缺少值的信用记分卡建模
此示例显示了在使用时如何处理缺少的值creditscorecard首先,这个例子展示了如何使用creditscorecard功能,为缺失的数据创建一个显式箱与相应的点。然后,本例描述“处理”缺失数据的四种不同方法获取最终信用记分卡,该记分卡没有针对缺失值的明确BIN。
开发一个信用记分卡,明确缺少价值的BIN
当你创建creditscorecard对象时,数据可能包含丢失的值。当使用creditscorecard创建一个creditscorecard对象的名称-值对参数“BinMissingData”设置为符合事实的.在本例中,数值预测器(南值)和类别预测因子(<未定义>值)装入一个单独的标有“BinMissingData”参数或如果你设置“BinMissingData”来假,creditscorecard函数在计算好的和坏的频率时丢弃丢失的观测值,并且bininfo也不绘图仪函数报告这些观察结果。
的“失踪”在formatpoints,或使用“处理”缺失数据的四种不同方法.
的dataMissing表格CreditCardData.mat文件有两个缺少值的预测器-保管和雷斯塔特斯, .
负载CreditCardData.mat头(dataMissing, 5)
ans=5×11表(UUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUU乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌乌877.23 0.29 0 4南75业主雇佣53000 20是157.37 0.08 0 5 68 56业主雇佣53000 14是561.84 0.11 0
创建一个creditscorecard对象使用CreditCardData.mat文件来加载dataMissing缺少值的表。设定“BinMissingData”论据符合事实的.应用自动装箱。
sc = creditscorecard (dataMissing,“IDVar”,“CustID”,“BinMissingData”,真正的);sc = autobinning (sc);
有缺失数据的预测器的bin信息和bin图都显示
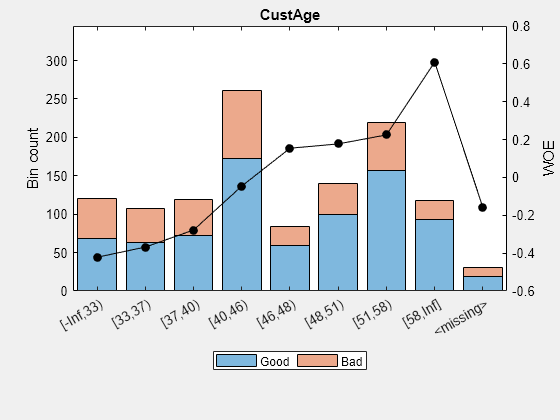
bi=bininfo(sc,“CustAge”);disp(bi)
本好不好悲哀InfoValue几率 _____________ ____ ___ ______ ________ __________ {'[- 正无穷,33)52}69 1.3269 -0.42156 0.018993{[33岁,37)}63年45 1.4 -0.36795 0.012839{[37、40)}72年47 1.5319 -0.2779 0.0079824{'[40岁,46)}172 89 1.9326 -0.04556 0.0004549{'[46岁,48)}59 25 2.36 0.15424 0.0016199{[48,51)}99年41 2.4146 0.17713 0.0035449{'[51,58)'} 157 62 2.5323 0.22469 0.0088407 {'[58,Inf]'} 93 25 3.72 0.60931 0.032198 {''} 19 11 1.7273 -0.15787 0.00063885 {' total '} 803 397 2.0227 NaN 0.087112
plotbins (sc,“CustAge”)
bi=bininfo(sc,“ResStatus”);disp(bi)
Bin Good Bad Odds WOE InfoValue ______________ _____________ _________ __________ {'Tenant'} 296 161 1.8385 -0.095463 0.0035249 {'Home Owner'} 352 171 2.0585 0.017549 0.00013382 {'Other'} 128 52 2.4615 0.19637 0.0055808 {''} 27 13 2.0769 0.026469 2.3248e-05 {' total '} 803 397 2.0227 NaN 0.0092627
plotbins (sc,“ResStatus”)
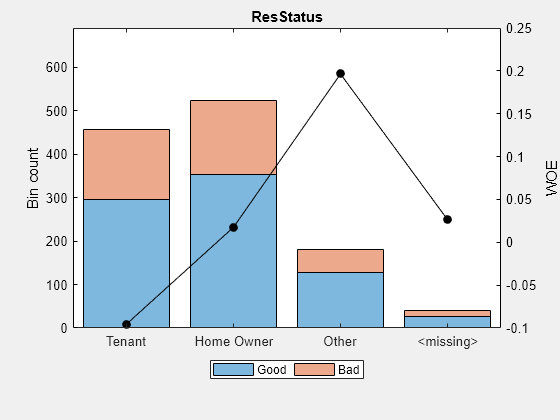
训练数据“CustAge”和“ResStatus”预测器有丢失的数据(南年代和<未定义>).装箱过程估计了以下各项的WOE值:-0.15787和0.026469,分别为这些预测因子中的缺失数据。
的训练数据EmpStatus和CustIncome没有明确的bin用于
bi=bininfo(sc,“EmpStatus”);disp(bi)
本好不好悲哀InfoValue几率 ____________ ____ ___ ______ ________ _________ {' 未知的}396 239 1.6569 -0.19947 0.021715{“雇佣”}407 158 2.5759 0.2418 0.026323{“总数”}803 397 0.048038 2.0227南
bi=bininfo(sc,“CustIncome”);disp(bi)
本好不好悲哀InfoValue几率 _________________ ____ ___ _______ _________ __________ {'[- 正无穷,29000)}53 58 0.91379 -0.79457 0.06364{[29000、33000)}74年49 1.5102 -0.29217 0.0091366{[33000、35000)的36}68 1.8889 -0.06843 0.00041042{[35000、40000)的}193 98 1.9694 -0.026696 0.00017359{[40000、42000)}68 2 -0.011271 - 1.0819 e-05 34{'[42000,47000)'} 164 66 2.4848 0.20579 0.0078175 {'[47000,Inf]'} 183 56 3.2679 0.47972 0.041657 {' total '} 803 397 2.0227 NaN 0.12285
使用fitmodel拟合一个逻辑回归模型使用祸兮福所及值。fitmodel使用自动装箱过程中找到的箱子,将所有预测变量内部转换为WOE值。默认情况下,fitmodel然后用逐步方法拟合logistic回归模型。对于缺少数据的预测器,有一个明确的fitmodel,对应的WOE值
(sc, mdl) = fitmodel (sc,“显示”,“关”);
使用“点数到双倍赔率(PDO)”方法对记分卡点数进行缩放“PointsOddsAndPDO”论据formatpoints.假设你想要获得500分的概率是2(好的概率是坏的概率的两倍),概率每50分翻一倍(所以550分的概率是4)。
显示显示在拟合模型中保留的预测器按比例缩放的点数的记分卡。
sc = formatpoints (sc,“PointsOddsAndPDO”,[500 2 50]); PointsInfo=显示点(sc)
PointsInfo =38×3表预测本点 _____________ ______________ ______ {' CustAge’}{[无穷,33)的54.062}{‘CustAge}{[33岁,37)的56.282}{‘CustAge}{[37、40)的60.012}{‘CustAge}{[40岁,46)的69.636}{‘CustAge}{[46岁,48)的77.912}{‘CustAge}{[48, 51)的78.86}{‘CustAge}{[51岁,58)的80.83}{‘CustAge}{[58岁的Inf]的}96.76{‘CustAge}{< >失踪的}64.984 {'EmpStatus'} {'EmpStatus'} {'Home Owner'} 73.248 {'ResStatus'} {'Other'} 90.828 {'ResStatus'} {''} 74.125 {'EmpStatus'} {'Unknown'} 58.807 {'EmpStatus'} {'Employed'} 86.937 {'EmpStatus'} {' '}⋮
注意这个点保管和雷斯塔特斯显式显示(如64.9836和74.1250分别)。这些点是根据该地区的WOE值计算出来的
默认情况下,训练集中没有缺失数据的预测值的点数设置为南结果导致了一系列南当你跑的时候分数. 这可以通过更新名称-值对参数来更改“失踪”在formatpoints指示如何处理缺失的数据以进行评分。
记分卡已准备好为新数据集评分。您还可以使用记分卡来计算默认的概率或执行模型验证。有关详细信息,请参见分数,probdefault和validatemodel.为了进一步探索缺失数据的处理,从原始数据中选取几行作为测试数据,并引入一些缺失数据。
tdata = dataMissing(十一14,mdl.PredictorNames);%仅在模型中保留预测值%设置一些缺少的值tdata.CustAge(1) =南;tdata.ResStatus (2) =“” ;tdata.EmpStatus (3) =“” ;tdata.CustIncome(4)=NaN;disp(tdata)
CustAge ResStatus EmpStatus CustIncome TmWBank OtherCC AMBalance _______ ___________ ___________ __________ _______ _______ _________ NaN Tenant Unknown 34000 44 Yes 119.8 48Unknown 44000 14 Yes 403.62 65 Home Owner 48000 6 No 111.88 44 Other Unknown NaN 35 No 436.41
对新数据进行评分,并查看缺失数据的分数是如何以不同方式分配的保管和雷斯塔特斯以及EmpStatus和CustIncome.保管和雷斯塔特斯明确EmpStatus和CustIncome,分数函数将点设置为南.
(分数,分)=分数(sc tdata);disp(分数)
481.2231 520.8353楠楠楠
disp(分)
CustAge ResStatus EmpStatus CustIncome TmWBank OtherCC AMBalance _______ _________ _________ __________ _______ _______ _________ 64.984 62.138 58.807 67.893 61.858 75.622 89.922 78.86 74.125 58.807 82.439 61.061 75.622 89.922 96.76 73.248 NaN 96.969 51.132 50.914 89.922 69.636 90.828 58.807 NaN 61.858 50.914 89.922
使用名称-值对参数“失踪”在formatpoints选择如何为没有显式指示的预测器的缺失值分配点“明点”选择“失踪”争论,为了EmpStatus和CustIncome,记分卡中的最低点数为58.8072和29.3753,分别。也可以使用“处理”缺失数据的四种不同方法.
sc = formatpoints (sc,“失踪”,“明点”);(分数,分)=分数(sc tdata);disp(分数)
481.2231 520.8353 517.7532 451.3405
disp(分)
CustAge ResStatus EmpStatus CustIncome TmWBank OtherCC AMBalance _______ _________ _________ __________ _______ _______ _________ 64.984 62.138 58.807 67.893 61.858 75.622 89.922 78.86 74.125 58.807 82.439 61.061 75.622 89.922 96.76 73.248 58.807 96.969 51.132 50.914 89.922 69.636 90.828 58.807 29.375 61.858 50.914 89.922
处理缺失数据和开发新信用记分卡的四种方法
有四种不同的方法来处理丢失的数据。
方法1:使用fillmissing的函数creditscorecard对象
的creditscorecard对象支持金宝appfillmissing函数。当您对一个或一组预测器调用函数时fillmissing函数使用用户指定的统计信息填充缺失的数据。fillmissing金宝app支持填充值“中庸”,“中位数”,“模式”和“不变”,以及切换回原始数据的选项。
使用的优点fillmissing是,creditscorecard对象跟踪填充值,并将其应用于验证数据。这种方法的局限性在于,仅使用基本统计信息来填充缺失的数据。
有关方法1,请参阅fillmissing.
方法2:使用MATLAB填充缺失数据®fillmissing作用
MATLAB®支金宝app持fillmissing函数,可以在创建creditscorecard对象处理数值和类别数据中的缺失值。这种方法的优点是可以使用fillmissing填充缺失的数据,以及其他MATLAB功能,如standardizeMissing以及异常值处理的特点。但是,缺点是在评分之前,您需要对验证数据进行相同的转换fillmissing函数的外部creditscorecard对象
有关方法2,请参阅使用MATLAB®填充缺失处理信用记分卡工作流中的缺失数据.
方法3:使用k-最近邻(KNN)算法估算缺失数据
与方法1和方法2相比,KNN方法考虑了多个预测因子。喜欢方法2, KNN方法是在信用卡工作流程,因此,您需要对培训和验证数据进行输入。
有关方法3,请参阅利用k-最近邻算法估算信用记分卡工作流中的缺失数据.
方法4:使用随机森林算法插补缺失数据
这种随机森林方法类似于方法3并使用多个预测值来插补缺失值。因为该方法超出了creditscorecard工作流程,您需要对培训和验证数据进行输入。
有关方法4,请参阅利用随机森林算法对信用计分卡工作流中的缺失数据进行补全.
另请参阅
creditscorecard|bininfo|绘图仪|fillmissing
相关话题
您还可以从以下列表中选择网站:
