FIR滤波器的HDL串行架构
这个示例演示了如何为音频滤波应用程序的低通滤波器生成对称FIR滤波器的HDL代码,该滤波器具有完全并行、完全串行、部分串行和级联串行架构。
设计滤波器
使用44.1 kHz的音频采样率和8.0 kHz的通频带边缘频率。设置允许的峰间通带纹波为1db,阻带衰减为- 90db。然后,使用fdesign设计滤波器。使用“直接形式对称”结构的“equiripple”方法创建FIR滤波器系统对象。
Fs=44.1e3;Hz中的%采样频率成就= 8 e3;%通频带频率,单位为HzFstop = 8.8 e3;%停止频带频率,单位为Hzapas = 1;通频带纹波百分比,单位为dBAstop = 90;%阻带衰减,单位为dBfd = fdesign.lowpass (“Fp,置,美联社,Ast”,...Fpass, Fstop, pass, stop, Fs);lpFilter =设计(fd,“equiripple”,“FilterStructure”,“dfsymfir”,...“SystemObject”,真正的);
数字转换过滤器
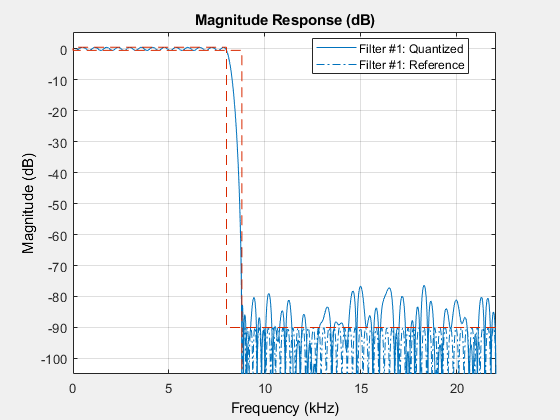
假设音频滤波器的输入来自12位ADC,输出为12位DAC。
nt_in = numerictype(1、12、11);nt_out = nt_in;lpFilter。FullPrecisionOverride = false;lpFilter。CoefficientsDataType =“自定义”;lpFilter。CustomCoefficientsDataType = numerictype(16) 1, 16日;lpFilter。OutputDataType =“自定义”;lpFilter。CustomOutputDataType = nt_out;%用fvtool检查响应。fvtool(lpFilter,“Fs”Fs,“算术”,“固定”);
从量化滤波器生成完全并行的HDL代码
从正确的量化过滤器开始,生成VHDL或Verilog代码。创建临时工作目录。在生成HDL代码之后(在本例中选择VHDL),通过单击命令行显示消息中显示的超链接,在编辑器中打开生成的VHDL文件。
这是默认情况,并生成完全并行的体系结构。在直接式FIR滤波器结构中,每个滤波器抽头都有一个专用乘法器,在对称FIR结构中,每两个对称抽头都有一个专用乘法器。这将导致大量芯片面积(在本例中为78个乘数)。您可以在各种串行架构中实现过滤器,以获得所需的速度/区域权衡。这些将在本示例的后续章节中进行说明。
workingdir = tempname;%完全并行(默认)generatehdl (lpFilter“名字”,“fullyparallel”,...“开发”,硬件描述语言(VHDL)的,...“TargetDirectory”workingdir,...“InputDataType”, nt_in);
###启动VHDL代码过滤器的生成过程of VHDL code generation process for filter: fullyparallel ### HDL latency is 2 samples
从量化滤波器生成测试台
生成一个VHDL测试平台,以确保结果与您在MATLAB®中看到的响应完全匹配。生成的VHDL代码和VHDL测试台可以用模拟器进行编译和仿真。
生成DTMF音调作为滤波器的测试刺激。DTMF信号由两个正弦波或音调组成,其频率来自两个相互排斥的组。每一对音调包含低组的一个频率(697 Hz, 770 Hz, 852 Hz, 941 Hz)和高组的一个频率(1209 Hz, 1336 Hz, 1477Hz),代表一个独特的符号。您将生成所有的DTMF信号,但使用其中一个(这里的数字1)作为测试刺激。这将使测试刺激的长度保持在合理的范围内。
符号= {' 1 ',' 2 ',“3”,“4”,'5',“6”,“7”,“8”,“9”,‘*’,' 0 ',“#”};LFG = [697 770 852 941];%低频组hfg=[1209 1336 1477];高频组%生成一个包含所有可能的高低组合的矩阵%频率,其中每一列代表一个组合。f = 0 (12);为c = 1:4为f(:,3*(c-1)+ R) = [lfg(c);hfg (r)];结束结束
接下来,让我们生成DTMF音调
FS = 8000;%采样频率8 kHzN = 800;%音调100毫秒t = (0: n - 1) / Fs;% 800样品在Fspit = 2 * pi * t;音调=零(n,尺寸(f,2));为toneChoice = 1:12%产生音调音调(:,ToneChoice)= Sum(SIN(F(:,ToneChoice)* Pit)';结束%以数字“1”的音调作为测试刺激。userstim =音调(:,1);generatehdl (lpFilter“名字”,“fullyparallel”,...“GenerateHDLTestbench”,“上”,...“TestBenchUserStimulus”userstim,...“开发”,硬件描述语言(VHDL)的,...“TargetDirectory”workingdir,...“InputDataType”, nt_in);
###启动VHDL代码过滤器的生成过程筛选器的VHDL代码生成过程:全平行主义### HDL延迟是2个样本###开始生成VHDL测试台。###生成输入刺激###完成产生输入刺激;长度800个样本。
警告:检测到溢出时自动换行。•从这个来源抑制该诊断的未来实例。——抑制
###生成测试台:/tmp/Bdoc20a_1326390_11805/tp5f3d67f1_9504_4109_b690_e669a601daae/ fullparallel_tb。vhd ###创建刺激向量…###完成VHDL测试平台的生成
关于串行架构的信息
串行架构提供了多种共享硬件资源的方法,代价是增加相对于采样率的时钟率。在FIR滤波器中,我们将在每个串行分区的输入之间共享乘数。这将使时钟速率增加一个被称为折叠因子的因子。
可以使用hdlfilterserialinfo函数根据系数的值获取关于不同过滤器长度的信息。该函数还显示了一个详尽的表格,其中列出了指定SerialPartition属性的可能选项,其中包含相应的折叠因子值和乘数。
hdlfilterserialinfo (lpFilter“InputDataType”, nt_in);
|总系数| 0 | A/Symm | Effective |---------------------------------------------156 | 0 | 78 | 78 | SerialPartition值的有效滤波器长度为78。“SerialPartition”值表,以及给定过滤器的折叠因子和乘数的相应值第三天天天天天天天天天天天天天天天天天天天天天天天1月1日,78)1、78)よ2日日2よ2日39よ; 39日日数数数数数数数数数数数数数数数数数数数数数个(1、1、1、1、39)1、1、39日数数数(1、1、1、1、39)**2日日数数数(1、1、1、1、1、1、39)数数数数数数数数数数数数数数数数10 10 10 10日日日数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数数日日日日日日日数数数数数数(1,11)*7,1]| 8 | 10 |[一(1,9)*8,6]| 9 |[9 9 9 6](1,1,7 7)*8 |||;; 10||;; 10| 10| 10| 10| 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10| 10,1,1,1,7)*11,11,11,1,1)11,1 3 3 3 3 3,1)1 124| 12 | 12,1,1,1,1,1,1,1,1 3 3 3,1,,,124124124| 12 | 12 | 12 | 12 | 12 |; 12 124;12 124,,,| 12 | 10 10 5 |[17 17 17 10]| 18 |[18 18 18 6]| | 19 | 5 |[19 19 19 2]| 20 | 4 |[20 20 18]| 21 | 4 |[21 21 21 15] | | 22 | 4 |[22 22 22 12] | | 23 | 4 |[23 23 23 9] | | 24 | 4 |[24 24 24 6] | | 25 | 4 |[25 25 25 3] | | 26 | 3 |[26 26 26] | | 27 | 3 |[27 27 24] | | 28 | 3 |[28 28 22] | | 29 | 3 |[29 29 20] | | 30 | 3 |[30 30 18] | | 31 | 3 |[31 31 16] | | 32 | 3 |[32 32 14] | | 33 | 3 |[33 33 12] | | 34 | 3 |[34 34 10] | | 35 | 3 |[35 35 8] | | 36 | 3 |[36 36 6] | | 37 | 3 |[37 37 4] | | 38 | 3 |[38 38 2] | | 39 | 2 |[39 39] | | 40 | 2 |[40 38] | | 41 | 2 |[41 37] | | 42 | 2 |[42 36] | | 43 | 2 |[43 35] | | 44 | 2 |[44 34] | | 45 | 2 |[45 33] | | 46 | 2 |[46 32] | | 47 | 2 |[47 31] | | 48 | 2 |[48 30] | | 49 | 2 |[49 29] | | 50 | 2 |[50 28] | | 51 | 2 |[51 27] | | 52 | 2 |[52 26] | | 53 | 2 |[53 25] | | 54 | 2 |[54 24] | | 55 | 2 |[55 23] | | 56 | 2 |[56 22] | | 57 | 2 |[57 21] | | 58 | 2 |[58 20] | | 59 | 2 |[59 19] | | 60 | 2 |[60 18] | | 61 | 2 |[61 17] | | 62 | 2 |[62 16] | | 63 | 2 |[63 15] | | 64 | 2 |[64 14] | | 65 | 2 |[65 13] | | 66 | 2 |[66 12] | | 67 | 2 |[67 11] | | 68 | 2 |[68 10] | | 69 | 2 |[69 9] | | 70 | 2 |[70 8] | | 71 | 2 |[71 7] | | 72 | 2 |[72 6] | | 73 | 2 |[73 5] | | 74 | 2 |[74 4] | | 75 | 2 |[75 3] | | 76 | 2 |[76 2] | | 77 | 2 |[77 1] | | 78 | 1 |[78] |
你可以使用可选属性'Multipliers'和'FoldingFactor'来显示特定的信息。
hdlfilterserialinfo (lpFilter“乘数”4....“InputDataType”, nt_in);
串行分区:[20 20 20 18],折叠因子:20,乘数:4
hdlfilterserialinfo (lpFilter“Foldingfactor”6...“InputDataType”, nt_in);
序列划分:1(1,13)*6,折叠因子:6,乘数:13
完全串行架构
在全串行架构中,不是为每个点击设置一个专用的乘数,而是连续选择每个点击的输入样本,并与相应的系数相乘。对于对称(和反对称)结构,在与相应的系数相乘之前,每组对称丝锥对应的输入样本被预先添加(对于对称)或预先减去(对于反对称)。使用寄存器对产品进行顺序累积,并在下一组输入样本到达之前将最终结果存储在寄存器中。此实现需要一个时钟速率,该时钟速率要比要计算的产品数量快许多倍。下载188bet金宝搏这减少了所需的芯片面积,因为实现只涉及一个乘法器和一些额外的逻辑元素,如多路复用器和寄存器。时钟速率将是输入采样速率(78的折叠因子)的78倍,在本例中等于3.4398 MHz。
要实现完整的串行架构,使用hdlfilterserialinfo函数,并将其“multiplier”属性设置为1。您还可以设置'SerialPartition'属性,使其值等于有效过滤器长度,在本例中是78。该函数还返回用于串行分区设置的折叠因子和乘数。
[part, foldingfact, nMults] = hdlfilterserialinfo(lpFilter,“乘数”, 1...“InputDataType”, nt_in);% #好< ASGLU >generatehdl (lpFilter“名字”,“fullyserial”,...“SerialPartition”脱离,...“开发”,硬件描述语言(VHDL)的,...“TargetDirectory”workingdir,...“InputDataType”, nt_in);
###开始过滤器的VHDL代码生成过程:fullyserial####生成:/tmp/Bdoc20a 1326390 11805/tp5f3d67f1 9504)u 4109(u b690)u e669a601daae/fullyserial.vhd###开始生成fullyserial VHDL实体#####开始生成fullyserial VHDL体系结构######时钟速率是此体系结构的78倍成功完成过滤器的VHDL代码生成过程:fullyserial####HDL延迟为3个样本
生成测试台的方法与完全并行的情况相同。为每个架构实现再次生成一个测试台是很重要的。
部分串行架构
完全平行和完全串行代表两个极端的实现。虽然完全连续是非常低的区域,但它本质上需要更快的时钟速率来操作。完全并行需要大量的芯片区域,但表现非常好。部分串行架构涵盖了这两个极端之间的所有情况。
输入丝锥分成几组。每一组由一个由乘累加和一个多路复用器组成的串行分区并行处理。在这里,一组串行分区处理给定的一组点击。这些串行分区彼此并行操作,但按顺序处理每个水龙头,以累积服务的水龙头对应的结果。最后,用加法器将每个串行分区的结果相加。
资源约束的部分串行架构
让我们假设您想要在FPGA上实现这个过滤器,该滤波器只有4个乘数可用。您可以实现滤波器使用4个串行分区,每个使用一个乘累加电路。
hdlfilterserialinfo (lpFilter“乘数”4....“InputDataType”, nt_in);
串行分区:[20 20 20 18],折叠因子:20,乘数:4
这些串行分区处理的输入抽头将是[20 20 2018]。您将使用此向量指定SerialPartition指示串行分区的分离分解。时钟速率由该矢量的最大元素确定。在这种情况下,时钟速率将是输入采样率的20倍,0.882 MHz。
[part, foldingfact, nMults] = hdlfilterserialinfo(lpFilter,“乘数”4....“InputDataType”, nt_in);generatehdl (lpFilter“名字”,“partlyserial1”,...“SerialPartition”脱离,...“开发”,硬件描述语言(VHDL)的,...“TargetDirectory”workingdir,...“InputDataType”, nt_in);
###开始过滤器的VHDL代码生成过程:partlyserial1#####生成:/tmp/Bdoc20a 1326390 11805/tp5f3d67f1 9504)u 4109(u b690)e669a601daae/partlyserial1.vhd###开始生成partlyserial1 VHDL实体#####开始生成partlyserial1 VHDL体系结构####输入时钟速率为该体系结构的20倍e、 ######成功完成过滤器的VHDL代码生成过程:partlyserial1###HDL延迟为3个样本
部分串行结构用于速度约束
假设您对滤波器实现的时钟速率有一个限制,并且最大时钟频率是2mhz。这意味着时钟速率不能超过输入采样速率的45倍。对于这样的设计约束,'SerialPartition'应该用[45 33]指定。注意,这将导致额外的串行分区硬件,这意味着额外的电路将累加33个点。你可以使用hdlfilterserialinfo和它的属性'Foldingfactor'指定SerialPartition,如下所示。
脱离= hdlfilterserialinfo (lpFilter,“Foldingfactor”45岁的...“InputDataType”, nt_in);generatehdl (lpFilter“名字”,“partlyserial2”,...“SerialPartition”脱离,...“开发”,硬件描述语言(VHDL)的,...“TargetDirectory”workingdir,...“InputDataType”, nt_in);
###启动VHDL代码过滤器的生成过程该架构的输入采样率为45倍。###成功完成过滤器的VHDL代码生成过程:PartlySerial2 ### HDL延迟是3个样本
通常,您可以根据其他约束为串行分区指定任意的点击分解。唯一的要求是向量元素的和应该等于有效滤波器的长度。
Cascade-Serial架构
串行分区中的累加器可以被重用来添加下一个串行分区的结果。这是可能的,如果一个串行分区正在处理的点击数量必须大于其旁边的串行分区至少1个。这种技术的优点是删除了添加所有串行分区结果所需的加法器集。然而,这将使时钟速率增加1,因为需要额外的时钟周期来完成额外的积累步骤。
级联-串行架构可以使用属性'ReuseAccum'指定。这可以通过两种方式实现。
添加'ReuseAccum'到generatehdl方法并指定它为'on'。注意,为'SerialPartition'属性指定的值必须是累加器重用是可行的。vector中的元素必须按降序排列,最后两个元素可以相同。
如果未指定属性'SerialPartition',且'ReuseAccum'指定为'on',则在内部确定串行分区的点击分解。这样做是为了最小化时钟速率和重用累加器。对于这个音频过滤器,它是[12 11 10 9 8 7 6 5 4 3 3]。注意,它使用了11个串行分区,意味着有11个乘法累积电路。时钟速率将是输入采样速率的13倍,573.3 kHz。
generatehdl (lpFilter“名字”,“cascadeserial1”,...“SerialPartition”33 [45],...“ReuseAccum”,“上”,...“开发”,硬件描述语言(VHDL)的,...“TargetDirectory”workingdir,...“InputDataType”, nt_in);
### /tmp/Bdoc20a_1326390_11805/tp5f3d67f1_9504_4109_b690_e669a601daae/cascadeserial1. ### /tmp/Bdoc20a_1326390_11805/tp5f3d67f1_9504_4109_b690_e669a601daae开始生成cascadeserial1 VHDL实体###开始生成cascadeserial1 VHDL体系结构###时钟速率是输入采样率的46倍。###成功完成VHDL filter代码生成过程:cascadeserial1
为实现复用累加器所需的最小时钟率,优化分解成尽可能多的串行分区。
generatehdl (lpFilter“名字”,“cascadeserial2”,...“ReuseAccum”,“上”,...“开发”,硬件描述语言(VHDL)的,...“TargetDirectory”workingdir,...“InputDataType”, nt_in);
###开始过滤器的VHDL代码生成过程:cascadeserial2#####生成:/tmp/Bdoc20a 1326390 11805/tp5f3d67f1 9504)U 4109(U b690)e669a601daae/cascadeserial2.vhd####开始生成cascadeserial2 VHDL实体#####开始生成cascadeserial2 VHDL体系结构#######时钟输入速率是此架构的13倍(3)有12个输入。35;#35;##35;######3535; 35#35#353535;###############\35; \\35; \########\#####\###7有6个输入。####串行分区#8有5个输入。###串行分区#9 has 4个输入。######串行分区#10有3个输入。####串行分区#11有3个输入。####成功完成过滤器的VHDL代码生成过程:cascadeserial2#####HDL延迟为3个样本
结论
您设计了一个低通直接形式对称FIR滤波器,以满足给定的规格。然后对设计进行量子化和检查。您为完全并行、完全串行、部分串行和级联串行体系结构生成了VHDL代码。您使用DTMF音调为其中一个体系结构生成了一个VHDL测试台。
您可以使用HDL模拟器来验证生成的不同串行体系结构的HDL代码。您可以使用合成工具来比较这些体系结构的面积和速度。您还可以试验并生成Verilog代码和测试台。
你也可以从以下列表中选择一个网站: