主要内容
保证金
分类利润率高斯内核分类模型
描述
例子
估计测试集的利润率
加载电离层数据集。这个数据集有34个预测因子和351二进制响应雷达回报,要么坏(“b”)或好(‘g’)。
负载电离层
分区数据集分为训练集和测试集。指定一个30%抵抗测试集样本。
rng (“默认”)%的再现性分区= cvpartition (Y,“坚持”,0.30);trainingInds =培训(分区);%训练集的指标testInds =测试(分区);%测试集的指标
火车一个二进制内核使用训练集分类模型。
Mdl = fitckernel (X (trainingInds:), Y (trainingInds));
估计利润率训练集和测试集的利润率。
mTrain =利润率(Mdl X (trainingInds:), Y (trainingInds));太=利润率(Mdl X (testInds:), Y (testInds));
情节两组边缘使用盒子情节。
箱线图([mTrain;太]、[0(大小(mTrain, 1), 1);(大小(mt, 1), 1)),…“标签”,{“训练集”,测试集的});标题(训练集和测试集的利润率)
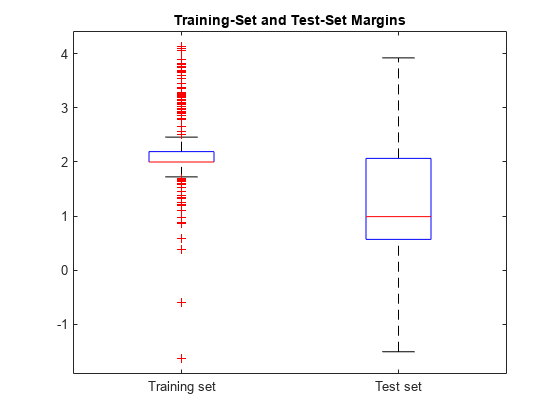
训练集的边缘分布位于高于边际分布的测试集。
特征选择使用测试集的利润率
通过比较测试集进行特征选择利润率从多个模型。仅仅根据这一标准,分类器与更大的利润率是更好的分类器。
加载电离层数据集。这个数据集有34个预测因子和351二进制响应雷达回报,要么坏(“b”)或好(‘g’)。
负载电离层
分区数据集分为训练集和测试集。指定一个15%抵抗测试集样本。
rng (“默认”)%的再现性分区= cvpartition (Y,“坚持”,0.15);trainingInds =培训(分区);%训练集的指标XTrain = X (trainingInds:);YTrain = Y (trainingInds);testInds =测试(分区);%测试集的指标XTest = X (testInds:);欧美= Y (testInds);
随机选择10%的预测变量。
p =大小(X, 2);%的预测数量idxPart = randsample (p,装天花板(0.1 * p));
火车两个二进制内核分类模型:一个使用所有的预测,以及使用了随机的10%。
Mdl = fitckernel (XTrain YTrain);PMdl = fitckernel (XTrain (:, idxPart) YTrain);
Mdl和PMdl是ClassificationKernel模型。
估计每个分类器的测试集的利润率。
fullMargins =利润率(Mdl XTest、欧美);partMargins =利润率(PMdl XTest (:, idxPart)、欧美);
情节保证金设置使用箱形图的分布。
箱线图([fullMargins partMargins),…“标签”,{“所有预测”,“10%的预测”});标题(测试集的利润的)
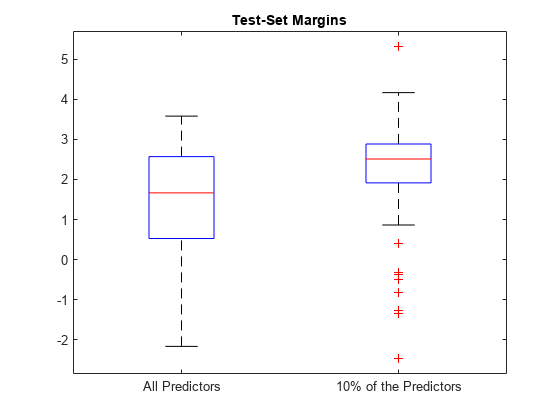
的边缘分布PMdl位于高于利润分配Mdl。因此,PMdl模型是更好的分类器。
输入参数
输出参数
更多关于
扩展功能
介绍了R2017b
