fsulaplacian.G.ydF4y2Ba
使用拉普拉斯分数无监督学习的等级功能G.ydF4y2Ba
语法G.ydF4y2Ba
描述G.ydF4y2Ba
idxG.ydF4y2Ba= fsulaplacian(G.ydF4y2BaX.G.ydF4y2Ba)G.ydF4y2BaX.G.ydF4y2Ba使用G.ydF4y2Ba拉普拉斯分数G.ydF4y2Ba.函数返回G.ydF4y2BaidxG.ydF4y2Ba,其中包含通过特征重要性订购的功能指标。你可以使用G.ydF4y2BaidxG.ydF4y2Ba为无监督学习选择重要特征。G.ydF4y2Ba
idxG.ydF4y2Ba= fsulaplacian(G.ydF4y2BaX.G.ydF4y2Ba那G.ydF4y2Ba名称,价值G.ydF4y2Ba)G.ydF4y2Ba'numneighbors',10G.ydF4y2Ba创建一个G.ydF4y2Ba相似度图G.ydF4y2Ba使用10个最近的邻居。G.ydF4y2Ba
[G.ydF4y2Ba还返回特征分数G.ydF4y2BaidxG.ydF4y2Ba那G.ydF4y2Ba分数G.ydF4y2Ba) = fsulaplacian (G.ydF4y2Ba___G.ydF4y2Ba)G.ydF4y2Ba分数G.ydF4y2Ba,使用前面语法中的任何输入参数组合。评分值越大,说明对应的特征是重要的。G.ydF4y2Ba
例子G.ydF4y2Ba
等级的重要性G.ydF4y2Ba
加载示例数据。G.ydF4y2Ba
加载G.ydF4y2Ba电离层G.ydF4y2Ba
根据重要性排列功能。G.ydF4y2Ba
[Idx,scores] = fsulaplacian(x);G.ydF4y2Ba
创建一个特征重要分数的条形图。G.ydF4y2Ba
BAR(分数(IDX))XLABEL(G.ydF4y2Ba“功能等级”G.ydF4y2Ba) ylabel (G.ydF4y2Ba“功能重要性分数”G.ydF4y2Ba)G.ydF4y2Ba
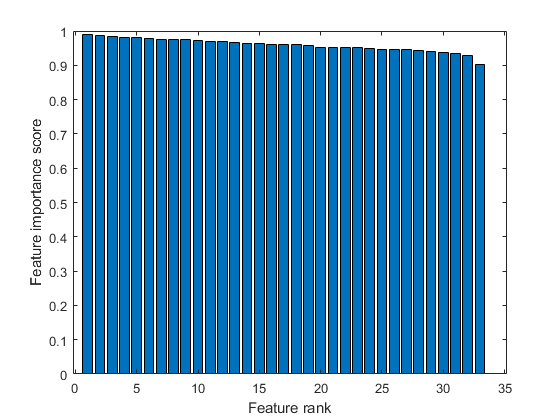
选择最重要的五个功能。找到这些功能的列G.ydF4y2BaX.G.ydF4y2Ba.G.ydF4y2Ba
idx (1:5)G.ydF4y2Ba
ans =.G.ydF4y2Ba1×5G.ydF4y2Ba15 13 13 17 21 19G.ydF4y2Ba
第15列G.ydF4y2BaX.G.ydF4y2Ba是最重要的功能。G.ydF4y2Ba
使用指定相似度矩阵排序特征G.ydF4y2Ba
从Fisher的虹膜数据集计算一个相似矩阵,并使用相似矩阵对特征进行排序。G.ydF4y2Ba
装载Fisher的Iris数据集。G.ydF4y2Ba
加载G.ydF4y2Ba渔民G.ydF4y2Ba
找到每对观察之间的距离G.ydF4y2Ba测定G.ydF4y2Ba通过使用G.ydF4y2BaPdist.G.ydF4y2Ba和G.ydF4y2Ba方形G.ydF4y2Ba默认欧几里德距离度量的功能。G.ydF4y2Ba
D = PDIST(MEA);z =方形格式(d);G.ydF4y2Ba
构建相似性矩阵并确认它是对称的。G.ydF4y2Ba
s = exp(-Z. ^ 2);不良G.ydF4y2Ba
ans =.G.ydF4y2Ba逻辑G.ydF4y2Ba1G.ydF4y2Ba
排名的功能。G.ydF4y2Ba
Idx = fsulaplacian(meas,G.ydF4y2Ba'相似'G.ydF4y2Ba,s)G.ydF4y2Ba
idx =G.ydF4y2Ba1×4G.ydF4y2Ba3 4 1 2G.ydF4y2Ba
使用相似性矩阵排名G.ydF4y2BaS.G.ydF4y2Ba通过指定等级是相同的G.ydF4y2Ba'numneighbors'G.ydF4y2Baas.G.ydF4y2Ba尺寸(量,1)G.ydF4y2Ba.G.ydF4y2Ba
idx2 = fsulaplacian(meas,G.ydF4y2Ba'numneighbors'G.ydF4y2Ba、尺寸(量,1))G.ydF4y2Ba
idx2 =G.ydF4y2Ba1×4G.ydF4y2Ba3 4 1 2G.ydF4y2Ba
输入参数G.ydF4y2Ba
输出参数G.ydF4y2Ba
更多关于G.ydF4y2Ba
算法G.ydF4y2Ba
参考资料G.ydF4y2Ba
他,X., D. Cai, P. Niyogi。"特征选择的拉普拉斯分值"G.ydF4y2Banips程序。G.ydF4y2Ba2005年。G.ydF4y2Ba
选择一个网站G.ydF4y2Ba
选择一个网站,在那里获得翻译的内容,并看到当地的活动和优惠。根据您的位置,我们建议您选择:G.ydF4y2Ba.G.ydF4y2Ba
选择G.ydF4y2Ba网站G.ydF4y2Ba您还可以从以下列表中选择一个网站:G.ydF4y2Ba
美洲G.ydF4y2Ba
- América拉丁G.ydF4y2Ba(西班牙语)G.ydF4y2Ba
- 加拿大G.ydF4y2Ba(英文)G.ydF4y2Ba
- 美国G.ydF4y2Ba(英文)G.ydF4y2Ba
欧洲G.ydF4y2Ba
- 比利时G.ydF4y2Ba(英文)G.ydF4y2Ba
- 丹麦G.ydF4y2Ba(英文)G.ydF4y2Ba
- 德国G.ydF4y2Ba(德语)G.ydF4y2Ba
- España.G.ydF4y2Ba(西班牙语)G.ydF4y2Ba
- 芬兰G.ydF4y2Ba(英文)G.ydF4y2Ba
- 法国G.ydF4y2Ba(Français)G.ydF4y2Ba
- 爱尔兰G.ydF4y2Ba(英文)G.ydF4y2Ba
- 意大利G.ydF4y2Ba(意大利语)G.ydF4y2Ba
- 卢森堡G.ydF4y2Ba(英文)G.ydF4y2Ba
- 荷兰G.ydF4y2Ba(英文)G.ydF4y2Ba
- 挪威G.ydF4y2Ba(英文)G.ydF4y2Ba
- Österreich.G.ydF4y2Ba(德语)G.ydF4y2Ba
- 葡萄牙G.ydF4y2Ba(英文)G.ydF4y2Ba
- 瑞典G.ydF4y2Ba(英文)G.ydF4y2Ba
- 瑞士G.ydF4y2Ba
- 英国G.ydF4y2Ba(英文)G.ydF4y2Ba
亚太地区G.ydF4y2Ba
- 澳大利亚G.ydF4y2Ba(英文)G.ydF4y2Ba
- 印度G.ydF4y2Ba(英文)G.ydF4y2Ba
- 新西兰G.ydF4y2Ba(英文)G.ydF4y2Ba
- 中国G.ydF4y2Ba
- 日本G.ydF4y2Ba(日本语)G.ydF4y2Ba
- 한국G.ydF4y2Ba(한국어)G.ydF4y2Ba
