内核分配
概述
核分布是随机变量的概率密度函数(pdf)的非参数表示。当参数分布不能正确地描述数据时,或者当您想避免对数据的分布进行假设时,您可以使用内核分布。一个核分布是由一个平滑函数和一个带宽值定义的,它们控制得到的密度曲线的平滑性。
内核密度估计
核密度估计量是随机变量的估计pdf。对于任何实际值x,内核密度估计器的公式由
在哪里x1,x2、…xn是来自未知分布的随机样本,n为样本容量, 是内核平滑功能,和h是带宽。
内核平滑功能
内核平滑函数定义用于生成PDF的曲线的形状。类似于直方图,内核分发构建了使用示例数据表示概率分布的功能。但与直方图不同,该直方图将值放入离散箱中,内核分布总和为每个数据值的组件平滑功能和产生平滑,连续概率曲线。以下绘图显示了从相同的样本数据产生的直方图和内核分布的视觉比较。
直方图通过建立箱子并将每个数据值放入适当的箱子来表示概率分布。
SixMPG = [13; 15; 23; 29; 32; 34];图直方图(SixMPG)
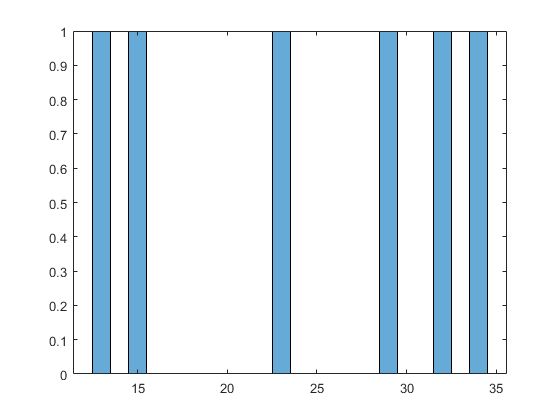
由于这种bin计数方法,直方图产生一个离散的概率密度函数。这可能不适合某些应用程序,例如从拟合分布生成随机数。
或者,通过为每个数据值创建单独的概率密度曲线,然后求解平滑曲线来构建PDF。该方法为数据集创建一个平滑,连续的概率密度函数。
figure pdSix = fitdist(SixMPG,“内核”,'带宽'4);x = 0: .1:45;ySix = pdf (pdSix x);情节(x, ySix,'k-',“线宽”2)%绘制每个单独的PDF并将其出现在绘图上持有上为pd = makedist(“正常”,'亩'SixMPG(我),“σ”4);y = pdf(pd,x);y = y / 6;绘图(x,y,'B:')结束持有关闭

较小的虚线曲线是样本数据中每个值的概率分布,通过缩放来拟合图。较大的实心曲线为整体的核分布SixMPG数据。核平滑函数是指那些较小的分量曲线的形状,在这个例子中它们是正态分布的。
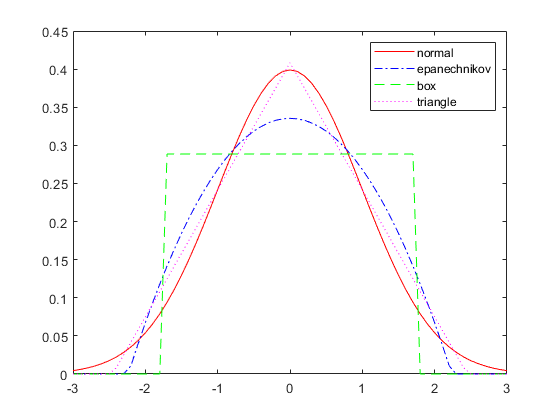
您可以为内核平滑功能选择几个选项之一。此图显示了可用平滑功能的形状。
情节设置规范
hname = {“正常”'Epanechnikov'“盒子”“三角形”};颜色= {“r”“b”‘g’'M'};线= {“- - -”,“-”。,“——”,':'};%生成每个内核平滑功能和图的样本数据= [0];数字为pd = fitdist(data,'核心',“内核”,hname {j});x = -3:.1:3;y = pdf(pd,x);绘图(x,y,'颜色'颜色{j},'linestyle', {j}行)上结束传奇(hname)关闭
要了解不同核平滑函数对pdf估计结果形状的影响,请比较里程数据(英里/加仑)carbig.mat使用每个可用的内核函数。
负载carbig%设置绘图规格hname = {“正常”'Epanechnikov'“盒子”“三角形”};颜色= {“r”“b”‘g’'M'};线= {“- - -”,“-”。,“——”,':'};%生成内核分布对象并绘图数字为pd = fitdist(MPG,'核心',“内核”,hname {j});x = -10:1:60;y = pdf(pd,x);绘图(x,y,'颜色'颜色{j},'linestyle', {j}行)上结束传奇(hname)关闭

每个密度曲线使用相同的输入数据,但应用不同的核平滑函数来生成pdf。密度估计数大致相当,但每条曲线的形状略有不同。例如,盒核产生的密度曲线不如其他的平滑。
带宽
带宽值的选择控制了所得概率密度曲线的平滑度。此图显示了相同的密度估计英里/加仑数据,使用具有三种不同带宽的普通内核平滑功能。
创建内核分发对象
pd1 = fitdist(mpg,'核心');pd2 = fitdist(mpg,'核心','带宽'1);pd3 = fitdist(英里/加仑,'核心','带宽'5);%计算每个PDFx = -10:1:60;y1 = pdf(pd1,x);y2 = pdf(pd2,x);y3 = pdf(pd3,x);绘制每个pdf情节(x, y₁,'颜色',“r”,'linestyle',“- - -”抱紧上情节(x, y2,'颜色','K','linestyle',':')情节(x, y3,'颜色',“b”,'linestyle',“——”)传奇({“带宽=违约”,“带宽= 1”,“带宽= 5”})举行关闭

默认带宽,从理论上是最佳的,用于估算正态分布的密度[1],产生一条相当平滑的曲线。指定一个较小的带宽会产生一个非常粗糙的曲线,但揭示了数据中可能有两个主要的峰值。指定一个更大的带宽会产生一个几乎与内核函数相同的曲线,它是如此平滑,以至于掩盖了数据的潜在重要特征。
参考资料
[1] Bowman,A. W.和A. Azzalini。应用平滑技术进行数据分析。纽约:牛津大学新闻公司,1997年。
另请参阅
相关话题
您还可以从以下列表中选择一个网站:
