火车TD3代理永磁同步电动机的控制
这个例子演示了永磁同步电动机的速度控制永磁同步电动机使用双延迟深决定性策略梯度(TD3)代理。
这个例子的目的是表明你可以用强化学习代替线性控制器,如PID控制器,在永磁同步电动机系统的速度控制。外地区的线性、线性控制器通常不产生良好的跟踪性能。在这种情况下,强化学习提供了一个非线性控制的选择。
对于这个示例加载参数。
sim_data
模型:‘maxon - 645106 sn:“2295588”p: 7 Rs: 0.2930 Ld: 8.7678 e-05 Lq: 7.7724 e-05客:5.7835 J: 8.3500 e-05 B: 7.0095 e-05 I_rated: 7.2600 QEPSlits: 4096 N_base: 3477 N_max: 4300 FluxPM: 0.0046 T_rated: 0.3472 PositionOffset: 0.1650模型:‘BoostXL-DRV8305 sn:“INV_XXXX”V_dc: 24 I_trip: 10 Rds_on: 0.0020 Rshunt: 0.0070 CtSensAOffset: 2295 CtSensBOffset: 2286 ADCGain: 1 EnableLogic: 1 invertingAmp: 1 ISenseVref: 3.3000 ISenseVoltPerAmp: 0.0700 ISenseMax: 21.4286 R_board: 0.0043模型:‘LAUNCHXL-F28379D sn:“123456”CPU_frequency: 200000000 PWM_frequency: 5000 PWM_Counter_Period: 20000 ADC_Vref: 3 ADC_MaxCount: 4095 SCI_baud_rate: 12000000 V_base: 13.8564 I_base: 21.4286 N_base: 3477 T_base: 1.0249 P_base: 445.3845
打开仿真软件模型。金宝app
mdl =“mcb_pmsm_foc_sim_RL”;open_system (mdl)
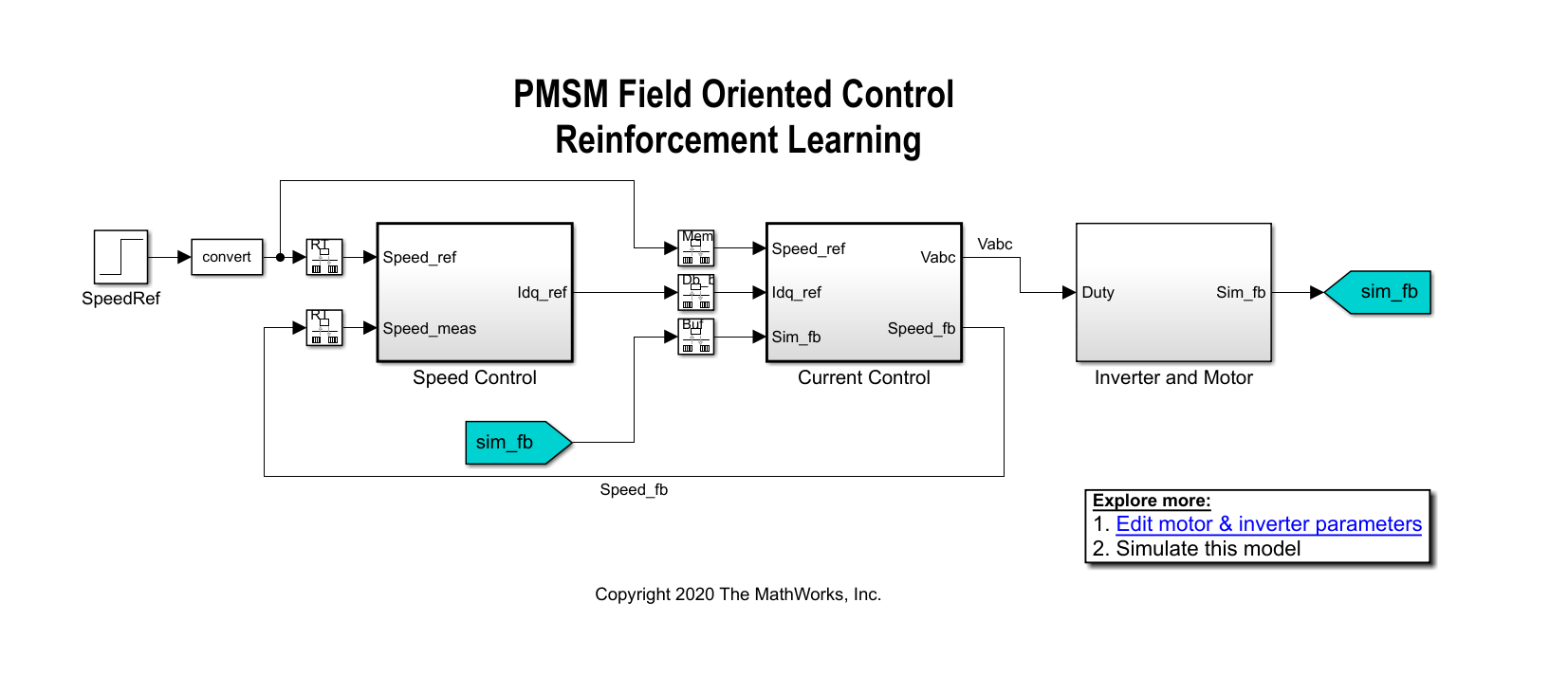
在一个线性控制版本的这个例子中,您可以使用PI控制器的速度和电流控制回路。一个和PI控制器可以控制速度,两个内循环PI控制器控制d-axis q-axis电流。总体目标是追踪的参考速度Speed_Ref信号。这个示例使用强化学习代理控制内部控制回路中的电流而PI控制器控制外循环。
创建环境接口
环境在这个例子中包括永磁同步电动机系统,不包括内循环电流控制器,即强化学习代理。将强化学习之间的界面剂和环境、开闭环控制子系统。
open_system (“mcb_pmsm_foc_sim_RL /电流控制/ Control_System /闭环控制”)

强化学习子系统包含一个RL代理块、观测向量的创建和奖励计算。
对于这个环境:
观测和参考速度
Speed_ref、速度反馈Speed_fb,d-axis q-axis水流和错误( , , 和 ),误差积分。代理人的行为是电压
vd_rl和vq_rl。代理的样品时间是2秒的军医。内循环控制发生在不同样本的时间比外循环控制。
5000年的模拟运行时间步骤,除非它时提前终止 信号在1饱和。
在每个时间步是奖励:
在这里, , 是常数, 是d-axis当前错误, 是q-axis当前错误, 从上一次的操作步骤,然后呢 是一个标志,等于1仿真时提前终止。
对环境创建的观察和操作规范。创造持续的规范信息,请参阅rlNumericSpec。
%创建观测规范。numObservations = 8;observationInfo = rlNumericSpec ([numObservations 1]);observationInfo。Name =“观察”;observationInfo。描述=错误的信息和参考信号;%创建动作规范。numActions = 2;actionInfo = rlNumericSpec ([numActions 1]);actionInfo。Name =“vqdRef”;
创建接口使用仿真软件环金宝app境的观察和操作规范。创造仿真软件环境的更多信息,请参阅金宝apprl金宝appSimulinkEnv。
agentblk =“mcb_pmsm_foc_sim_RL /电流控制/ Control_System /闭环控制/强化学习/ RL代理”;env = rl金宝appSimulinkEnv (mdl agentblk、observationInfo actionInfo);
提供一个重置功能环境使用ResetFcn参数。在每一个训练集的开始,resetPMSM随机初始化函数的参考速度的最终值SpeedRef块695.4 rpm (0.2 pu), 1390.8转0.4 (pu), 2086.2 rpm (0.6 pu),或2781.6 rpm (0.8 pu)。
env。ResetFcn = @resetPMSM;
创建代理
在这个例子中使用的代理是twin-delayed深决定性策略梯度(TD3)代理。TD3代理接近长期奖励的观察和操作使用两种批评。TD3代理的更多信息,请参阅Twin-Delayed深决定性策略梯度代理。
创建批评,首先创建一个深层神经网络和两个输入(观察和行动)和一个输出。创建一个值函数表示的更多信息,参见创建政策和价值函数表示。
rng (0)%解决随机种子statePath = [featureInputLayer numObservations,“归一化”,“没有”,“名字”,“状态”)fullyConnectedLayer (64,“名字”,“fc1”));actionPath = [featureInputLayer numActions,“归一化”,“没有”,“名字”,“行动”)fullyConnectedLayer (64,“名字”,“取得”));commonPath = [additionLayer (2,“名字”,“添加”)reluLayer (“名字”,“relu2”)fullyConnectedLayer (32,“名字”,“一个fc3”文件)reluLayer (“名字”,“relu3”)fullyConnectedLayer (16“名字”,“fc4”)fullyConnectedLayer (1,“名字”,“CriticOutput”));criticNetwork = layerGraph ();criticNetwork = addLayers (criticNetwork statePath);criticNetwork = addLayers (criticNetwork actionPath);criticNetwork = addLayers (criticNetwork commonPath);criticNetwork = connectLayers (criticNetwork,“fc1”,“添加/三机一体”);criticNetwork = connectLayers (criticNetwork,“取得”,“添加/ in2”);
创建一个使用指定的评论家表示神经网络和选项。您还必须指定的行动和观测规范评论家。有关更多信息,请参见rlQValueRepresentation。
criticOptions = rlRepresentationOptions (“LearnRate”1的军医,“GradientThreshold”1);摘要= rlQValueRepresentation (criticNetwork observationInfo actionInfo,…“观察”,{“状态”},“行动”,{“行动”},criticOptions);critic2 = rlQValueRepresentation (criticNetwork observationInfo actionInfo,…“观察”,{“状态”},“行动”,{“行动”},criticOptions);
TD3代理决定行动采取考虑到观测使用演员表示。创建演员,首先创建一个深层神经网络,构建评论家演员以类似的方式。有关更多信息,请参见rlDeterministicActorRepresentation。
actorNetwork = [featureInputLayer numObservations,“归一化”,“没有”,“名字”,“状态”)fullyConnectedLayer (64,“名字”,“actorFC1”)reluLayer (“名字”,“relu1”)fullyConnectedLayer (32,“名字”,“actorFC2”)reluLayer (“名字”,“relu2”)fullyConnectedLayer (numActions“名字”,“行动”)tanhLayer (“名字”,“tanh1”));actorOptions = rlRepresentationOptions (“LearnRate”1 e - 3,“GradientThreshold”,1“L2RegularizationFactor”,0.001);演员= rlDeterministicActorRepresentation (actorNetwork observationInfo actionInfo,…“观察”,{“状态”},“行动”,{“tanh1”},actorOptions);
创建TD3代理,首先使用一个指定代理选项rlTD3AgentOptions对象。代理列车从一种体验缓冲区的最大容量512随机选择mini-batches e6的大小。使用折现系数0.995支持长期的回报。TD3代理维护时滞和评论家称为副本的演员目标的演员和评论家。配置目标更新每10剂步骤期间培训平滑系数为0.005。
Ts_agent = t;agentOptions = rlTD3AgentOptions (“SampleTime”Ts_agent,…“DiscountFactor”,0.995,…“ExperienceBufferLength”2 e6,…“MiniBatchSize”,512,…“NumStepsToLookAhead”,1…“TargetSmoothFactor”,0.005,…“TargetUpdateFrequency”10);
在培训过程中,代理探索行动空间使用高斯行动噪声模型。噪声方差和衰变率使用ExplorationModel财产。噪声方差衰减的速度2的军医,有利于勘探对培训和开发后期的开始。关于噪声模型的更多信息,请参阅rlTD3AgentOptions。
agentOptions.ExplorationModel。方差= 0.05;agentOptions.ExplorationModel。VarianceDecayRate = 2的军医;agentOptions.ExplorationModel。VarianceMin = 0.001;
代理还使用高斯行动噪声模型平滑的目标政策更新。指定使用方差和衰变速率模型TargetPolicySmoothModel财产。
agentOptions.TargetPolicySmoothModel。方差= 0.1;agentOptions.TargetPolicySmoothModel。VarianceDecayRate = 1的军医;
创建代理使用指定的演员、评论家和选项。
代理= rlTD3Agent(演员,[摘要,critic2], agentOptions);
火车代理
培训代理商,首先使用指定培训选项rlTrainingOptions。对于这个示例,使用以下选项。
运行每个培训最多1000集,每集持久的最多
装天花板(T / Ts_agent)时间的步骤。停止训练当代理接收到平均累积奖励大于-190连续超过100集。在这一点上,代理可以跟踪参考速度。
T = 1.0;maxepisodes = 1000;maxsteps =装天花板(T / Ts_agent);trainingOpts = rlTrainingOptions (…“MaxEpisodes”maxepisodes,…“MaxStepsPerEpisode”maxsteps,…“StopTrainingCriteria”,“AverageReward”,…“StopTrainingValue”,-190,…“ScoreAveragingWindowLength”,100);
火车代理使用火车函数。培训这个代理是一个计算密集型的过程需要几分钟才能完成。节省时间在运行这个例子中,加载一个pretrained代理设置doTraining来假。训练自己代理,集doTraining来真正的。
doTraining = false;如果doTraining trainingStats =火车(代理,env, trainingOpts);其他的负载(“rlPMSMAgent.mat”)结束
培训的快照进步是如下图所示。你可以期待不同的结果由于随机性的培训过程。



模拟剂
验证培训代理的性能,模拟模型和视图的闭环性能通过速度跟踪范围块。
sim (mdl);
你也可以模拟在不同的参考速度模型。设置的参考速度SpeedRef块一个不同的值在0.2和1.0之间单位和模拟模型。
set_param (“mcb_pmsm_foc_sim_RL / SpeedRef”,“后”,“0.6”)sim (mdl);
下面的图显示了一个示例的闭环跟踪性能。在这个仿真,参考速度的步骤通过值695.4 rpm(0.2单位)和1738.5 rpm (0.5 pu)。π和强化学习控制器跟踪参考信号的变化在0.5秒。
虽然代理培训追踪的参考速度0.2单位,而不是0.5单位,它能够概括。

下面的图显示了相应的电流跟踪性能。代理能够跟踪 和 当前的引用与稳态误差小于2%。

