火车PPO代理火箭
这个例子展示了如何训练近端与离散优化(PPO)代理政策行动空间火箭在地面上。PPO代理的更多信息,请参阅近端政策优化代理。

环境
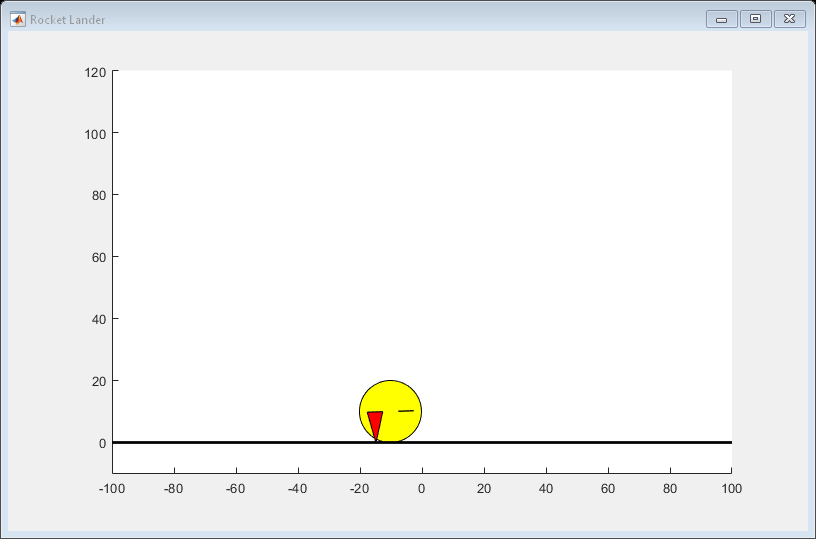
环境在这个例子中是一个三自由度火箭由圆盘与质量。火箭有两个推进器前进和旋转运动。重力垂直向下,和没有空气动力阻力的力量。培训的目标是使机器人在指定的位置落在地面上。
对于这个环境:
火箭的运动是有界的X(横轴)从-100年到100米和Y(垂直轴)从0到120米。
目标位置是(0,0)米和目标取向是0弧度。
每个推进器的最大推力为8.5 N。
样品时间是0.1秒。
来自环境的观察火箭的位置 、方向 、速度 ,角速度 ,阅读一个传感器检测粗糙着陆(1),软着陆(1)或机载(0)条件。1和1之间的观测是标准化的。
每一集的开头,火箭从一个随机的初始 位置和姿态。高度总是重置为100米。
奖励 当时提供的步骤 如下。
在这里:
, , , 的位置和速度是火箭沿着x和y轴。
是火箭的归一化距离的目标位置。
是火箭的归一化速度。
和 是最大的距离和速度。
对纵轴方向。
和 是左边和右边的行动值推进器。
是一个稀疏的奖励对水平和垂直软着陆速度小于0.5 m / s。
创造MATLAB环境
创建一个为火箭飞行器使用MATLAB环境RocketLander类。
env = RocketLander;
从环境中获得观察和操作规范。
actionInfo = getActionInfo (env);observationInfo = getObservationInfo (env);numObs = observationInfo.Dimension (1);numAct =元素个数(actionInfo.Elements);
对环境样品时间
t = 0.1;
解决随机发生器再现性的种子。
rng (0)
创建PPO代理
PPO代理在这个例子中作用于一个离散的行动空间。在每一个时间步,代理选择之一,以下对离散行动。
在这里, 和 归一化每个推进器推力值。
估计策略和价值功能,代理维护功能接近者为演员和评论家,使用深层神经网络建模。培训可以敏感的初始网络权重和偏见,和结果可以随不同的值。随机初始化网络权值小的值在这个例子。
创建评论家深层神经网络有六个输入和一个输出。评论家网络的输出输入观测贴现的长期回报。
criticLayerSizes = (400 - 300);actorLayerSizes = (400 - 300);criticNetwork = [featureInputLayer numObs,“归一化”,“没有”,“名字”,“观察”)fullyConnectedLayer (criticLayerSizes (1),“名字”,“CriticFC1”,…“重量”,√2 / numObs) *(兰德(criticLayerSizes (1) numObs) -0.5),…“偏见”1 e - 3 * 1 (criticLayerSizes (1), 1)) reluLayer (“名字”,“CriticRelu1”)fullyConnectedLayer (criticLayerSizes (2),“名字”,“CriticFC2”,…“重量”,√2 / criticLayerSizes(1)) *(兰德(criticLayerSizes (2), criticLayerSizes (1)) -0.5),…“偏见”1 e - 3 * 1 (criticLayerSizes (2), 1)) reluLayer (“名字”,“CriticRelu2”)fullyConnectedLayer (1,“名字”,“CriticOutput”,…“重量”,√2 / criticLayerSizes(2)) *(兰德(1,criticLayerSizes (2)) -0.5),…“偏见”1 e - 3)];criticNetwork = dlnetwork (criticNetwork);
创造了评论家的价值功能。
criticOpts = rlOptimizerOptions (“LearnRate”1的军医);评论家= rlValueFunction (criticNetwork observationInfo);
使用深神经网络创建演员有六个输入和两个输出。演员的输出网络的概率对每个可能的行动。每一对行动包含每个推进器规范化动作值。环境一步这些值函数尺度来确定实际推力值。
actorNetwork = [featureInputLayer numObs,“归一化”,“没有”,“名字”,“观察”)fullyConnectedLayer (actorLayerSizes (1),“名字”,“ActorFC1”,…“重量”,√2 / numObs) *(兰德(actorLayerSizes (1) numObs) -0.5),…“偏见”1 e - 3 * 1 (actorLayerSizes (1), 1)) reluLayer (“名字”,“ActorRelu1”)fullyConnectedLayer (actorLayerSizes (2),“名字”,“ActorFC2”,…“重量”,√2 / actorLayerSizes(1)) *(兰德(actorLayerSizes (2), actorLayerSizes (1)) -0.5),…“偏见”1 e - 3 * 1 (actorLayerSizes (2), 1)) reluLayer (“名字”,“ActorRelu2”)fullyConnectedLayer (numAct“名字”,“行动”,…“重量”,√2 / actorLayerSizes(2)) *(兰德(numAct, actorLayerSizes (2)) -0.5),…“偏见”1 e - 3 * 1 (numAct 1)) softmaxLayer (“名字”,“actionProb”));actorNetwork = dlnetwork (actorNetwork);
使用离散分类创建演员的演员。
actorOpts = rlOptimizerOptions (“LearnRate”1的军医);演员= rlDiscreteCategoricalActor (actorNetwork observationInfo actionInfo);
指定代理hyperparameters使用rlPPOAgentOptions对象。
agentOpts = rlPPOAgentOptions (…“ExperienceHorizon”,600,…“ClipFactor”,0.02,…“EntropyLossWeight”,0.01,…“ActorOptimizerOptions”actorOpts,…“CriticOptimizerOptions”criticOpts,…“NumEpoch”3,…“AdvantageEstimateMethod”,gae的,…“GAEFactor”,0.95,…“SampleTime”Ts,…“DiscountFactor”,0.997);
对于这些hyperparameters:
代理收集经验,直到达到600年的经验地平线步骤或事件128年终止,然后从mini-batches火车3时代的经历。
改善训练稳定,使用一个目标函数剪辑0.02倍。
折现系数值0.997鼓励长期回报。
评论家输出方差减少通过使用广义优势估计方法GAE因子为0.95。
的
EntropyLossWeight0.01提高勘探在训练。
创建PPO代理。
代理= rlPPOAgent(演员、评论家、agentOpts);
火车代理
火车PPO代理、指定以下培训选项。
运行培训最多20000集,每集持续最多600的时间步骤。
连续停止训练时的平均回报超过100集是430或者更多。
保存一份代理每集的插曲的奖励是700或更多。
trainOpts = rlTrainingOptions (…“MaxEpisodes”,20000,…“MaxStepsPerEpisode”,600,…“阴谋”,“训练进步”,…“StopTrainingCriteria”,“AverageReward”,…“StopTrainingValue”,430,…“ScoreAveragingWindowLength”,100,…“SaveAgentCriteria”,“EpisodeReward”,…“SaveAgentValue”,700);
火车代理使用火车函数。由于环境的复杂性,培训过程是计算密集型和需要几个小时才能完成。节省时间在运行这个例子中,加载一个pretrained代理设置doTraining来假。
doTraining = false;如果doTraining trainingStats =火车(代理,env, trainOpts);其他的负载(“rocketLanderAgent.mat”);结束
训练一个示例如下所示。实际结果可能会有所不同,因为随机性的培训过程。

模拟
火箭飞行器环境可视化仿真的阴谋。
情节(env)
模拟环境内的训练有素的特工。代理模拟更多的信息,请参阅rlSimulationOptions和sim卡。
simOptions = rlSimulationOptions (“MaxSteps”,600);simOptions。NumSimulations = 5;% 5次模拟环境经验= sim (env,代理,simOptions);