使用观察重量的信用记分卡建模
创建A.CreditsCorecard.对象,用于输入的表数据参数定义或未定义观察权重。如果是数据不使用权重,然后是“计数”好的那坏的, 和赔率使用信用记分卡功能使用。但是,如果是可选的掌权创建A时指定参数CreditsCorecard.对象,然后“计数”好的那坏的, 和赔率是权重的总和。
例如,这是一个没有定义观察权重的输入表的片段:

如果您在客户年龄预测数据中介入客户,请在一个垃圾箱中最多45岁,46岁及以上的另一箱,你得到这些统计数据:
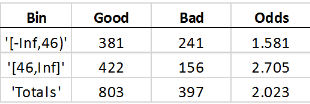
好的意味着带有的行总行数0.价值在地位响应变量。坏的的数量1在里面地位柱子。赔率是比率好的至坏的。这好的那坏的, 和赔率报告每个垃圾箱。这意味着样品中有381人,谁在谁支付贷款,241人在违约年龄的同一年度范围内,因此,对那个年龄范围有利的几率是1.581。
假设建模者认为,在这个样本中,人们45名和年轻人在这个样本中经历了不足。建模者想要给所有的行超过45岁的重量。假设建模者认为最多45岁的年龄组应该比46岁及以上的行增加50%。表数据扩展以包括观察权重。一种重量列被添加到表中,其中所有带有年龄的行和重量的行1.5,以及所有其他行的重量1。例如,还有使用权重的其他原因,例如,最近的数据点可以给出比较旧的数据点更高的权重。

如果您在基于年龄(45岁以下的重量数据(第46和UP)中,期望的是每行具有年龄45岁及以下的每行,必须计入1.5个观察,因此好的和坏的“计数”增加了50%:
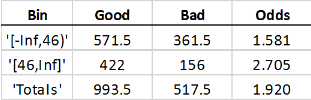
“计数”现在是“加权频率”,并且不再是整数值。这赔率不要改变第一个垃圾箱。在此示例中给出的特定权重具有缩放总数的效果好的和坏的通过相同的缩放因子计数第一个箱子,因此它们的比率不会改变。然而赔率总样品的值确实改变;第一个垃圾箱现在携带更高的重量,因为该箱子的赔率较低,总计赔率现在也很低。这里未显示的其他信用记分卡统计信息,例如w和信息价值受到类似的影响。
通常,权重的效果不仅仅是特定垃圾箱中的刻度频率,因为该箱的成员将具有不同的权重。此示例的目标是展示从计数到权重的概念。
也可以看看
autobinning.|宾FO.|CreditsCorecard.|Fitmodel.|viewatemodel.
相关话题
您还可以从以下列表中选择一个网站:
