glmfit
拟合广义线性回归模型
语法
描述
例子
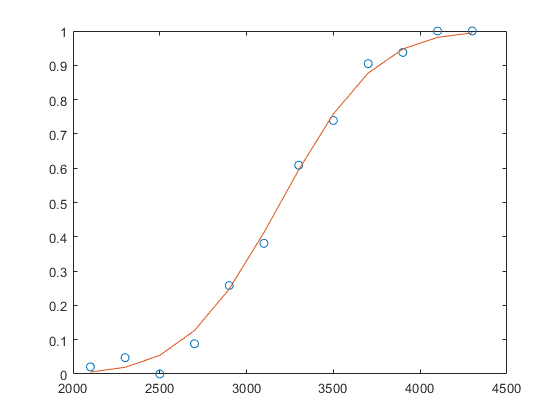
拟合广义线性模型与Probit链接
拟合广义线性回归模型,并使用拟合模型计算预测器数据的预测(估计)值。
创建一个示例数据集。
X = [2100 2300 2500 2700 2900 3100 ....3300 3500 3700 3900 4100 4300]';N = [48 42 31 34 31 21 23 23 21 16 17 21]';Y = [1 2 0 3 8 8 14 17 19 15 17 21]';
x包含预测变量值。每一个y值是在相应的试验次数中成功的次数n.
拟合probit回归模型y在x.
B = glmfit(x,[y n],“二”,“链接”,“probit”);
计算估计的成功次数。
Yfit = glmval(b,x,“probit”,“大小”n);
将观察到的成功率和估计的成功率与x值。
情节(x, y / n,“o”, x, yfit. / n,“- - -”)
用自定义链接函数拟合广义线性模型
定义一个自定义链接函数,并使用它来拟合广义线性回归模型。
加载样例数据。
负载fisheriris
列向量物种含有三种不同种类的鸢尾花:鸢尾花、鸢尾花和维珍花。矩阵量包含四种类型的测量花,萼片和花瓣的长度和宽度厘米。
定义预测变量和响应变量。
X = meas(51:end,:);Y = strcmp(“多色的”、物种(51:结束));
为logit链接函数定义一个自定义链接函数。创建三个函数句柄,分别定义link函数、link函数的导数和逆link函数。将它们存储在单元格数组中。
Link = @(mu) log(mu./(1-mu));Derlink = @(mu) 1./(mu.*(1-mu));inlink = @(resp) 1./(1+exp(-resp));F = {link,derlink,invlink};
拟合逻辑回归模型glmfit使用自定义链接函数。
b = glmfit(X,y,“二”,“链接”F)
b =5×142.6378 2.4652 6.6809 -9.4294 -18.2861
拟合一个广义线性模型使用内置分对数链接函数,并比较结果。
b = glmfit(X,y,“二”,“链接”,分对数的)
b =5×142.6378 2.4652 6.6809 -9.4294 -18.2861
执行偏差测试
拟合一个广义线性回归模型,其中包含每个预测器的截距和线性项。执行偏差检验,以确定模型是否比常数模型拟合得更好。
使用带有两个基本预测因子的泊松随机数生成样本数据X (: 1)而且X (:, 2).
rng (“默认”)%用于再现性Rndvars = randn(100,2);X = [2 + rndvars(:,1),rndvars(:,2)];= exp(1 + X*[1;2]);Y = poissrnd(mu);
拟合一个广义线性回归模型,其中包含每个预测器的截距和线性项。
[b,dev] = glmfit(X,y,“泊松”);
第二个输出参数dev是一个异常合身的。
拟合只包含截距的广义线性回归模型。将预测变量指定为1列,并指定“不变”作为“关闭”这glmfit在模型中不包括常数项。
[~,dev_noconstant] = glmfit(ones(100,1),y,“泊松”,“不变”,“关闭”);
计算两者的差值dev_constant而且dev.
D = dev_noconstant - dev
D = 2.9533e+05
D有2个自由度的卡方分布。自由度等于所对应的模型中估计参数数目的差值dev和常数模型中估计参数的数量。找到p-value表示偏差测试。
p = 1 - chi2cdf(D,2)
P = 0
小p-value表示模型与常数有显著差异。
或者,您可以创建泊松数据的广义线性回归模型fitglm函数。模型显示包括统计数据(Chi^2统计与常数模型),p价值。
mdl = fitglm(X,y,'y ~ x1 + x2',“分布”,“泊松”)
mdl =广义线性回归模型:log(y) ~ 1 + x1 + x2分布=泊松估计系数:估计SE tStat pValue ________ _________ ______ ______(截距)1.0405 0.022122 47.034 0 x1 0.9968 0.003362 296.49 0 x2 1.987 0.0063433 313.24 0 100个观测值,97个误差自由度离散度:1 Chi^2统计量vs常数模型:2.95e+05, p值= 0
你也可以使用devianceTest函数与拟合的模型对象。
devianceTest (mdl)
ans =2×4表异常DFE chi2Stat pValue __________ ___ __________ ______ 日志(y) ~ 1 2.9544 e + 05 99日志(y) ~ 1 x1 + x2 + 107.4 97 2.9533 e + 05年0
输入参数
输出参数
更多关于
选择功能
glmfit当您只是需要函数的输出参数,或者当您希望在循环中多次重复拟合模型时,此参数非常有用。如果您需要进一步研究拟合模型,请创建一个广义线性回归模型对象GeneralizedLinearModel通过使用fitglm或stepwiseglm.一个GeneralizedLinearModel对象提供的特性比glmfit.
使用的属性
GeneralizedLinearModel研究拟合的模型对象属性包括有关系数估计、汇总统计信息、拟合方法和输入数据的信息。的对象函数
GeneralizedLinearModel预测反应,并修改,评估和可视化广义线性回归模型。的输出中可以找到相关信息
glmfit的属性和对象函数GeneralizedLinearModel.的输出 glmfit等值 GeneralizedLinearModelb看到 估计的列系数财产。dev看到 异常财产。统计数据在命令窗口中查看模型显示。您可以在模型属性(
CoefficientCovariance,系数,分散,DispersionEstimated,残差).中的色散参数
统计数据.年代glmfit尺度因子是系数的标准误差,而色散参数是分散广义线性模型的性质是响应方差的比例因子。因此,stats.s是根号吗分散价值。
参考文献
[1]多布森a.j.广义线性模型导论.纽约:查普曼和霍尔,1990年。
[2]麦cullagh P.和J. A. Nelder。广义线性模型.纽约:查普曼和霍尔,1990年。
[3]科莱特D。二进制数据建模.纽约:查普曼和霍尔,2002年。
扩展功能
您也可以从以下列表中选择一个网站:
