autobinning
对给定的预测器执行自动分类
描述
sc= autobinning (sc那PredictorNames)PredictorNames.
自动分类查找分类映射或规则,将数字数据分类并对分类数据分类分组。存储在creditscorecard对象。要应用分级规则的creditscorecard对象数据,或新的数据集,使用bindata..
例子
使用默认值执行自动衬合
创建一个creditscorecard对象使用CreditCardData.mat文件加载数据(使用来自Refaat 2011的数据集)。
加载CreditCardDatasc = creditscorecard(数据,“IDVar”那“客户ID”);
使用默认选项执行自动分类。默认情况下,autobinning将所有预测器装箱并使用单调算法。
sc = autobinning (sc);
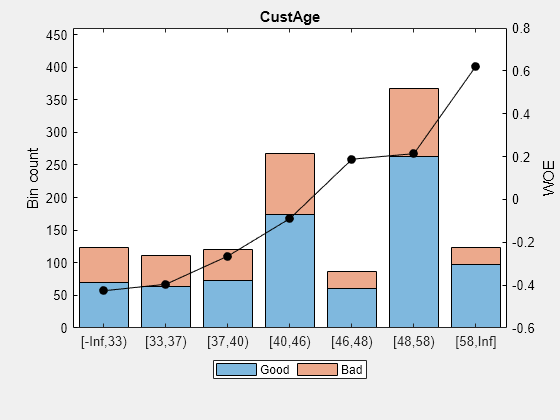
使用bininfo显示预测器的分类数据CustAge.
bi = bininfo (sc,“CustAge”)
bi =8×6表本好不好悲哀InfoValue几率 _____________ ____ ___ ______ _________ _________ {'[- 正无穷,33)}70年53 1.3208 -0.42622 0.019746{[33岁,37)}64年47 1.3617 -0.39568 0.015308{[37、40)}73年47 1.5532 -0.26411 0.0072573{'[40岁,46)}174 94 1.8511 -0.088658 0.001781{25[46岁,48)}61 2.44 0.18758 0.0024372 {[48,58)}263 105 2.5048 0.21378 0.013476{'[58,Inf]'} 98 26 3.7692 0.62245 0.0352{'总计'}803 397 2.0227 NaN 0.095205
使用plotbins显示预测器的直方图和WOE曲线CustAge.
plotbins (sc,“CustAge”)
使用默认值使用命名预测器执行自动分类
创建一个creditscorecard对象使用CreditCardData.mat文件来加载数据(使用Refaat 2011的数据集)。
加载CreditCardDatasc = creditscorecard(数据);
对预测器执行自动分类CustIncome使用默认选项。默认情况下,autobinning使用单调算法。
sc = autobinning (sc,“CustIncome”);
使用bininfo显示已装箱的数据。
bi = bininfo (sc,“CustIncome”)
bi =8×6表本好不好悲哀InfoValue几率 _________________ ____ ___ _______ _________ __________ {'[- 正无穷,29000)}53 58 0.91379 -0.79457 0.06364{[29000、33000)}74年49 1.5102 -0.29217 0.0091366{[33000、35000)的36}68 1.8889 -0.06843 0.00041042{[35000、40000)的}193 98 1.9694 -0.026696 0.00017359{[40000、42000)}68 2 -0.011271 - 1.0819 e-05 34{'[42000,47000)'} 164 66 2.4848 0.20579 0.0078175 {'[47000,Inf]'} 183 56 3.2679 0.47972 0.041657 {' total '} 803 397 2.0227 NaN 0.12285
使用两个名称-值对参数执行自动分类
创建一个creditscorecard对象使用CreditCardData.mat文件来加载数据(使用Refaat 2011的数据集)。
加载CreditCardDatasc = creditscorecard(数据);
对预测器执行自动分类CustIncome使用单调初始箱数设置为20的算法。这个例子显式地设置了算法和AlgorithmOptions名称-值参数。
AlgoOptions = {“InitialNumBins”, 20};sc = autobinning (sc,“CustIncome”那“算法”那“单调”那'algorithmOptions'那...algoOptions);
使用bininfo显示已装箱的数据。这里还显示了分隔容器的切点。
(bi, cp) = bininfo (sc,“CustIncome”)
bi =11×6表本好不好悲哀InfoValue几率 _________________ ____ ___ _______ _________ __________ {'[- 正无穷,19000)}2 3 0.66667 -1.1099 0.0056227{[19000、29000)的55}51 0.92727 -0.77993 0.058516{[29000、31000)的}29日26日1.1154 -0.59522 0.017486{[31000、34000)}80年42 1.9048 -0.060061 0.0003704{[34000、35000)的}33 17 1.9412 -0.041124 7.095 e-05{'[35000,40000)'} 193 98 1.9694 -0.026696 0.00017359 {'[40000,42000)'} 68 34 2 -0.011271 1.0819e-05 {'[42000,43000)'} 39 16 2.4375 0.18655 0.001542 {'[43000,47000)'} 125 50 2.5 0.21187 0.0062972 {'[47000,Inf]'} 183 3.2679 0.47972 0.041657{'总计'}803 397 2.0227 NaN 0.13175
cp =9×119000 29000 31000 34000 35000 40000 42000 43000 47000
使用多个名称值对参数执行自动分键
这个例子展示了如何使用autobinning默认的单调算法和AlgorithmOptions关联的名称-值对参数单调算法。这AlgorithmOptions为单调算法是三个名称-值对参数:“InitialNumBins”那“趋势”,“SortCategories”.“InitialNumBins”和“趋势”是否适用于数值预测和“趋势”和“SortCategories”适用于分类预测。
创建一个creditscorecard对象使用CreditCardData.mat文件加载数据(使用来自Refaat 2011的数据集)。
加载CreditCardDatasc = creditscorecard(数据,“IDVar”那“客户ID”);
对数值预测器执行自动分类CustIncome使用单调算法20个箱。这个例子显式地设置了算法参数和AlgorithmOptions名称-值参数“InitialNumBins”和“趋势”.
AlgoOptions = {“InitialNumBins”, 20岁,“趋势”那“增加”};sc = autobinning (sc,“CustIncome”那“算法”那“单调”那...'algorithmOptions', AlgoOptions);
使用bininfo显示已装箱的数据。
bi = bininfo (sc,“CustIncome”)
bi =11×6表本好不好悲哀InfoValue几率 _________________ ____ ___ _______ _________ __________ {'[- 正无穷,19000)}2 3 0.66667 -1.1099 0.0056227{[19000、29000)的55}51 0.92727 -0.77993 0.058516{[29000、31000)的}29日26日1.1154 -0.59522 0.017486{[31000、34000)}80年42 1.9048 -0.060061 0.0003704{[34000、35000)的}33 17 1.9412 -0.041124 7.095 e-05{'[35000,40000)'} 193 98 1.9694 -0.026696 0.00017359 {'[40000,42000)'} 68 34 2 -0.011271 1.0819e-05 {'[42000,43000)'} 39 16 2.4375 0.18655 0.001542 {'[43000,47000)'} 125 50 2.5 0.21187 0.0062972 {'[47000,Inf]'} 183 3.2679 0.47972 0.041657{'总计'}803 397 2.0227 NaN 0.13175
为多个预测器执行自动分类
创建一个creditscorecard对象使用CreditCardData.mat文件来加载数据(使用Refaat 2011的数据集)。
加载CreditCardDatasc = creditscorecard(数据,“IDVar”那“客户ID”);
对预测器执行自动分类CustIncome和CustAge使用默认单调算法与AlgorithmOptions为了InitialNumBins和趋势.
AlgoOptions = {“InitialNumBins”, 20岁,“趋势”那“增加”};sc = autobinning (sc, {“CustAge”那“CustIncome”},“算法”那“单调”那...'algorithmOptions', AlgoOptions);
使用bininfo显示已装箱的数据。
bi1 = bininfo (sc,“CustIncome”)
BI 1 =11×6表本好不好悲哀InfoValue几率 _________________ ____ ___ _______ _________ __________ {'[- 正无穷,19000)}2 3 0.66667 -1.1099 0.0056227{[19000、29000)的55}51 0.92727 -0.77993 0.058516{[29000、31000)的}29日26日1.1154 -0.59522 0.017486{[31000、34000)}80年42 1.9048 -0.060061 0.0003704{[34000、35000)的}33 17 1.9412 -0.041124 7.095 e-05{'[35000,40000)'} 193 98 1.9694 -0.026696 0.00017359 {'[40000,42000)'} 68 34 2 -0.011271 1.0819e-05 {'[42000,43000)'} 39 16 2.4375 0.18655 0.001542 {'[43000,47000)'} 125 50 2.5 0.21187 0.0062972 {'[47000,Inf]'} 183 3.2679 0.47972 0.041657{'总计'}803 397 2.0227 NaN 0.13175
bi2 = bininfo (sc,“CustAge”)
bi2 =8×6表本好不好悲哀InfoValue几率 _____________ ____ ___ ______ _________ __________ {'[- 正无穷,35)}93 76 1.2237 -0.50255 0.038003{[35 40)的}114 71 1.6056 -0.2309 0.0085141{[40,42岁)的}52 30 1.7333 -0.15437 0.0016687{[42、44)的}58 32 1.8125 -0.10971 0.00091888{[44岁,47)}97年51 1.902 -0.061533 0.00047174 {' [62)}333 130 2.5615 - 0.236190.020605 {'[62,Inf]'} 56 7 8 1.375 0.071647{'总计'}803 397 2.0227 NaN 0.14183
使用默认值对分类预测器执行自动分类
创建一个creditscorecard对象使用CreditCardData.mat文件来加载数据(使用Refaat 2011的数据集)。
加载CreditCardDatasc = creditscorecard(数据);
对被称为分类预测器的预测器执行自动分类ResStatus使用默认选项。默认情况下,autobinning使用单调算法。
sc = autobinning (sc,'resstatus');
使用bininfo显示已装箱的数据。
bi = bininfo (sc,'resstatus')
bi =4×6表Bin Good Bad Odds WOE InfoValue ______________ _____________ _________ _________ {'Tenant'} 307 167 1.8383 -0.095564 0.0036638 {'Home Owner'} 365 177 2.0621 0.019329 0.0001682 {'Other'} 131 53 2.4717 0.20049 0.0059418 {' total '} 803 397 2.0227 NaN 0.0097738
使用名称-值对参数对分类预测器执行自动分类
此示例显示如何修改数据(仅用于此示例)以说明使用该分类的分类预测器单调算法。
创建一个creditscorecard对象使用CreditCardData.mat文件来加载数据(使用Refaat 2011的数据集)。
加载CreditCardData
添加两个新类别并更新响应变量。
newdata =数据;rng (“默认”);%,持续重现预测='resstatus';status = newdata.status;numobs = length(newdata。(predictor));Ind1 = Randi(numobs,100,1);Ind2 = Randi(numobs,100,1);newdata。(预测器)(Ind1)=“转租人”;newdata。(Ind2) =(预测)“共同所有人”;状态(Ind1) =兰迪(2100 1)1;状态(Ind2) =兰迪(2100 1)1;newdata。状态=状态;
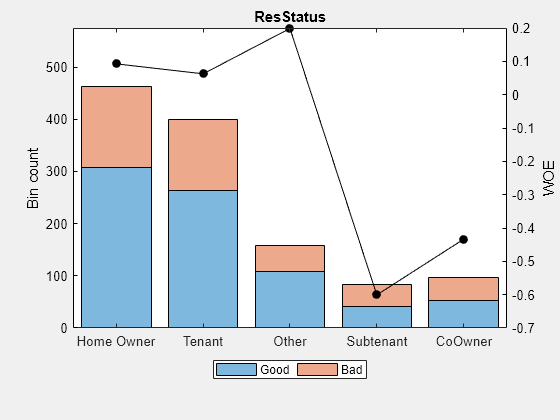
更新creditscorecard对象使用newdata并将这些箱子绘制出来,以便以后进行比较。
scnew = creditscorecard (newdata,“IDVar”那“客户ID”);(bi, cg) = bininfo (scnew预测)
bi =6×6表本好不好悲哀InfoValue几率 ______________ ____ ___ ______ ________ _________ {' 房主}308 154 2 0.092373 - 0.0032392{“租户”}264 136 1.9412 0.06252 0.0012907{‘其他’}109年49 2.2245 0.19875 0.0050386{转租人的}42 42 1 -0.60077 - 0.026813{“共同所有人”}52 44 1.1818 -0.43372 0.015802{“总数”}775 425 0.052183 1.8235南
cg =5×2表类别BinNumber ______________ _________ {' 房主'}1{“租户”}2{‘其他’}3{转租人的}4{“共同所有人”}5
plotbins (scnew预测)
对类别执行自动分类预测使用默认单调算法的AlgorithmOptions名称 - 值对参数“SortCategories”和“趋势”.
AlgoOptions = {“SortCategories”那'商品'那“趋势”那“增加”};Scnew = autobinning(Scnew,Predictor,“算法”那“单调”那...'algorithmOptions', AlgoOptions);
使用bininfo显示bin信息。第二个输出参数“重心”获取bin成员关系,即每个组所属的bin编号。
(bi, cg) = bininfo (scnew预测)
bi =4×6表Bin Good Bad Odds WOE InfoValue __________ _______ ______ ________ _________ {'Group1'} 42 42 1 -0.60077 0.026813 {'Group2'} 52 44 1.1818 -0.43372 0.015802 {'Group3'} 681 339 2.0088 0.096788 0.0078459 {' total '} 775 425 1.8235 NaN 0.05046
cg =5×2表类别BinNumber ______________ _________ {' 转租人'}1{“共同所有人”}2{‘其他’}3{“租户”}3{‘业主’}3
绘制箱和比较直方图绘制的预先换水。
plotbins (scnew预测)

执行Automatic Binning When使用缺失数据
创建一个creditscorecard对象使用CreditCardData.mat文件来加载Datamissing.与缺失值。
加载CreditCardData.mat头(dataMissing, 5)
ans =5×11表CustID CustAge TmAtAddress ResStatus EmpStatus CustIncome TmWBank OtherCC AMBalance UtilRate地位 ______ _______ ___________ ___________ _________ __________ _______ _______ _________ ________ ______ 53 62 <定义>未知50000 55是的1055.9 - 0.22 0 2 61 22业主雇佣52000 25是的1161.6 - 0.24 0 3 47 30租户雇佣了37000 61877.23 0.29 0 4 NaN 75自雇业主53000 20是157.37 0.08 0 5 68 56自雇业主53000 14是561.84 0.11 0
fprintf('行数:%d\n',高度(Datamissing))
行数:1200行
fprintf('缺少值的数量汇编:%d \ n'总和(ismissing (dataMissing.CustAge)))
缺失值的数量汇编:30
fprintf(restatus: %d\n总和(ismissing (dataMissing.ResStatus)))
ResStatus: 40
使用creditscorecard使用name-value参数'BinMissingData'设置为真正的将丢失的数字和分类数据装入单独的容器中。
sc = creditscorecard(Datamissing,'BinMissingData',真正的);disp (sc)
creditscorecard with properties: GoodLabel: 0 ResponseVar: 'status' WeightsVar: " VarNames: {1x11 cell} NumericPredictors: {1x7 cell} CategoricalPredictors: {'ResStatus' 'EmpStatus' 'OtherCC'} BinMissingData: 1 IDVar: " PredictorVars: {1x10 cell} Data: [1200x11 table]
属性执行自动分类合并算法。
sc = autobinning (sc,“算法”那“合并”);
显示bin信息的数字数据“CustAge”这包括在一个单独的标签箱中丢失的数据<失踪>这是最后一个箱子。不管用什么分类算法autobinning,该算法的非丢失的数据和料仓工作<失踪>预测器的数值总是在最后一个容器中。
(bi, cp) = bininfo (sc,“CustAge”);disp (bi)
宾好差赔率WOE INFOVALUE _____________ ____ ___ _______ ________ __________ { '[-Inf,32)'} 56 39 1.4359 -0.34263 0.0097643 { '[32,33)'} 13 13 1 -0.70442 0.011663 {'[33,34)'} 9 11 0.81818 -0.90509 0.014934 {'[34,65)”} 677 317 2.1356 0.054351 0.002424 { '[65,天道酬勤]'} 29 6 4.8333 0.87112 0.018295 { '<缺失>'} 19 11 1.7273 -0.15787 0.00063885 {'总计'} 803 397 2.0227的NaN 0.057718
plotbins (sc,“CustAge”)

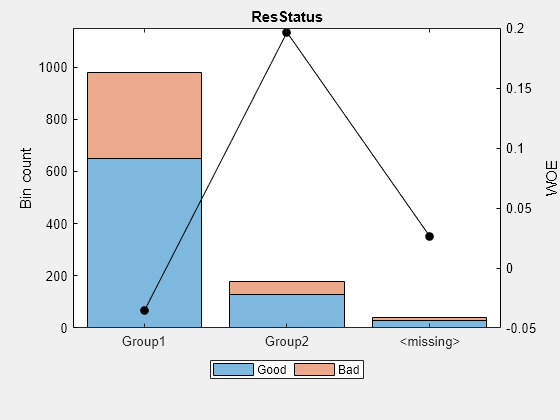
显示垃圾箱信息,用于分类数据'resstatus'这包括在一个单独的标签箱中丢失的数据<失踪>这是最后一个箱子。不管用什么分类算法autobinning,该算法的非丢失的数据和料仓工作<失踪>预测器的分类值总是最后一个箱子。
(bi, cg) = bininfo (sc,'resstatus');disp (bi)
Bin Good Bad Odds WOE InfoValue _____________ _____________ _________ __________ {'Group1'} 648 332 1.9518 -0.035663 0.0010449 {'Group2'} 128 52 2.4615 0.19637 0.0055808 {''} 27 13 2.0769 0.026469 2.3248e-05 {' total '} 803 397 2.0227 NaN 0.0066489
plotbins (sc,'resstatus')
使用分割算法进行自动分类
这个示例演示如何使用'分裂'算法与分类和数字预测。加载CreditCardData.mat数据集和修改,以便它包含预测器的四个类别ResStatus”演示分割算法是如何工作的。
加载CreditCardData.matx = data.ResStatus;find(x == .“租户”);Nx =长度(印第安纳州);x(印第安纳州(1:地板(Nx / 3))) ='Subletter';数据。ResStatus = x;
创建一个creditscorecard和使用bininfo来显示'统计数据'.
sc = creditscorecard(数据,“IDVar”那“客户ID”);[bi1, cg1] = bininfo (sc,'resstatus'那'统计数据',{“赔率”那“悲伤”那“InfoValue”});disp (bi1)
Bin Good Bad Odds WOE InfoValue ______________ _____________ _________ __________ {'Home Owner'} 365 177 2.0621 0.019329 0.0001682 {'Tenant'} 204 112 1.8214 -0.1048 0.0029415 {'Other'} 131 53 2.4717 0.20049 0.0059418 {'Subletter'} 103 55 1.8727 -0.077023 0.00079103 {' total '} 803 397 2.0227 NaN 0.0098426
disp (cg1)
类别BinNumber ______________ _________ {' 房主'}1{“租户”}2{‘其他’}3{“转租”}4
使用带有分类预测器的分割算法
将排序应用到'resstatus'类别使用默认排序“赔率”并指定'分裂'算法。
sc = autobinning (sc,'resstatus'那“算法”那“分裂”那'algorithmOptions'那...{“测量”那“基尼”那“SortCategories”那“几率”那“宽容”1的军医});[bi2, cg2] = bininfo (sc,'resstatus'那'统计数据',{“赔率”那“悲伤”那“InfoValue”});disp (bi2)
Bin Good Bad Odds WOE InfoValue __________ _______ ______ _________ _________ {'Group1'} 307 167 1.8383 -0.095564 0.0036638 {'Group2'} 365 177 2.0621 0.019329 0.0001682 {'Group3'} 131 53 2.4717 0.20049 0.0059418 {' total '} 803 397 2.0227 NaN 0.0097738
disp (cg2)
类别BinNumber ______________ _________ {' 租户的}{“转租”}1{‘业主’}2{‘其他’}3
使用拆分算法用数字预测
为了演示数字预测器“T”的分裂mAtAddress”,第一次使用autobinning使用默认“单调”算法。
sc = autobinning (sc,“TmAtAddress”);bi3 = bininfo (sc,“TmAtAddress”那'统计数据',{“赔率”那“悲伤”那“InfoValue”});disp (bi3)
宾好差赔率WOE INFOVALUE _____________ ____ ___ ______ _________ __________ { '[-Inf,23)'} 239 129 1.8527 -0.087767 0.0023963 { '[23,83)'} 480 232 2.069 0.02263 0.00030269 { '[83,天道酬勤]'} 84 36 2.3333 0.14288 0.00199 { '总计'} 803 397 2.0227的NaN 0.004689
然后使用autobinning与'分裂'算法。
sc = autobinning (sc,“TmAtAddress”那“算法”那'分裂');闭= bininfo (sc,“TmAtAddress”那'统计数据',{“赔率”那“悲伤”那“InfoValue”});disp(闭)
本好不好悲哀InfoValue几率 ____________ ____ ___ _______ _________ __________ {'[- 正无穷,4)“20 12 1.6667 -0.19359 0.0010299{}(4、5)}4 7 0.57143 -1.264 0.015991{”(23)}215 110 1.9545 -0.034261 0.00031973{[23日,33)}130年39 3.3333 0.49955 0.0318{”(33岁,正)}434 229 1.8952 -0.065096 0.0023664{“总数”}803 397 2.0227 0.051507南
使用合并算法执行自动分类
加载CreditCardData.mat数据集。这个示例演示如何使用“合并”算法与分类和数字预测。
加载CreditCardData.mat
使用带有分类预测器的合并算法
要合并分类预测仪,请创建一个creditscorecard使用默认排序“赔率”然后使用bininfo在绝对预测器上'resstatus'.
sc = creditscorecard(数据,“IDVar”那“客户ID”);[bi1, cg1] = bininfo (sc,'resstatus'那'统计数据',{“赔率”那“悲伤”那“InfoValue”});disp (bi1);
Bin Good Bad Odds WOE InfoValue ______________ _____________ _________ _________ {'Home Owner'} 365 177 2.0621 0.019329 0.0001682 {'Tenant'} 307 167 1.8383 -0.095564 0.0036638 {'Other'} 131 53 2.4717 0.20049 0.0059418 {' total '} 803 397 2.0227 NaN 0.0097738
disp (cg1);
类别BinNumber ______________ _________ {' 房主'}1{“租户”}2{‘其他’}3
使用autobinning并指定“合并”算法。
sc = autobinning (sc,'resstatus'那“算法”那“合并”);[bi2, cg2] = bininfo (sc,'resstatus'那'统计数据',{“赔率”那“悲伤”那“InfoValue”});disp (bi2)
Bin Good Bad Odds WOE InfoValue __________ _______ ______ _________ _________ {'Group1'} 672 344 1.9535 -0.034802 0.0010314 {'Group2'} 131 53 2.4717 0.20049 0.0059418 {' total '} 803 397 2.0227 NaN 0.0069732
disp (cg2)
类别BinNumber ______________ _________ {' 租户的}{‘业主’}1{‘其他’}2
使用带有数值预测器的合并算法
演示数字预测器T的合并mAtAddress”,第一次使用autobinning使用默认“单调”算法。
sc = autobinning (sc,“TmAtAddress”);bi3 = bininfo (sc,“TmAtAddress”那'统计数据',{“赔率”那“悲伤”那“InfoValue”});disp (bi3)
宾好差赔率WOE INFOVALUE _____________ ____ ___ ______ _________ __________ { '[-Inf,23)'} 239 129 1.8527 -0.087767 0.0023963 { '[23,83)'} 480 232 2.069 0.02263 0.00030269 { '[83,天道酬勤]'} 84 36 2.3333 0.14288 0.00199 { '总计'} 803 397 2.0227的NaN 0.004689
然后使用autobinning与“合并”算法。
sc = autobinning (sc,“TmAtAddress”那“算法”那“合并”);闭= bininfo (sc,“TmAtAddress”那'统计数据',{“赔率”那“悲伤”那“InfoValue”});disp(闭)
宾好差赔率WOE INFOVALUE _____________ ____ ___ _______ _________ __________ { '[-Inf,28)'} 303 152 1.9934 -0.014566 8.0646e-05 { '[28,30)'} 2 27 13.5 1.8983 0.054264 {'[30,98)”} 428 216 1.9815 -0.020574 0.00022794 { '[98106)'} 11 13 0.84615 -0.87147 0.016599 { '[106,天道酬勤]'} 34 14 2.4286 0.18288 0.0012942 { '总计'} 803 397 2.0227的NaN 0.072466
输入参数
输出参数
更多关于
参考文献
[1]安德森,R。信用评分工具包。牛津大学出版社,2007。
[2]科伯,R。《ChiMerge:数值属性的离散化》aaai - 92程序。1992.
刘洪,等。数据挖掘、知识和发现。6卷。问题4。2002年10月,393-423页。
[4] Refaat, M。数据准备数据挖掘使用SAS。摩根Kaufmann,2006。
[5] Refaat, M。信用风险记分卡:使用SAS开发和实施。lulu.com, 2011。
Thomas, L.等。信用评分及其应用。2002年工业与应用数学协会。
也可以看看
bindata.|bininfo|creditscorecard|displaypoints|fitmodel|formatpoints|ModifierBins.|modifypredictor|plotbins|predictorinfo|probdefault|分数|setmodel.|viewatemodel.
介绍了R2014b
你也可以从以下列表中选择一个网站:
