适合核心分布使用ksdity
此示例显示如何使用示例使用样本数据生成内核概率密度估计值ksdity功能。
步骤1.加载样本数据。
加载样本数据。
加载Carsmall.;
此数据包含每加仑数英里(MPG.)针对不同品牌和汽车型号的测量,由原产国分组(起源),模型年(年)和其他车辆特征。
步骤2.生成内核概率密度估计。
用ksdity生成核概率密度估计,每加仑数英里(MPG.) 数据。
[f,xi] = ksdenty(mpg);
默认,ksdity除非您另有指定,否则使用正常的内核平滑功能并选择最佳带宽以估计正常密度。
步骤3.绘制内核概率密度估计。
绘制内核概率密度估计,以可视化MPG.分配。
情节(xi,f,'行宽',2)标题('每加仑数英里')xlabel('mpg')
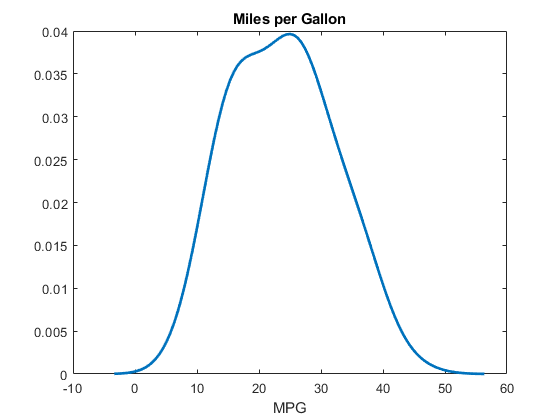
该曲线显示了核心分布的PDF适合的MPG.所有汽车的数据。分布流畅且相当对称,尽管它略有偏向右尾。
也可以看看
相关话题
您还可以从以下列表中选择一个网站:
