numobs = 100;Numpaths = 1000;rng (1);Z = randn(nummobs, mll . numseries,numpaths);
通过估计模型对扰动进行滤波。返回创新(缩放扰动)。
[Y,E] = filter(Mdl,Z);
Y而且E分别为100 × 3 × 1000矩阵的滤波响应和缩放扰动。
对于每个时间点,计算所有路径之间的过滤响应的平均向量。
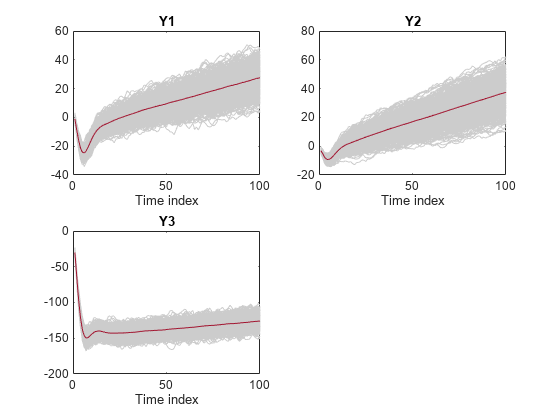
MeanFilt = mean(Y,3);
MeanFilt是一个100 × 3矩阵,包含每个时间点过滤响应的平均值。
将过滤后的响应和它们的平均值画出来。
图;为j = 1:Mdl。NumSeriessubplot(2,2,j) plot(squeeze(Y(:,j,:)),“颜色”, 0.8, 0.8, 0.8)标题(Mdl.SeriesNames {j});持有在情节(MeanFilt (:, j));包含(“时间指数”)举行从结束
用VEC模型滤波扰动时间表
拟合VEC(1)模型到7个宏观经济序列。然后,通过估计模型滤波高斯分布扰动的多个随机路径,模拟响应。在时间表中提供干扰。本例是基于拟合VEC(1)模型与响应数据矩阵.
加载和预处理数据
加载Data_USEconVECModel数据集。
负载Data_USEconVECModel头(FRED)
时间GDP GDPDEF COE HOANBS FEDFUNDS PCEC GPDI ___________ ___________ ___________ ________ _________ 31-Mar-1957 470.6 16.485 260.6 54.756 2.96 282.3 77.7 30- june -1957 472.8 16.601 265.1 54.639 3 284.6 77.9 30- 9 -1957 480.3 16.701 265.1 54.375 3.47 289.2 79.3 31- 12 -1957 475.7 16.711 263.7 53.249 2.98 290.8 71 31-Mar-1958 468.4 16.892 269.9 51.297 0.93 293.2 65.1 30- 9 -1958 486.7 17.043 267.7 51.908 1.76 298.3 72 31- 12 -1958 500.4 17.123272.7 52.683 2.42 302.2 80
通过应用对数变换,稳定除联邦基金利率外的所有系列。将生成的系列按100缩放,以便所有系列都在相同的比例上。
弗雷德。国内生产总值=100*log(FRED.GDP); FRED.GDPDEF = 100*log(FRED.GDPDEF); FRED.COE = 100*log(FRED.COE); FRED.HOANBS = 100*log(FRED.HOANBS); FRED.PCEC = 100*log(FRED.PCEC); FRED.GPDI = 100*log(FRED.GPDI); numobs = height(FRED)
nummobs = 240
准备评估时间表
当你计划直接提供时间表进行估算时,你必须确保它具备以下所有特征:
所有选择的响应变量都是数字,不包含任何缺失值。
中的时间戳
时间变量是规则的,它们是上升或下降的。
从表中删除所有缺失的值。
DTT = rmmissing(FRED);nummobs =身高(DTT)
nummobs = 240
德勤不包含任何缺失值。
确定采样时间戳是否具有规则频率并进行排序。
areTimestampsRegular = isregular(DTT,“季度”)
areTimestampsRegular =逻辑0
areTimestampsSorted = issorted(DTT.Time)
areTimestampsSorted =逻辑1
areTimestampsRegular = 0表示DTT时间戳是不规则的。areTimestampsSorted = 1表示时间戳已排序。本例中的宏观经济序列的时间戳为月底。这种性质导致了一个不规则的测量序列。
通过将所有日期转移到季度的第一天来纠正时间不规律。
dt = dt .时间;Dt =移码(Dt,“开始”,“季”);德勤。时间=dt;areTimestampsRegular = isregular(DTT,“季度”)
areTimestampsRegular =逻辑1
德勤对于时间是有规律的。
模型与数据拟合
使用简写语法创建VEC(1)模型。指定变量名。
Mdl = vecm(7,4,1);Mdl。SeriesNames = string(FRED.Properties.VariableNames);
估计模型。通过整个时间表德勤.默认情况下,估计中的响应变量Mdl。SeriesNames适合模型。或者,您可以使用ResponseVariables名称-值参数。
EstMdl =估计(Mdl,DTT);
模拟扰动路径
生成一个numobs——- - - - - -numseries——- - - - - -numpaths独立随机高斯分布值的数组,其中numobs是数据中观测值的数量,numseries响应系列7的个数,和numpaths是100。将模拟路径矩阵添加到数据集中德勤.
rng (1)%用于再现性nummobs = height(DTT);numseries = estmld . numseries;Numpaths = 100;Z = mvnrnd(零(numseries,1),眼睛(numseries), nummobs *numpaths);Z =重塑(Z, nummobs,numseries,numpaths);为j = 1:numseries DTT = addvars(DTT,squeeze(Z(:,j,:))),...NewVariableNames =“Z_”+ EstMdl.SeriesNames {j});结束头(德勤)
时间GDP GDPDEF COE HOANBS FEDFUNDS PCEC GPDI Z_GDP Z_GDPDEF Z_COE Z_HOANBS Z_FEDFUNDS Z_PCEC Z_GPDI ___________ ______ ______ ______ ______ ________ ______ ______ ____________ ____________ ____________ ____________ ____________ ____________ ____________ 01 - 1月- 1957 615.4 280.25 556.3 400.29 2.96 564.3 435.29 1 x100双1 x100双1 x100双1 x100双x100双1 x100双1 x100双01 - 4月- 1957 615.87 280.95 557.03 565.11 - 435.54 400.07 - 3 1 x100双1 x100双1 x100翻倍1x100双1x100双1x100双1x100双1x100双1x100双1x100双1x100双1x100双1x100双1x100双1x100双1x100双1x100双1x100双01 - 4月- 1958 615.87 282.97 556.03 393.76 0.93 568.09 417.59 1 x100双1 x100双1 x100双1 x100双x100双1 x100双1 x100双01 - 7 - 1958 618.76 283.57 558.99 394.95 1.76 569.81 427.67 1 x100双1 x100双1 x100双1 x100双x100双1 x100双1 x100双01 - 10月- 1958 621.54 284.04 560.84 396.43 2.42 571.11 438.2 1 x100双1 x100双1 x100双1 x100双x100双1 x100双1 x100翻倍
通过模型滤波扰动
当你用时间表过滤干扰时,过滤器需要一个样品。将时间表分成预样本和样本内数据集。预样本数据是初始值EstMdl。P观测值,样本内数据集包含其余观测值。
Presample = DTT(1:EstMdl.P,:);InSample = DTT((EstMdl.)P + 1):结束,:);
通过估计模型滤波样本内扰动,模拟响应路径。指定扰动序列的变量名、预采样数据和预采样中的响应变量名。
dnames = string(DTT.Properties.VariableNames);idx = startsWith(dnames,“Z_”);Dnames = Dnames (idx);Tbl2 = filter(EstMdl,InSample,捣乱变量=dnames,...Presample = Presample PresampleResponseVariables = EstMdl.SeriesNames);大小(Tbl2)
ans =1×2238年28
头(Tbl2)
时间GDP GDPDEF COE HOANBS FEDFUNDS PCEC GPDI Z_GDP Z_GDPDEF Z_COE Z_HOANBS Z_FEDFUNDS Z_PCEC Z_GPDI GDP_Responses GDPDEF_Responses COE_Responses HOANBS_Responses FEDFUNDS_Responses PCEC_Responses GPDI_Responses GDP_Innovations GDPDEF_Innovations COE_Innovations HOANBS_Innovations FEDFUNDS_Innovations PCEC_Innovations GPDI_Innovations ___________ ______ ______ ______ ______ ________ ______ ______ ____________ ____________ ____________ ____________ ____________ ____________ _________________________ ________________ _____________ ________________ __________________ ______________ ______________ _______________ __________________ _______________ __________________ ____________________ ________________ ________________ 01 - 7 - 1957 617.44 281.55 558.01 399.59 3.47 566.71 437.32 1 x100双1 x100双1 x100双1 x100双x100双1 x100双1 x100双1 x100双1 x100双1 x100双x100双1 x100双1 x100 x100双1 x100双1 x100的两倍双1 x100双x100双1 x100双1 x100双1 x100双01 - 10月- 1957 616.48 281.61 557.48 397.5 2.98 567.26 426.27 1 x100双1 x100双1 x100双1 x100双x100双1 x100双1 x100双1 x100双x100双1 x100双1 x100双1 x100双1 x100双1 x100双1 x100双1 x100双1 x100双1 x100双1 x100双1 x100双1 x100双01 - 1月- 1958 614.93 282.68 556.15 395.21 1.2 567.09 420.02 1 x100双1 x100双1 x100翻倍x100双1 x100双1 x100双1 x100双1 x100双1 x100双x100双1 x100双1 x100双1 x100双1 x100双1 x100双x100双1 x100双1 x100双1 x100双1 x100双1 x100双01 - 4月- 1958 615.87 282.97 556.03 393.76 0.93 568.09 417.59 1 x100双1 x100双1 x100双1 x100双1 x100双1 x100双1 x100双1 x100双1 x100双1 x100双1 x100双1 x100双1 x100双x100双1 x100双1 x100翻倍1x100双1x100 double 1x100 double 1x100 double 1x100 double 01-Jul-1958 618.76 283.57 558.99 394.95 1.76 569.81 427.67 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 01-Oct-1958 621.54 284.04 560.84 396.43 2.42 571.11 438.2 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 01-Jan-1959 623.66 284.31 563.55 398.35 2.8 573.62 442.12 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 01-Apr-1959 626.19 284.46 565.91 400.24 3.39 575.54 449.31 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double 1x100 double
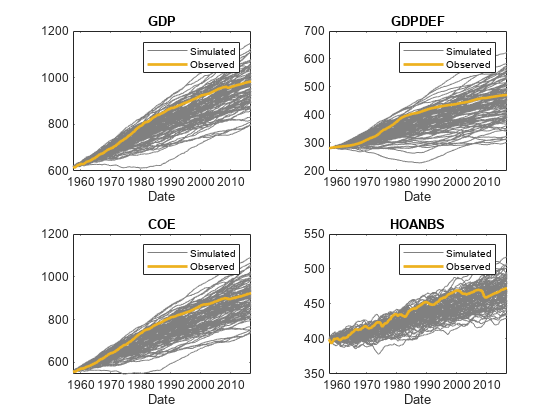
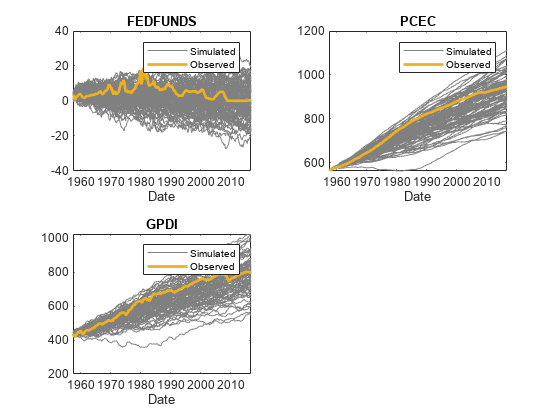
Tbl2是一个238 × 2的样本内数据矩阵,模拟扰动的路径,过滤响应的路径(变量名附加_Responses,和创新路径(名称后跟_Innovations)。
rnames = string(Tbl2.Properties.VariableNames);idx = endsWith(rnames,“_Responses”);Rnames = Rnames (idx);图tiledlayout (2, 2)为nexttile p1 = plot(Tbl2. time,Tbl2{:,rnames(j)},Color=[0.5 0.5 0.5]);持有在p2 = plot(Tbl2. time,Tbl2{:, mll . seriesnames (j)},LineWidth=2);标题(Mdl.SeriesNames (j))包含(“日期”)传说([p1(1) p2],[“模拟”“观察”])结束
图tiledlayout (2, 2)为nexttile p1 = plot(Tbl2. time,Tbl2{:,rnames(j)},Color=[0.5 0.5 0.5]);持有在p2 = plot(Tbl2. time,Tbl2{:, mll . seriesnames (j)},LineWidth=2);标题(Mdl.SeriesNames (j))包含(“日期”)传说([p1(1) p2],[“模拟”“观察”])结束
输入参数
输出参数
算法
过滤器概括模拟.这两个功能都是通过一个模型来过滤一个扰动序列,从而产生响应和创新。然而,而模拟生成一系列均值-零,单位-方差,独立的高斯扰动Z形成创新E=L * Z,过滤器使您能够提供来自任何分布的干扰。过滤器使用此过程来确定时间原点t0包含线性时间趋势的模型。如果您没有指定
Y0,然后t0= 0。否则,
过滤器集t0来大小(Y0, 1)- - - - - -Mdl。P.因此,趋势分量中的次数为t=t0+ 1,t0+ 2,…,t0+numobs,在那里numobs有效样本量(大小(Y, 1)后过滤器删除缺失的值)。这种约定与模型估计的默认行为是一致的估计删除第一个Mdl。P反应,减少有效样本量。虽然过滤器显式地使用第一个Mdl。P在Y0为初始化模型,在Y0而且Y(不包括缺失值)决定t0.
参考文献
[1]汉密尔顿,詹姆斯D。时间序列分析.普林斯顿,新泽西州:普林斯顿大学出版社,1994。
[2]约翰森,S。协整向量自回归模型中的似然推理.牛津:牛津大学出版社,1995年。
[3]Juselius, K。协整VAR模型.牛津:牛津大学出版社,2006年。
[4]Lutkepohl, H。多重时间序列分析新导论.柏林:施普林格,2005。
版本历史
在R2017b中引入
您也可以从以下列表中选择一个网站: