Kfoldmargin.
用于观察的分类边距,不用于培训
描述
输入参数
输出参数
例子
估计K.- 折叠交叉验证边距
加载NLP数据集。
加载nlpdata.
X是预测器数据的稀疏矩阵,以及y是类标签的分类矢量。数据中有两个以上的类。
该模型应识别网页中的单词计数是否来自统计信息和计算机学习工具箱文档。因此,识别与统计和机器学习工具箱文档网页对应的标签。
ystats = y =='统计';
交叉验证二进制,线性分类模型,可以识别文档网页中的单词是否来自统计和机器学习工具箱™文档。
RNG(1);重复性的%cvmdl = fitclinear(x,ystats,'横向'那'在');
cvmdl.是A.分类分类线性模型。默认情况下,软件实现10倍交叉验证。您可以使用使用的折叠数'kfold'名称值对参数。
估计交叉验证的边缘。
m = kfoldmargin(cvmdl);尺寸(m)
ans =.1×231572 1
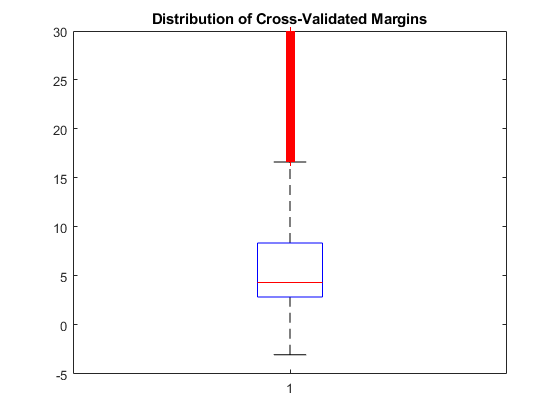
m是31572×1矢量。m(j)是折叠式边缘的平均值进行观察j。
绘图K.- 使用箱图的边距。
数字;boxplot(m);H = GCA;H.YLIM = [-5 30];标题('交叉验证的边距分布')
功能选择使用K.- 折叠利润率
执行特征选择的一种方法是比较K.- 来自多种模型的边距。仅基于此标准,具有较大边缘的分类器是更好的分类器。
加载NLP数据集。预处理数据估计k折叠交叉验证边距。
加载nlpdata.ystats = y =='统计';x = x';
创建这两个数据集:
ullx.包含所有预测器。partx.包含随机选择的1/2的预测器。
RNG(1);重复性的%p =尺寸(x,1);%预测器数量halfpredidx = randsample(p,ceil(0.5 * p));fullx = x;partx = x(halfpredidx,:);
交叉验证两个二进制,线性分类模型:一个使用所有预测器的二进制分类模型,以及使用一半的预测器。使用sparsa优化目标函数,并指示观察对应于列。
cvmdl = fitClinear(Fullx,Ystats,'横向'那'在'那'求解'那'sparsa'那......'观察'那'列');pcvmdl = fitClinear(partx,Ystats,'横向'那'在'那'求解'那'sparsa'那......'观察'那'列');
cvmdl.和PCVMDL.是分类分类线性楷模。
估计K.- 针对每个分类器的边距。绘制的分布K.- 使用盒子图来设置边距。
fullmargins = kfoldmargin(cvmdl);partmargins = kfoldmargin(pcvmdl);数字;boxplot([fullmargins partmargins],'标签'那......{'所有预测因素'那'预测器的一半'});H = GCA;H.YLIM = [-30 60];标题('交叉验证的边距分布')
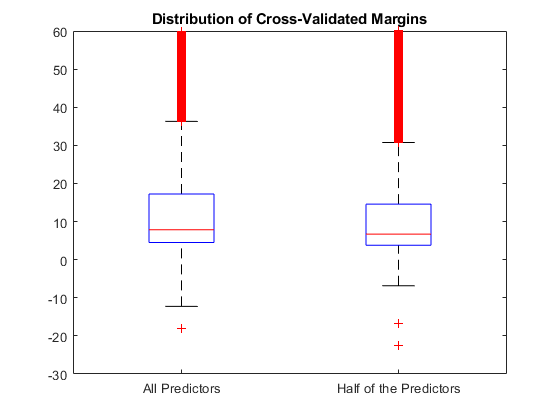
两个分类器的边缘的分布相似。
找到良好的套索惩罚K.- 折叠利润率
确定使用Logistic回归学习者的线性分类模型的良好租赁强度,比较分布K.- 折叠边距。
加载NLP数据集。预处理数据估计k折叠交叉验证边距。
加载nlpdata.ystats = y =='统计';x = x';
创建一组11个对数间隔的正则化强度 通过 。
lambda = logspace(-8,1,11);
使用5倍交叉验证交叉验证二进制,线性分类模型,并使用每个正则化强度。使用sparsa优化目标函数。降低目标函数梯度的容差1E-8。
RNG(10);重复性的%cvmdl = fitclinear(x,ystats,'观察'那'列'那'kfold',5,......'学习者'那'逻辑'那'求解'那'sparsa'那'正规化'那'套索'那......'lambda',lambda,'gradienttolerance',1E-8)
CVMdl = ClassificationPartitionedLinear CrossValidatedModel: '线性' ResponseName: 'Y' NumObservations:31572 KFold:5分区:[1x1的cvpartition]类名:[0 1] ScoreTransform: '无' 的属性,方法
cvmdl.是A.分类分类线性模型。因为FitClinear.实现5倍交叉验证,cvmdl.包含5.分类线性软件列车在每个折叠上进行模型。
估计K.- 针对每个正则化强度的边距。
m = kfoldmargin(cvmdl);尺寸(m)
ans =.1×231572 11.
m是每次观察的31572×11的交叉验证边缘矩阵。列对应于正则化强度。
绘图K.- 针对每个正则化强度的边距。由于Logistic回归分数在[0,1]中,因此边缘在[-1,1]中。重新归类利润,以帮助确定最大化网格上的边缘的正则化强度。
Figure Boxplot(10000. ^ m)ylabel('指数化测试样本边距')xlabel('lambda indices')
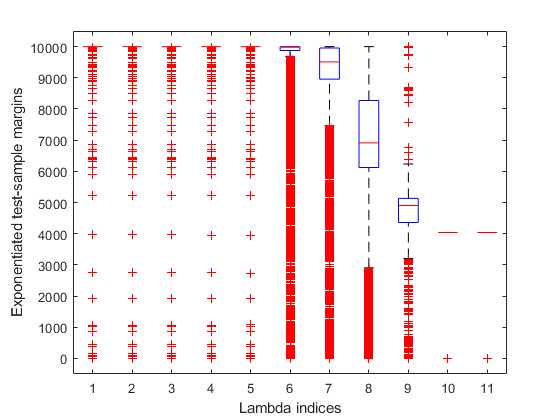
几个值lambda.屈服K.- 在10000附近压实的裕度分布。Lambda的较高值导致预测器可变稀疏性,这是一个良好的分类器质量。
选择正常的正规化强度,以前发生在“中心”之前K.- 折叠边缘分布开始减少。
Lambdafinal = lambda(5);
使用整个数据集培训线性分类模型,并指定所需的正则化强度。
mdlfinal = fitclinear(x,ystats,'观察'那'列'那......'学习者'那'逻辑'那'求解'那'sparsa'那'正规化'那'套索'那......'lambda',兰德包);
估算新观察的标签,通过mdlfinal.和新数据到预测。
更多关于
也可以看看
您还可以从以下列表中选择一个网站:
