克罗斯塔布
交叉制表
句法
描述
例子
交叉表格两个数据向量
创建两个样本数据向量,分别包含三个和四个不同的值。
x = [1 1 2 3 1];Y = [1 2 5 3 1];
交叉表格X和y。
表= Crosstab(x,y)
表=3×4.2 1 0 0 0 0 0 0 1 0 0 1 0
行in.桌子对应于三个不同的值X,列对应于四个不同的值y。
交叉制表独立数据向量
生成两个独立的向量,X1和X2,每个包含在范围内的50个离散均匀随机数1:3。
RNG.默认;重复性的%x1 = unidrnd(3,50,1);x2 = unidrnd(3,50,1);
交叉表格X1和X2。
[表,chi2,p] = crosstab(x1,x2)
表=3×31 6 7 5 5 2 11 7 6
Chi2 = 7.5449.
p = 0.1097.
回归P.的价值0.1097表示,在5%的意义水平下,克罗斯塔布未能拒绝零假设桌子每个维度都独立。
跨制表分组数据
加载样品数据,其中包含1970-1982年内的大型车型的测量。
加载CARBIG.
交叉制表四缸汽车的数据(CYL4)基于模型年(什么时候)和原籍国(org.)。
[表,CHI2,P,标签] = Crosstab(Cyl4,何时,org);
用标签确定索引位置桌子对于在数据后期在美国制造的四缸汽车数量。
标签
标签=3×3个单元阵列{'其他'} {'早期'} {'soper'} {'four'} {'four'} {'mid'} {'eurea'} {'eurea'} {0x0 double} {'lape'} {'dapan'} {'日本'}
第一列标签对应于数据CYL4,并表示该行2的桌子包含有四个气缸的汽车数据。第二列标签对应于数据什么时候,并表示列3.的桌子包含在晚期制作的汽车数据。第三列标签对应于数据org.,并表示位置1第三层桌子包含在美国制造的汽车数据。
所以,表(2,3,1)包含在晚期在美国制造的四缸汽车数量。
表(2,3,1)
ans = 38.
该数据在晚期在美国制造了38辆四缸汽车。
生成和可视化Consiency表
从数据创建竞争表,并在HeatMap图表中可视化表。
加载医院数据。
加载医院
这医院DataSet阵列包含100名医院患者的数据,包括姓氏,性别,年龄,体重,吸烟状态和收缩性和舒张压测量。
将数据集数组转换为MATLAB®表。
tbl = dataset2table(医院);
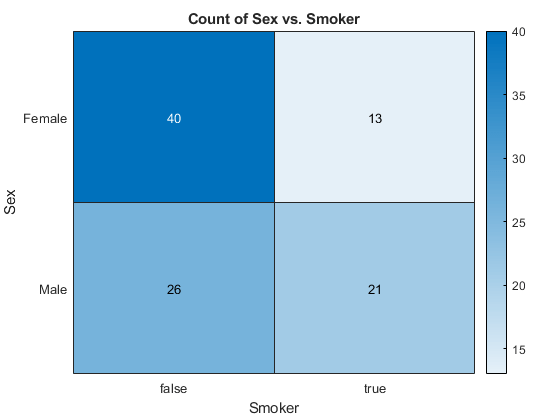
通过创建一个2×2个竞争表的吸烟者和非闻名者,确定吸烟状态是否与性别无关。
[incttbl,chi2,p,标签] = crosstab(tbl.sex,tbl.smoker)
conttbl =.2×240 13 26 21
Chi2 = 4.5083
P = 0.0337.
标签=2x2细胞{'女'} {'0'} {'male'} {'1'}
由此产生的应急表的行Conttbl.对应于患者性别,第1行包含用于女性和第2行的数据,其中包含男性数据。该列对应于患者吸烟状态,其中第1列包含不用于吸烟者数据的非闻名者和第2列的数据。返回的结果Chi2 = 4.5083是Pearson的独立性考试的Chi平方测试统计的价值。这
- 用于测试的值P = 0.0337.建议,5%的意义程度,拒绝了性别和吸烟状态是独立的。
在Heatmap中可视化差管表。绘制吸烟状态 - 轴和性别 -轴。
热线图(TBL,“吸烟者”那'性别')
输入参数
输出参数
算法
克罗斯塔布用途grp2idx.为每个不同的值分配正整数。TBL(I,J)是一个指数的计数grp2idx(x1)是一世和grp2idx(x2)是j。数值顺序grp2idx(x1)和grp2idx(x2)订单行和列TBL., 分别。在这种情况下,返回的值
TBL(I,J,...,n)是一个指数的计数grp2idx(x1)是一世那grp2idx(x2)是j那grp2idx(x3)是K., 等等。克罗斯塔布计算P.- 使用渐近的配方对大样本大小有效的公式进行Chi-Square测试统计量。对于具有不均匀的边际分布的小样本或样品,近似值不太准确。如果您的示例仅包含两个变量,每个等级都有两个级别,则可以使用渔民反而。此功能执行Fisher的确切测试,不依赖于大样本分布假设。
扩展能力
您还可以从以下列表中选择一个网站:
