FSCMRMR.
使用最小冗余最大相关性(MRMR)算法分类的等级功能
句法
描述
idx.= fscmrmr(TBL.那responsevarname.)TBL.包含预测变量和响应变量,以及responsevarname.是响应变量的名称TBL.。函数返回idx.,其中包含通过预测的重要性排序的预测器指数。您可以使用idx.选择分类问题的重要预测因子。
例子
重视等级预测因素
加载样本数据。
加载电离层
基于重要性等待预测器。
[Idx,scores] = fscmrmr(x,y);
创建一个预测标志重要评分的条形图。
BAR(分数(IDX))XLABEL('预测的排名')ylabel('预测重点评分')
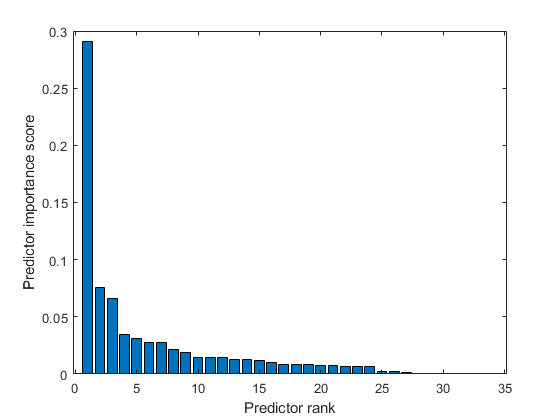
第一和第二最重要的预测器之间的分数下降很大,而第六预测器之后的液滴相对较小。重要性评分的下降代表了特征选择的置信度。因此,大幅下降意味着该软件对选择最重要的预测因子是有信心的。小滴表示预测性重要性的差异并不重要。
选择前五大最重要的预测因子。找到这些预测器的列X。
IDX(1:5)
ans =.1×55 4 1 7 24
第五列X是最重要的预测因子y。
选择功能并比较两个分类模型的准确性
通过使用找到重要的预测因子FSCMRMR.。然后比较完整分类模型(使用所有预测器)的精度和使用五个最重要的预测因子的缩小模型testckfold.。
加载人口普查1994数据集。
加载人口普查1994.
桌子AdultData.在人口普查1994.包含来自美国人口普查局的人口统计数据,以预测个人每年赚超过50,000美元。显示表的前三行。
头(AdultData,3)
ans =.3×15表年龄workClass fnlwgt教育education_num婚姻状况职业关系种族性别capital_gain capital_loss hours_per_week NATIVE_COUNTRY工资___ ________________ __________ _________ _____________ __________________ _________________ _____________ _____ ____ ____________ ____________ ______________ ______________ ______ 39国政务77516个学士13未婚ADM-文书不在位家庭白人男性2174 0 40美国联合国<= 50K 50自我emp-not-Inc 83311学士学位13结婚 - Civ-Spouse exec-Manigher丈夫白色男0 0 1 13美国<= 50K 38私人2.1565E + 05 HS-GRAD 9离婚处理人员 - 清洁剂Not-In-Family White Male 0 0 0 40美国<= 50K
输出论据FSCMRMR.仅包括函数中排名的变量。在将表传递到函数之前,将不希望在表格的末尾进行排名,包括响应变量和权重的变量,以便输出参数的顺序与表的顺序一致。
在表格中AdultData.,第三列fnlwgt.是样品的重量,以及最后一列薪水是响应变量。移动fnlwgt.到左侧薪水通过使用搬运活动功能。
AdultData = MoveVars(AdultData,'fnlwgt'那'前'那'薪水');头(AdultData,3)
ans =.3×15表年龄workClass教育education_num婚姻状况职业关系种族性别capital_gain capital_loss hours_per_week NATIVE_COUNTRY fnlwgt工资___ ________________ _________ _____________ __________________ _________________ _____________ _____ ____ ____________ ____________ ______________ ______________ __________ ______ 39国政务学士13未婚ADM-文书不在位家庭白人男性21740 40美国77516 <= 50K 50自我Emp-Not Inc学士13结婚 - Civ-Spouse Exec-Manager Justric Males 0 0 1 13美国83311 <= 50K 38私人HS-Grad 9离婚处理器 - 清洁剂Not-In-Family White Male 0 0 0 40美国2.1565E + 05 <= 50K
排名预测因子AdultData.。指定列薪水作为响应变量。
[Idx,scores] = FSCMRMR(AdultianData,'薪水'那'重量'那'fnlwgt');
创建一个预测标志重要分数的条形图。使用预测的名称X-axis刻度标签。
BAR(分数(IDX))XLABEL('预测的排名')ylabel('预测重点评分')XTicklabels(Strrep(Adjordata.properties.variablenames(Idx),'_'那'\ _'))xtickangle(45)
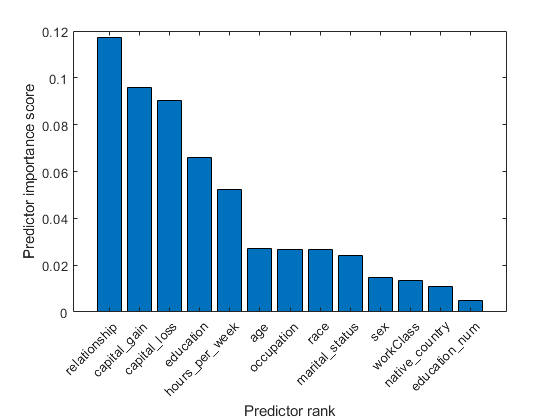
五个最重要的预测因子是关系那Capital_Loss.那资本收益那教育, 和每周几小时。
比较培训的分类树的准确性,以所有预测器培训到具有五个最重要的预测因子训练的准确性。
使用默认选项创建分类树模板。
c = templatetree;
定义表格TBL1.包含所有预测器和表格TBL2.包含五个最重要的预测因子。
TBL1 = AdultData(:,Aduclandata.properties.variablenames(IDX(1:13)));TBL2 = AdultData(:,AdultData.properties.VariaBlenames(IDX(1:5)));
将分类树模板和两个表传递给testckfold.功能。该功能通过重复的交叉验证比较了两种模型的精度。指定'替代','更大'为了测试与所有预测器的模型最多是与五个预测器的模型准确的模型。这'更大'选项可用'测试'是'5x2t'(5-by-2配对T.测试)或'10x10t'(10比10重复交叉验证T.测试)。
[h,p] = testckfold(c,c,tbl1,tbl2,amertandata.salary,'重量',AdultData.fnlwgt,'选择'那'更大'那'测试'那'5x2t')
h =逻辑0.
p = 0.9969.
H等于0和P.-Value几乎是1,表明未能拒绝零假设。与五个预测器的模型不导致与所有预测器的模型相比丢失准确性。
现在使用所选的预测器列出分类树。
mdl = fitctree(amertandata,'薪水〜关系+ capital_loss + capital_gain +教育+ herm_per_week'那......'重量',AdultData.fnlwgt)
mdl = classificationtree predictorn:{1x5 cell} racatectename:'薪资'类别预防icon:[1 2] ClassNames:[<= 50k> 50k] ScorEtransform:'无'NumObServations:32561属性,方法
输入参数
输出参数
更多关于
算法
兼容性考虑因素
参考
[1]丁,C.和H.Peng。“微阵列基因表达数据中的”最小冗余特征“。”中国生物信息学与计算生物学杂志。卷。3,第2,2,2005,第185-205页。
[2] Darbellay,G. A.和I. Vajda。“通过观察空间的自适应划分估计信息。”IEEE关于信息理论的交易。卷。45,第4,1999号,第1315-1321页。
您还可以从以下列表中选择一个网站:
