主要内容
弗里德曼
弗里德曼的测试
描述
例子
用弗里德曼检验检验列效应
这个例子展示了如何使用Friedman的测试来测试双向布局中的列效果。
加载样例数据。
负载爆米花爆米花
爆米花=6×35.5000 4.5000 3.5000 5.5000 4.5000 4.5000 4.5000 4.5000 4.5000 4.5000 6.5000 4.000 3.0000 6.5000 5.0000 4.0000 7.0000 5.5000 5.0000 7.0000 5.0000 5.0000 4.5000
这个数据来自于一项关于爆米花品牌和爆米花类型的研究(Hogg 1987)。矩阵的列爆米花是品牌(美食、国家和普通)。行是popper类型(油和空气)。该研究用每个爆竹将每种品牌的爆米花爆三次。数值是每杯爆米花的产量。
用Friedman的检验来确定爆米花品牌是否影响爆米花产量。
p =弗里德曼(爆米花,3)
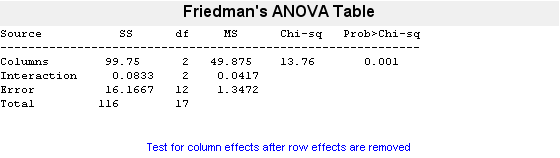
p = 0.0010
的小值p = 0.001说明爆米花品牌影响爆米花产量。
输入参数
输出参数
更多关于
参考文献
[1] Hogg, R. V.和J. Ledolter。工程数据.纽约:麦克米兰,1987年。
霍兰德,M.和D. A.沃尔夫。非参数统计方法.霍博肯,新泽西州:John Wiley & Sons, Inc., 1999。
之前介绍过的R2006a
你也可以从以下列表中选择一个网站:
