rlQValueRepresentation
强化学习主体的q值函数批判表示
描述
该对象实现了一个q值函数近似器,用于强化学习代理内的批评。q值函数是一个函数,它将观察-动作对映射到一个标量值,该标量值表示agent从给定的观察开始并执行给定的动作时所期望积累的总长期回报。因此,q值函数评论家需要观察和行动作为输入。在创建rlQValueRepresentation批评家,用它来创建一个依赖于q值函数批评家的代理,例如rlQAgent,rlDQNAgent,rlSARSAAgent,rlDDPGAgent,或rlTD3Agent.有关创建表示的更多信息,请参见创建策略和价值功能表示.
创建
语法
描述
标量输出Q值批评家
评论家= rlQValueRepresentation (净,observationInfo,actionInfo“观察”,obsName“行动”,actName)评论家.净是作为近似器使用的深度神经网络,并且必须既有观测值和动作作为输入,又有单个标量输出。该语法设置观测信息和ActionInfo特性评论家分别对应于输入observationInfo和actionInfo,包括观察和行动规范。obsName的输入层的名称净与观察规范相关的。动作名称actName必须是输入层的名称净与操作规范相关联的。
评论家= rlQValueRepresentation (标签,observationInfo,actionInfo)评论家与离散的行动和观察空间从q值表标签.标签是一个rlTable对象,该对象包含一个表,其中包含尽可能多的行和尽可能多的列和可能的操作。该语法设置观测信息和ActionInfo特性评论家分别对应于输入observationInfo和actionInfo,这一定是rlFiniteSetSpec分别包含离散观察和行动空间的规范的对象。
评论家= rlQValueRepresentation ({basisFcn,W0},observationInfo,actionInfo)评论家使用自定义基函数作为底层逼近器。第一个输入参数是一个包含两个元素的单元格,其中第一个元素包含句柄basisFcn到自定义基函数,第二个元素包含初始权值向量W0.在这里,基本函数必须既有观测值又有作为输入的动作W0必须是一个列向量。该语法设置观测信息和ActionInfo特性评论家分别对应于输入observationInfo和actionInfo.
多输出离散动作空间q值批评家
评论家= rlQValueRepresentation (净,observationInfo,actionInfo“观察”,obsName)评论家对于离散的动作空间.净是作为近似器使用的深度神经网络,必须只有观测值作为输入,而单个输出层具有尽可能多的可能离散动作的元素数量。该语法设置观测信息和ActionInfo特性评论家分别对应于输入observationInfo和actionInfo,包括观察和行动规范。在这里,actionInfo必须是一个rlFiniteSetSpec对象,该对象包含离散动作空间的规范。观察的名字obsName必须是的输入层的名称净.
评论家= rlQValueRepresentation ({basisFcn,W0},observationInfo,actionInfo)评论家对于离散的动作空间使用自定义基函数作为底层逼近器。第一个输入参数是一个包含两个元素的单元格,其中第一个元素包含句柄basisFcn为自定义基函数,第二个元素包含初始权矩阵W0在此,基函数必须仅将观测值作为输入,并且W0必须有尽可能多的列可能的行动的数量。该语法设置观测信息和ActionInfo特性评论家分别对应于输入observationInfo和actionInfo.
选项
评论家= rlQValueRepresentation (___,选项)评论家使用附加选项集选项,这是一个rlRepresentationOptions对象。该语法设置选项的属性评论家到选项输入参数。您可以将此语法与前面的任何输入参数组合一起使用。
输入参数
属性
对象的功能
rlDDPGAgent |
深度确定性策略梯度强化学习主体 |
rlTD3Agent |
双延迟深层确定性策略梯度强化学习agent |
rlDQNAgent |
深度q -网络强化学习代理 |
rlQAgent |
Q-learning强化学习代理 |
rlSARSAAgent |
SARSA强化学习代理 |
rlSACAgent |
软演员-评论家强化学习代理 |
getValue |
获得估计值函数表示 |
getMaxQValue |
得到了离散作用空间下q值函数表示的最大状态值函数估计 |
例子
利用深度神经网络创建q值函数批评家
创建观察规范对象(或者使用getObservationInfo从环境中提取规范对象)。对于本例,将观测空间定义为连续的四维空间,这样一个观测就是包含四个双精度的列向量。
obsInfo = rlNumericSpec([4 1]);
创建操作规范对象(或者使用getActionInfo从环境中提取规范对象)。对于本例,将操作空间定义为连续的二维空间,因此单个操作是包含两个double的列向量。
actInfo = rlNumericSpec([2 1]);
建立一个深度神经网络来近似q值函数。网络必须有两个输入,一个用于观察,一个用于动作。观察输入(这里称为myobs)必须接受一个四元向量(由obsInfo).操作输入(此处称为myact)必须接受一个双元素向量(由actInfo).网络的输出必须是一个标量,表示agent从给定的观测开始并采取给定的行动时的预期累积长期回报。
观测路径层数百分比obsPath = [featureInputLayer (4“归一化”,“没有”,“名字”,“myobs”) fullyConnectedLayer (1,“名字”,“obsout”)];%动作路径层actPath = [featureInputLayer (2,“归一化”,“没有”,“名字”,“我的行为”) fullyConnectedLayer (1,“名字”,“actout”)];%输出层的公共路径comPath = [additionLayer (2,“名字”,“添加”) fullyConnectedLayer (1,“名字”,“输出”)];给网络对象添加层网= addLayers (layerGraph (obsPath) actPath);网= addLayers(净,comPath);%连接层网= connectLayers(网络,“obsout”,“添加/三机一体”);网= connectLayers(网络,“actout”,“添加/ in2”);%的阴谋网络情节(净)
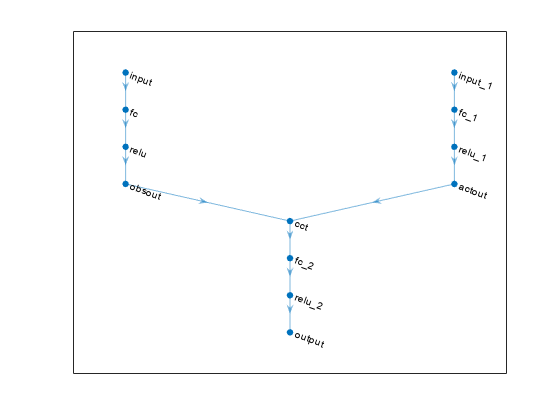
创造批评家rlQValueRepresentation,使用网络,观察和动作规范对象,以及网络输入层的名称。
评论家= rlQValueRepresentation(净、obsInfo actInfo,…“观察”,{“myobs”},“行动”,{“我的行为”})
批评家= rlQValueRepresentation与属性:ActionInfo: [1x1 rl.util.]。rlNumericSpec . ObservationInfo: [1x1 rl.util.]rlNumericSpec] Options: [1x1 rl.option.rlRepresentationOptions]
要检查你的批评家,使用getValue函数使用当前网络权重返回随机观察和操作的值。
v = getValue(评论家,{兰德(4,1)},{兰德(2,1)})
v =单0.1102
您现在可以使用批评家(以及一个参与者)来创建依赖于q值函数批评家的代理(例如rlQAgent,rlDQNAgent,rlSARSAAgent,或rlDDPGAgent代理)。
基于深度神经网络的多输出q值函数评价
这个例子展示了如何使用深度神经网络近似器为离散动作空间创建一个多输出q值函数批评家。
这个批评家只将观察结果作为输入,并生成带有尽可能多的操作元素的向量作为输出。当代理从给定的观察开始并采取与输出向量中元素位置相对应的操作时,每个元素表示预期的累积长期奖励。
创建观察规范对象(或者使用getObservationInfo从环境中提取规范对象)。对于本例,将观测空间定义为连续的四维空间,这样一个观测就是包含四个双精度的列向量。
obsInfo = rlNumericSpec([4 1]);
创建一个有限设定的动作规格对象(或可选使用)getActionInfo从具有离散操作空间的环境中提取规范对象)。对于本例,将操作空间定义为一个有限集,包含三个可能的值(命名为7,5,3.在这种情况下)。
actInfo=rlFiniteSetSpec([7 5 3]);
创建一个深度神经网络近似器来近似批评家内部的q值函数。网络的输入(这里称为myobs)必须接受四个元素的向量,如obsInfo.输出必须是具有尽可能多的可能的离散操作的元素的单个输出层(在本例中为三个,定义为actInfo).
网= [featureInputLayer (4“归一化”,“没有”,“名字”,“myobs”) fullyConnectedLayer (3“名字”,“价值”)];
使用网络、观察规范对象和网络输入层的名称创建批评家。
评论家= rlQValueRepresentation(净、obsInfo actInfo,“观察”,{“myobs”})
critic=rlQValueRepresentation with properties:ActionInfo:[1x1 rl.util.rlFiniteSetSpec]ObservationInfo:[1x1 rl.util.rlNumericSpec]选项:[1x1 rl.option.rlRepresentationOptions]
要检查你的批评家,使用getValue函数返回使用当前网络权重的随机观测值。这三种可能的操作都有一个值。
v = getValue(评论家,{兰德(4,1)})
v =3x1单列向量0.7232 0.8177 -0.2212
现在,您可以使用评论家(以及演员)来创建一个依赖于q值函数评论家(例如rlQAgent,rlDQNAgent,或rlSARSAAgent代理)。
从表中创建q值功能评价
创建一个有限集观察规范对象(或者使用getObservationInfo从具有离散观测空间的环境中提取规范对象)。对于本例,将观测空间定义为具有4个可能值的有限集。
obsInfo=rlFiniteSetSpec([7 5 3 1]);
创建一个有限设定的动作规格对象(或可选使用)getActionInfo从具有离散操作空间的环境中提取规范对象)。在这个例子中,将动作空间定义为具有2个可能值的有限集。
actInfo=rlFiniteSetSpec([4 8]);
创建一个表来近似批评家中的值函数。rlTable从观察和操作规范对象创建值表对象。
qTable = rlTable (obsInfo actInfo);
该表为每个可能的观察-操作对存储一个值(表示预期的累积长期奖励)。每一行对应一个观察,每一列对应一个操作。可以使用桌子财产虚表对象。每个元素的初始值都是零。
qTable.表格
ans =4×20 0 0 0 0 0 0
您可以将该表初始化为任何值,在本例中为包含1通过8.
qTable.Table =重塑(1:8 4 2)
qTable = rlTable with properties: Table: [4x2 double]
使用该表以及观察和行动规范对象创建批评家。
批评家=rlQValueRepresentation(qTable、obsInfo、actInfo)
批评家= rlQValueRepresentation与属性:ActionInfo: [1x1 rl.util.]。rlFiniteSetSpec: [1x1 rl.util.]rlFiniteSetSpec] Options: [1x1 rl.option.rlRepresentationOptions]
要检查你的批评家,使用getValue函数使用当前表项返回给定观察和操作的值。
v = getValue(评论家,{5},{8})
v = 6
现在,您可以使用评论家(以及一个演员)来创建一个依赖于q值函数评论家(例如rlQAgent,rlDQNAgent,或rlSARSAAgent代理)。
从定制基础功能中创建Q-Value功能批评家
创建观察规范对象(或者使用getObservationInfo从环境中提取规范对象)。在本例中,将观测空间定义为连续的四维空间,使单个观测是包含3个双精度的列向量。
obsInfo = rlNumericSpec([3 1]);
创建操作规范对象(或者使用getActionInfo从环境中提取规范对象)。对于本例,将动作空间定义为连续的二维空间,以便单个动作是包含2个双精度的列向量。
actInfo = rlNumericSpec([2 1]);
创建一个自定义的基础函数来近似批评家的价值函数。自定义基函数必须返回一个列向量。每个向量元素必须是分别定义的观察和动作的函数obsInfo和actInfo.
myobs = @(myobs,myact) [myobs(2)^2;myobs (1) + exp (myact (1));abs (myact (2));myobs (3))
myBasisFcn =function_handle与价值:@ (myobs myact) [myobs (2) ^ 2; myobs (1) + exp (myact (1)); abs (myact (2)); myobs (3))
批评家的输出是标量W * myBasisFcn (myobs myact),在那里W是一个权重列向量,它必须具有与自定义基函数输出相同的大小。该输出是代理从给定的观察开始并采取最佳行动时的预期累积长期回报。W的元素是可学习的参数。
定义初始参数向量。
W0 = (1, 4, 4; 2);
创建批评家。第一个参数是包含自定义函数句柄和初始权重向量的两元素单元格。第二个和第三个参数分别是观察和操作规范对象。
评论家= rlQValueRepresentation ({myBasisFcn, W0}, obsInfo actInfo)
批评家= rlQValueRepresentation with properties:ObservationInfo: [1×1 rl.util.]rlNumericSpec] Options: [1×1 rl.option.rlRepresentationOptions]
要检查你的批评家,使用getValue函数使用当前参数向量返回给定观察-操作对的值。
v = getValue(批评家,{[1 2 3]'},{[4 5]'})
V = 1×1美元252.3926
您现在可以使用批评家(以及一个参与者)来创建依赖于q值函数批评家的代理(例如rlQAgent,rlDQNAgent,rlSARSAAgent,或rlDDPGAgent代理)。
创建多输出q值功能评价自定义基础功能
这个例子展示了如何使用自定义基函数近似器为离散动作空间创建一个多输出q值函数批评家。
这个批评家只将观察结果作为输入,并生成带有尽可能多的操作元素的向量作为输出。当代理从给定的观察开始并采取与输出向量中元素位置相对应的操作时,每个元素表示预期的累积长期奖励。
创建观察规范对象(或者使用getObservationInfo从环境中提取规范对象)。在本例中,将观测空间定义为连续的四维空间,因此单个观测是包含2个双精度的列向量。
obsInfo=rlNumericSpec([2 1]);
创建一个有限设定的动作规格对象(或可选使用)getActionInfo从具有离散操作空间的环境中提取规范对象)。对于本例,将操作空间定义为一个有限集,包含3个可能的值(命名为7,5,3.在这种情况下)。
actInfo=rlFiniteSetSpec([7 5 3]);
创建一个自定义的基础函数来近似批评家的价值函数。自定义基函数必须返回一个列向量。每个向量元素必须是观测值的函数obsInfo.
myobs = @(myobs) [myobs(2)^2;myobs (1);exp (myobs (2));abs (myobs (1)))
myBasisFcn =function_handle与价值:@ (myobs) [myobs (2) ^ 2; myobs (1); exp (myobs (2)); abs (myobs (1)))
批评家的输出是向量c= W ' * myBasisFcn (myobs),在那里W是一个权值矩阵,它必须具有与基函数输出长度相同的行数,与可能的操作数量相同的列数。
c中的每一个元素都是agent从给定的观察开始并采取与所考虑元素位置相对应的动作时所期望的累积长期报酬。W的元素是可学习的参数。
定义初始参数矩阵。
W0 =兰德(4,3);
创建批评家。第一个参数是包含自定义函数句柄和初始参数矩阵的两元素单元格。第二个和第三个参数分别是观察和操作规范对象。
评论家= rlQValueRepresentation ({myBasisFcn, W0}, obsInfo actInfo)
critic=rlQValueRepresentation with properties:ActionInfo:[1x1 rl.util.rlFiniteSetSpec]ObservationInfo:[1x1 rl.util.rlNumericSpec]选项:[1x1 rl.option.rlRepresentationOptions]
要检查你的批评家,使用getValue函数使用当前参数矩阵返回随机观测值。请注意,三种可能的操作各有一个值。
v = getValue(评论家,{兰德(2,1)})
V = 3x1 dlarray 2.1395 1.2183 2.3342
现在,您可以使用评论家(以及演员)来创建一个依赖于q值函数评论家(例如rlQAgent,rlDQNAgent,或rlSARSAAgent代理)。
利用递归神经网络建立q值函数评判
创造一个环境,并获得观察和行动信息。
env = rlPredefinedEnv (“CartPole-Discrete”);obsInfo = getObservationInfo (env);actInfo = getActionInfo (env);numObs = obsInfo.Dimension (1);numDiscreteAct =元素个数(actInfo.Elements);
为你的批评者创建一个循环的深层神经网络。要创建递归神经网络,请使用sequenceInputLayer作为输入层,并至少包括一个lstmLayer.
创建用于多输出q值函数表示的递归神经网络。
临界网络=[sequenceInputLayer(numObs,“归一化”,“没有”,“名字”,“状态”) fullyConnectedLayer (50,“名字”,“CriticStateFC1”) reluLayer (“名字”,“CriticRelu1”) lstmLayer (20“OutputMode”,“序列”,“名字”,“CriticLSTM”);fullyConnectedLayer (20,“名字”,“CriticStateFC2”) reluLayer (“名字”,“CriticRelu2”) fullyConnectedLayer (numDiscreteAct“名字”,“输出”)];
使用递归神经网络为您的批评者创建一个表示。
criticOptions = rlRepresentationOptions (“LearnRate”1 e - 3,“GradientThreshold”1);评论家= rlQValueRepresentation (criticNetwork obsInfo actInfo,…“观察”,“状态”, criticOptions);
你也可以从以下列表中选择一个网站:
