kfoldEdge
未用于训练的观测值的分类边缘
描述
输入参数
输出参数
例子
估计k倍交叉验证边缘
加载NLP数据集。
负载nlpdata
X是预测数据的稀疏矩阵,和Y是类标签的分类向量。数据中有两个以上的类。
模型应该识别网页中的单词计数是否来自统计学和机器学习工具箱™文档。因此,识别与统计和机器学习工具箱™文档网页相对应的标签。
Ystats = Y ==“统计数据”;
交叉验证一个二元线性分类模型,该模型可以识别文档网页中的单词计数是否来自统计学和机器学习工具箱™文档。
rng (1);%的再现性Ystats CVMdl = fitclinear (X,“CrossVal”,“上”);
CVMdl是一个ClassificationPartitionedLinear模型。默认情况下,该软件实现10倍交叉验证。属性可以改变折叠的数量“KFold”名称-值对的论点。
估计出折叠边的平均值。
e = kfoldEdge (CVMdl)
e = 8.1243
或者,您可以通过指定名称-值对来获得每折叠边“模式”,“个人”在kfoldEdge.
特征选择使用k倍的边缘
进行特征选择的一种方法是进行比较k-从多个模型折边。仅根据这个准则,具有最高边的分类器就是最好的分类器。
加载NLP数据集。预处理数据,如估计k折交叉验证边.
负载nlpdataYstats = Y ==“统计数据”;X = X ';
创建以下两个数据集:
fullX包含所有预测。partX包含随机选择的预测因子的1/2。
rng (1);%的再现性p =大小(X, 1);%预测数halfPredIdx = randsample (p,装天花板(0.5 * p));fullX = X;partX = X (halfPredIdx:);
交叉验证两个二元线性分类模型:一个使用所有预测器,另一个使用一半预测器。使用SpaRSA优化目标函数,并指出观测值对应列。
CVMdl = fitclinear (fullX Ystats,“CrossVal”,“上”,“规划求解”,“sparsa”,...“ObservationsIn”,“列”);PCVMdl = fitclinear (partX Ystats,“CrossVal”,“上”,“规划求解”,“sparsa”,...“ObservationsIn”,“列”);
CVMdl和PCVMdl是ClassificationPartitionedLinear模型。
估计k-折边为每个分类器。
fullEdge = kfoldEdge (CVMdl)
fullEdge = 16.5629
partEdge = kfoldEdge (PCVMdl)
partEdge = 13.9030
基于k-fold edges,使用所有预测器的分类器是更好的模型。
找到好的套索惩罚使用方法k倍的优势
为使用逻辑回归学习器的线性分类模型确定一个好的套索惩罚强度,比较k折边。
加载NLP数据集。预处理数据,如估计k折交叉验证边.
负载nlpdataYstats = Y ==“统计数据”;X = X ';
创建一组11个对数间隔的正则化强度 通过 .
λ= logspace (8 1 11);
交叉验证一个二元线性分类模型,使用5倍交叉验证,并使用每个正则化强度。利用SpaRSA优化目标函数。将目标函数梯度的容差降低到1 e-8.
rng (10);%的再现性Ystats CVMdl = fitclinear (X,“ObservationsIn”,“列”,“KFold”5,...“学习者”,“物流”,“规划求解”,“sparsa”,“正规化”,“套索”,...“λ”λ,“GradientTolerance”1 e-8)
CVMdl = ClassificationPartitionedLinear CrossValidatedModel: 'Linear' ResponseName: 'Y' NumObservations: 31572 KFold: 5 Partition: [1x1 cvpartition] ClassNames: [0 1] ScoreTransform: 'none'属性,方法
CVMdl是一个ClassificationPartitionedLinear模型。因为fitclinear实现5倍交叉验证,CVMdl包含5ClassificationLinear软件在每次折叠时训练的模型。
估计每个折叠的边缘和正则化强度。
eFolds = kfoldEdge (CVMdl,“模式”,“个人”)
eFolds =5×110.9958 0.9958 0.9958 0.9958 0.9924 0.9770 0.9178 0.8452 0.8127 0.8127 0.9991 0.9991 0.9991 0.9991 0.9991 0.9991 0.9991 0.9780 0.9201 0.8262 0.8128 0.8128 0.9992 0.9992 0.9992 0.9992 0.9992 0.9942 0.9781 0.9135 0.8253 0.8128 0.8128 0.8128 0.9974 0.9974 0.9974 0.9974 0.9931 0.9773 0.9121 0.8410 0.8130 0.8130 0.9976 0.9976 0.9976 0.9976 0.9976 0.99420.9782 0.9157 0.8368 0.8127 0.8127
eFolds是一个由边组成的5 × 11矩阵。中的行对应折叠,列对应正则化强度λ.您可以使用eFolds用来识别表现不佳的褶皱,也就是异常低的边缘。
估计每个正规化强度在所有折痕上的平均边。
e = kfoldEdge (CVMdl)
e =1×110.9978 0.9978 0.9978 0.9978 0.9978 0.9978 0.9936 0.9777 0.9158 0.8349 0.8128 0.8128
通过绘制每个正规化强度的5折边的平均值来确定模型的泛化程度。确定使网格上的5倍边最大化的正规化强度。
图;情节(log10(λ)log10 (e),“o”) [~, maxEIdx] = max(e);maxLambda =λ(maxEIdx);持有在情节(log10 (maxLambda) log10 (e (maxEIdx)),“罗”);ylabel (“log_{10} 5倍边缘的)包含(“log_{10}λ的)传说(“边缘”,的最大优势)举行从
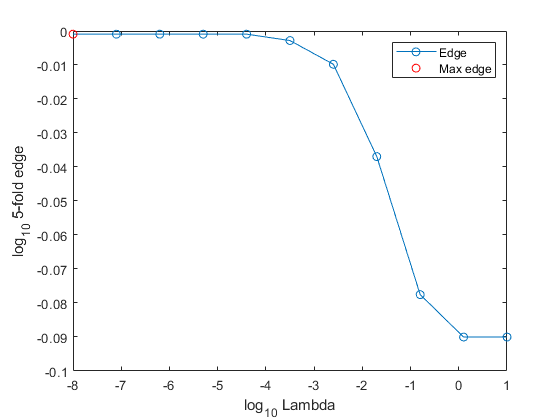
数的值λ产生类似的高边。较高的lambda值会导致预测变量的稀疏性,这是一个很好的分类器质量。
选择正规化强度发生在边缘开始下降之前。
LambdaFinal =λ(5);
使用整个数据集训练线性分类模型,并指定正则化强度LambdaFinal.
Ystats MdlFinal = fitclinear (X,“ObservationsIn”,“列”,...“学习者”,“物流”,“规划求解”,“sparsa”,“正规化”,“套索”,...“λ”, LambdaFinal);
要估计新观测值的标签,请通过MdlFinal和新的数据预测.
更多关于
你也可以从以下列表中选择一个网站:
