ksdensity
核平滑函数估计单变量和双变量数据
句法
描述
例子
估计密度
生成从两个正态分布的混合物的样本数据集。
RNG('默认')%用于重现X = [randn(30,1);5 + randn(30,1)];
画出估算的浓度。
[f, xi] = ksdensity (x);图情节(XI中,f);

密度估计显示了样品的双峰性。
估计密度与边界校正
从半正态分布中生成非负样本数据集。
RNG('默认')%用于重现PD = makedist('HalfNormal',“亩”,0,“西格玛”,1);X =随机(PD,100,1);
概率密度函数与两个不同的边界校正方法,对数变换和反射估算,通过使用“BoundaryCorrection”名称 - 值对的参数。
PTS = linspace(0,5,1000);%点来评估估计[F1,XI1] = ksdensity(X,PTS,'金宝app支持',“积极”);[F2,XI2] = ksdensity(X,PTS,'金宝app支持',“积极”,“BoundaryCorrection”,'反射');
画出两个估计的PDF文件。
情节(XI1,F1,XI2,F2)LGD =图例(“日志”,'反射');标题(LGD,“边界校正方法”) xl = xlim;xlim ([-0.25 xl xl (1) (2)))

ksdensity在指定正支持或有界支持时使用边界校正方法。金宝app默认的边界修正方法是log变换。当ksdensity转换背部支撑,介绍了金宝app1 / x长期在内核密度估计。因此,估计有接近峰值x = 0的。在另一方面,反射方法不会导致的边界附近不希望的峰值。
在指定的值估计累积分布函数
加载样本数据。
加载医院
计算并绘制估计CDF在指定的一组值进行评价。
分= (min (hospital.Weight): 2:马克斯(hospital.Weight));图()ecdf (hospital.Weight)上并[f,XI,BW] = ksdensity(hospital.Weight,PTS,'金宝app支持',“积极”,...'功能','CDF');图(十一,F,'-G','行宽',2)图例(“经验CDF”,'内核-BW:默认',“位置”,'西北')xlabel(“患者体重”)ylabel(“估计CDF”)

ksdensity似乎顺利累积分布函数估计太多。具有较小带宽的估计可能会产生更紧密的估计与经验累积分布函数。
返回平滑窗口的带宽。
BW
BW = 0.1070
绘制使用较小的带宽累积分布函数估计。
并[f,Ⅺ] = ksdensity(hospital.Weight,PTS,'金宝app支持',“积极”,...'功能','CDF','带宽',0.05);图(十一,F,“——r”,'行宽',2)图例(“经验CDF”,'内核-BW:默认',“kernel-bw: 0.05”,...“位置”,'西北')保持离
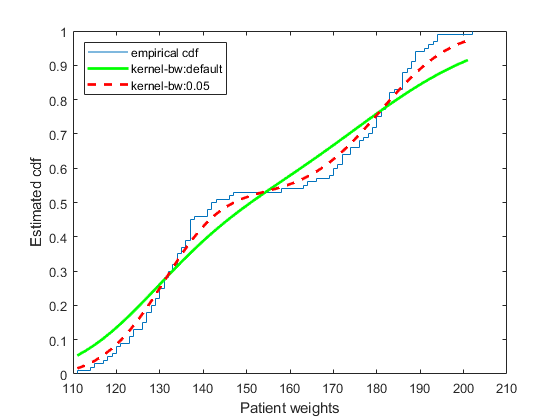
该ksdensity估计与较小的带宽经验累积分布函数更好匹配。
剧情估计累积密度函数点的给定数量
加载样本数据。
加载医院
绘制所估计的CDF在50点等距间隔的点进行评价。
图()ksdensity (hospital.Weight,'金宝app支持',“积极”,'功能','CDF',...“NumPoints”,50)xlabel(“患者体重”)ylabel(“估计CDF”)

估计幸存者和删失数据累积风险
从均值为3的指数分布中生成样本数据。
RNG('默认')%用于重现随机(x ='EXP',3100,(1);
创建一个表示审查的逻辑向量。在这里,寿命超过10年的观测结果被审查。
T = 10;经社=(X> T);
计算并绘制估计的密度函数。
图ksdensity (x,'金宝app支持',“积极”,“截尾”岑);

计算并绘制幸存者功能。
图ksdensity (x,'金宝app支持',“积极”,“截尾”岑,...'功能','幸存者');
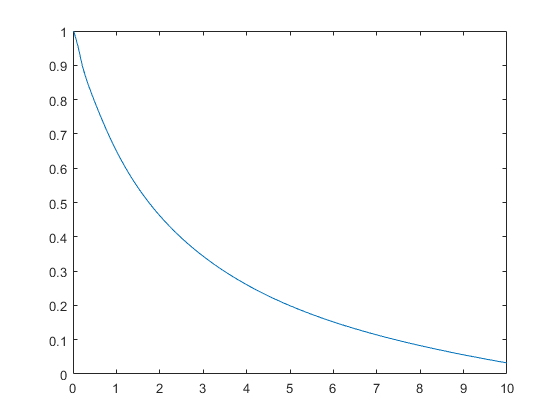
计算并绘制累积危险函数。
图ksdensity (x,'金宝app支持',“积极”,“截尾”岑,...'功能','cumhazard');

对于指定的概率值估计逆累积分布函数
生成两个正态分布的混合物,并绘制在指定的一组概率值的所估计的逆累积分布函数。
RNG('默认')%用于重现X = [randn(30,1);5 + randn(30,1)];PI = linspace(0.01,.99,99);图ksdensity(X,P1,'功能','ICDF');

平滑窗口的反向带宽
生成两个正态分布的混合物。
RNG('默认')%用于重现X = [randn(30,1);5 + randn(30,1)];
返回平滑窗口的带宽的概率密度估计。
并[f,XI,BW] = ksdensity(X);BW
BW = 1.5141
默认带宽是最佳的正常密度。
画出估算的浓度。
图情节(XI中,f);xlabel(“十一”)ylabel('F')保持上

使用增加的带宽值绘制密度。
并[f,Ⅺ] = ksdensity(X,'带宽',1.8);图(十一,F,“——r”,'行宽'1.5)

更高的带宽进一步平滑了密度估计,这可能掩盖了分布的一些特性。
现在,绘制使用减少的带宽值的密度。
并[f,Ⅺ] = ksdensity(X,'带宽',0.8);图(十一,F,'-.k','行宽'传说,1.5)(“bw =违约”,'BW = 1.8','BW = 0.8')保持离

较小的带宽平滑的密度估计值更小,这夸大了样品的一些特性。
二元数据的叠加核密度估计
创建在该评估密度点的一个两列向量。
gridx1 = -0.25:0.05:1.25;gridx2 = 0:0.1:15;[X1,X2] = meshgrid(gridx1,gridx2);X1 = X1(:);X2 = X2(:);XI = [X1 X2];
产生从二元正态分布的混合物包含随机数的30×2矩阵。
RNG('默认')%用于重现x = [0+ 5*rand(20,1) 5+2.5*rand(20,1);综合成绩+ .25 *兰德(10,1)8.75 + 1.25 *兰德(10,1)];
绘制样本数据的估计密度。
图ksdensity(X,XI);

输入参数
输出参数
更多关于
参考
[1]鲍曼,A. W.,和A. Azzalini。应用平滑技术进行数据分析。纽约:牛津大学出版公司,1997。
[2]山,P.D。“分布函数的核估计”。理论与方法 - 统计通讯。第14卷,第。3,1985年,第605-620。
[3]琼斯,M. C.“核密度估计的简单边界校正”。统计与计算。卷。3,第3期,1993,第135-146。
[4]西尔弗曼,B.W。密度估计统计和数据分析。查普曼和霍尔/ CRC,1986。
扩展功能
R2006a前推出
您还可以选择从下面的列表中的网站:
