incrementallearner.
将Naive Bayes分类模型转换为增量学习者
描述
increntmentalmdl.= incrementallearner(MDL.的)increntmentalmdl.,使用传统训练的朴素贝叶斯分类模型的封锁,MDL.。因为它的财产价值反映了从中获得的知识MDL.那increntmentalmdl.可以预测标签给出新的观察,它是温暖的,这意味着跟踪其预测性能。
increntmentalmdl.= incrementallearner(MDL.那名称,价值的)increntmentalmdl.在跟踪预测性能之前。例如,'metricswarmupperiod',50,'metricswindowsize',100在跟踪性能度量之前,指定50个观测的初步增量训练期,并在更新性能度量之前指定处理100观察。
例子
将传统培训的模型转换为增量学习者
用使用训练天真的贝母模型fitcnb.,然后将其转换为增量学习者。
加载和预处理数据
加载人类活动数据集。
加载人类活动
有关数据集的详细信息,请输入描述在命令行。
火车天真贝叶斯模型
将天真的贝母分类模型适合整个数据集。
ttmdl = fitcnb(feat,actid);
TTMDL.是A.ClassificationniveBayes.代表传统训练的朴素贝叶斯分类模型的模型对象。
转换训练的模型
转换传统训练的朴素贝叶斯分类模型,以获得增量学习。
increntmentalmdl = incrementallearner(ttmdl)
increntmentalmdl = incrementallassificationnaiveBayes isWarm:1度量:[1x2表] ClassNames:scoreTransform:'none'分发Name:{1x60 Cell}分发参数:{5x60 Cell}属性,方法
increntmentalmdl.是一个incrementalclassificaiveBayes.使用Naive Bayes分类为增量学习准备的模型对象。
这
incrementallearner.函数通过将学习的条件预测器分发参数与其他信息传递给它来初始化增量学习者TTMDL.从训练数据中提取。increntmentalmdl.温暖 (温暖是1),这意味着增量学习功能可以跟踪性能指标并进行预测。
预测回应
从转换传统训练的模型创建的增量学习者可以在不进一步处理的情况下生成预测。
预测使用两种模型的所有观察分类评分(类后验概率)。
[〜,ttscores] =预测(ttmdl,feat);[〜,Ilcores] =预测(increntmentalmdl,feat);比较=常态(TTScores - ILCores)
比较= 0.
模型生成的分数之间的差异为0。
配置性能度量选项
使用训练有素的朴素贝叶斯模型来初始化增量学习者。通过指定度量预热期,准备增量学习者,在此期间updatemetricsandfit.功能仅适合模型。指定度量窗口大小为500个观察。
加载人类活动数据集。
加载人类活动
有关数据集的详细信息,请输入描述在命令行
随机将数据分成两半:前半部分用于培训一个传统上的型号,而下半部分为增量学习。
n = numel(actid);RNG(1)再现性的百分比cvp = cvpartition(n,'坚持',0.5);idxtt =培训(CVP);IDXIL =测试(CVP);数据的%上半年xtt = feat(idxtt,:);ytt = actid(idxtt);数据的%下半部分xil = feat(idxil,:);是= actid(idxil);
将天真的贝母模型适合于数据的上半年。
ttmdl = fitcnb(xtt,ytt);
将传统培训的朴素贝叶斯模型转换为Naive Bayes分类模型,用于增量学习。指定以下内容:
2000年观测的绩效度量预热期
度量窗口大小为500观察
使用分类误差和最小成本来测量模型的性能
increntmentalmdl = increntmentallerner(ttmdl,'metricswarmupperiod',2000年,'metricswindowsize'500,......'指标',[“classiferror”“合页”]);
将增量模型适合使用数据的下半部分updatemetricsandfit.功能。在每次迭代时:
一次通过处理20观察来模拟数据流。
用适合传入观察的新一个覆盖以前的增量模型。
将第二个预测器的平均值存储在第一类内 ,累积度量和窗口指标,以了解它们在增量学习期间的发展方式。
%prelocation.nil = numel(yil);numobsperchunk = 20;nchunk = ceil(nil / numobsperchunk);CE = Array2table(零(nchunk,2),'variablenames',[“累积”“窗户”]);MC = Array2table(零(nchunk,2),'variablenames',[“累积”“窗户”]);mu12 =零(nchunk,1);%增量拟合为了j = 1:nchunk ibegin = min(nil,numobsperchunk *(j-1)+ 1);IEND = min(nil,numobsperchunk * j);IDX = IBEGIN:IEND;increntmentalmdl = updatemetricsandfit(increntmentalmdl,xil(idx,:),是(idx));ce {j ,:} = increntmentalmdl.metrics {“ClassificationError”,:};mc {j ,:} = increntmentalmdl.metrics {“很小”,:};mu12(j + 1)= increntmentalmdl.distributionParameters {1,2}(1);结尾
increntmentalmdl.是一个incrementalclassificaiveBayes.模型对象在流中的所有数据上培训。在增量学习期间和模型预热后,updatemetricsandfit.检查模型对传入观察的性能,然后将模型适合该观察。
看看性能指标如何和 在训练期间演变,将它们绘制在单独的子尺上。
数字;子图(3,1,1)绘图(MU12)YLABEL('\ mu_ {12}')XLIM([0 nchunk]);Xline(increntmentalmdl.metricswarmupperiod / numobsperchunk,'r-。');子图(3,1,2)h = plot(ce.variables);XLIM([0 nchunk]);ylabel('分类错误')Xline(increntmentalmdl.metricswarmupperiod / numobsperchunk,'r-。');传奇(h,ce.properties.variablenames,'地点'那'西北')子图(3,1,3)h = plot(mc.variables);XLIM([0 nchunk]);ylabel('最小的成本')Xline(increntmentalmdl.metricswarmupperiod / numobsperchunk,'r-。');图例(h,mc.properties.variablenames,'地点'那'西北')Xlabel('迭代'的)
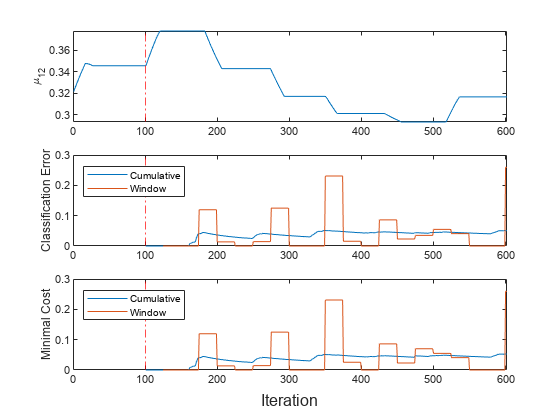
情节表明updatemetricsandfit.是否有以下操作:
合身 在所有增量学习迭代期间。
仅计算度量预热期后计算性能指标。
在每次迭代期间计算累积度量。
处理500观察(25次迭代)后计算窗口指标。
因为数据由活动排序,所以平均值和性能度量定期突然地更改。
输入参数
输出参数
更多关于
算法
也可以看看
对象
职能
您还可以从以下列表中选择一个网站:
