积累
累积矢量元素
句法
描述
B.= Accularray(印第安纳州那数据)数据根据指定的团体印第安纳州.然后在每个组上计算总和。价值印第安纳州定义数据所属的组和索引到输出数组中B.存储每个组总和的位置。
要按顺序返回组和,请指定印第安纳州作为一个向量。然后是带索引的组一世那积累返回其总和B(我).例如,如果IND = [1 1 2 2]'和数据= [1 2 3 4]', 然后B = accumarray(印第安纳州、数据)返回列向量B = [3 7]'.
要在另一种形状中返回组和,请指定印第安纳州作为矩阵。为m——- - - - - -N矩阵印第安纳州,每行代表组分配和一个N- 实证指数进入输出B..例如,如果印第安纳州包含两行表格[3 4],然后是相应元素的总和数据存储在(3,4)元素中B..
要点B.谁的索引没有出现在印第安纳州充满了0.默认。
例子
输入参数
输出参数
更多关于
累积元素
以下图示说明了行为积累在12个月内拍摄的温度数据矢量。找到每个月的最高温度读数,积累适用最大限度函数到每组值温度有相同的指数月.
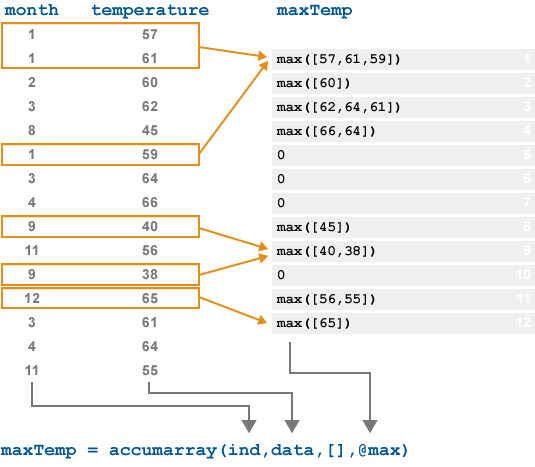
没有值月指向输出的5,6,7或10个位置。这些元素是0.默认情况下在输出中。
提示
的行为
积累类似于功能团体ummary和GroupCounts.按组计算摘要统计信息,分别计算组中的元素数。对于Matlab中的更多分组功能®, 看预处理数据.的行为
积累也类似于节目函数。节目使用箱边缘将连续值纳入1-D范围。积累使用群组数据N- 实证指数。节目只能返回箱子计数和箱子放置。积累可以将任何功能应用于数据。
你可以模仿行为
节目使用积累和数据= 1.这
疏功能也具有类似的累积行为积累.疏使用2-D指数组进行数据,而积累使用群组数据N- 实证指数。对于具有相同指标的元素,
疏适用和功能(for..双价值观)或任何功能(for..逻辑值)并返回输出矩阵中的标量导致。积累默认为和,但可以对数据应用任何函数。
扩展能力
也可以看看
您还可以从以下列表中选择一个网站:
