sbiompgsa
执行多参数全局灵敏度分析(需要统计和机器学习工具箱)
句法
描述
mpgsaresults.= sbiompgsa (Modelobj.那样本那分类器)样本执行多次全局敏感性分析分类器。
mpgsaresults.= sbiompgsa (simdata那样本那分类器)simdata执行多次全局敏感性分析分类器。
mpgsaresults.= sbiompgsa (___那名称,值)
例子
执行多次全局敏感性分析(MPGSA)
sbioloadproject.tmdd_with_to.sbproj.
获取活动的configset并设置目标占用率(至)作为回应。
cs = getConfigset(M1);cs.runtimeOptions.statestolog =.'至';
模拟模型并绘制至轮廓。
Sbioplot(Sbiosmulate(M1,CS));
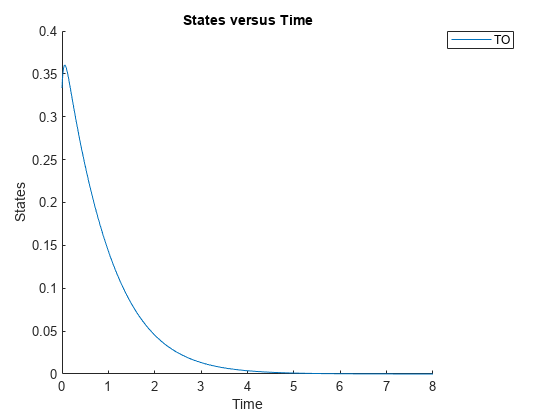
定义目标占用率的曝光(曲线曲线下的区域)。
分类器='trapz(时间,to)<= 0.1';
执行MPGSA以确定相对于to的敏感参数。在预定义边界之间改变参数值以生成10,000个参数样本。
%抑制模拟期间发出的信息警告。Warnsettings =警告('离开'那'Simbiology:SBServices:sb_dimanalysisnnotdone_matlabfcn_ucon');RNG(0,'twister');重复性的%params = {'kel'那“ksyn”那'kdeg'那“公里”};界= [0.1,1;0.1, 1;0.1, 1;0.1, 1);mpgsaResults = sbiompgsa (m1,参数,分类器,'界限',界限,'Operenceamples',10000)
mpgsaResults = MPGSA with properties: Classifiers: {'trapz(time,TO) <= 0.1'} KolmogorovSmirnovStatistics: [4x1 table] ECDFData: {4x4 cell} SignificanceLevel: 0.0500 PValues: [4x1 table] 金宝appsupportthypoture: [10000x1 table] Observables: {'TO'} ParameterSamples: [10000x4 table] SimulationInfo: [1x1 struct]
绘制模拟模型响应的量级。
plotData (mpgsaResults);

绘制所接受和拒绝的样本的经验累积分配函数(ECDF)。除了公里,任何参数都没有显示出可接受和拒绝样本的ECDF的显着差异。这公里绘图显示了接受和拒绝的样品的ECDF之间的大型kolmogorov-smirnov(k-s)距离。K-S距离是两个ECDFS曲线之间的最大绝对距离。
h = plot(mpgsaresults);%调整数字大小。pos = h.Position(:);H.Position(:) = [POS(1)POS(2)POS(3)* 2 POS(4)* 2];

为了计算两种ECDF之间的K-S距离,SimBiology使用基于空假设的双面测试,即接受和拒绝的样本的两个分布相等。看KSTEST2.(统计和机器学习工具箱)有关详细信息。如果K-S距离大,则两个分布不同,这意味着样本的分类对输入参数的变化很敏感。另一方面,如果K-S距离很小,则输入参数的变化不会影响样本的分类。结果表明分类对输入参数不敏感。为了评估拒绝零假设的K-S统计数据的重要性,您可以检查p值。
酒吧(mpgsaresults)

条形图显示每个参数的两个条:一个用于K-S距离(K-S统计),另一个用于相应的p值。如果P值小于显着性级别,则拒绝NULL假设。穿过 (X)显示几乎0.几乎0的p值。您可以看到与每个参数对应的确切p值。
[mpgsaresults.parametersamples.properties.variablenames',mpgsaresults.pvalues]
ans =.4×2表var1 trapz(时间,to)<= 0.1 _____________________________ {'kel'} 0.0021877 {'ksyn'} 1 {'kdeg'} 0.99983 {'km'} 0
p值的公里和凯尔少于显着性水平(0.05),支持可接受和拒绝的样品来自不同分布的替代假设。金宝app换句话说,样品的分类对公里和凯尔但不是其他参数(克德格和ksyn.)。
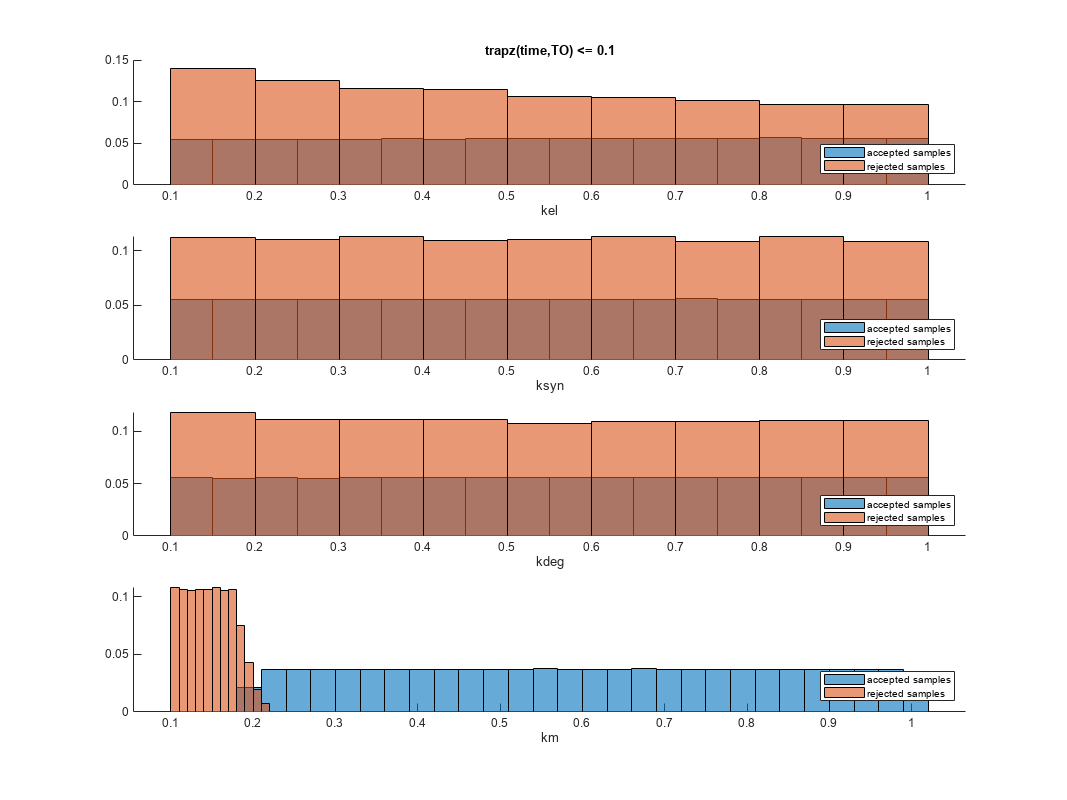
您还可以绘制接受和拒绝样本的直方图。历史图让您看到接受和拒绝样本的趋势。在本例中,的直方图公里表明,更大的样本更大公里值,而凯尔直方图表明拒绝样本较少凯尔增加。
H2 =直方图(MPGsaresults);%调整数字大小。pos = h2.Position(:);H2.Position(:) = [POS(1)POS(2)POS(3)* 2 POS(4)* 2];
恢复警告设置。
警告(warnSettings);
输入参数
输出参数
更多关于
参考
[1]Tiemann, Christian A., Joep Vanlier, Maaike H. Oosterveer, Albert K. Groen, Peter A. J. Hilbers, Natal A. W. van Riel。“参数轨迹分析以确定药物干预的治疗效果。”斯科特·马克尔编辑。PLoS计算生物学9,不。8(2013年8月1日):E1003166。https://doi.org/10.1371/journal.pcbi.1003166。
你也可以从以下列表中选择一个网站: