损失
批数据增量学习的线性模型损失
描述
损失返回线性回归的配置增量学习模型的回归或分类损失(incrementalRegressionLinear对象)或线性二进制分类(incrementalClassificationLinear对象)。
要测量数据流上的模型性能并将结果存储在输出模型中,调用updateMetrics或updateMetricsAndFit.
例子
在增量学习过程中度量模型性能
增量模型在流数据上的性能可以用三种方法来衡量:
累积指标衡量自增量学习开始以来的表现。
窗口指标测量指定的观察窗口上的性能。每次模型处理指定的窗口时都会更新指标。
的
损失函数仅度量指定一批数据的性能。
加载人工活动数据集。随机洗牌数据。
负载人类活动n = numel(actid);RNG(1);%的再现性idx = randsample (n, n);X =壮举(idx:);Y = actid (idx);
关于数据集的详细信息,请输入描述在命令行。
回答可以是五种类型之一:坐、站、走、跑或跳舞。通过识别被试是否在移动(actid> 2)。
Y = Y > 2;
建立二元分类的增量线性支持向量机模型。配置它损失通过指定类名、先验类分布(均匀)、任意系数和偏差值。指定1000个观察值的指标窗口大小。
p =大小(X, 2);β= randn (p, 1);偏见= randn (1);Mdl = incrementalClassificationLinear ('beta',β,“偏见”偏见,......“类名”,独特(Y),“之前”,'制服','metricswindowsize', 1000);
Mdl是一个incrementalClassificationLinear模型。它的所有属性都是只读的。不需要指定任意值,您可以采取以下任一操作来配置模型:
训练一个支持向量机模型使用
fitcsvm或FitClinear.在数据的子集上(如果可用),然后将模型转换为增量学习者使用incrementallearner..逐步适应
Mdl通过使用来数据适合.
模拟数据流,并在50个观察的每个传入块上执行以下操作:
称呼
updateMetrics测量观察窗口内的累积性能和性能。用新的一个覆盖以前的增量模型来跟踪性能指标。称呼
损失来测量模型在传入块上的性能。称呼
适合使模型与传入的数据块相匹配。用一个适合传入观测的新模型覆盖先前的增量模型。存储所有性能指标,以查看它们在增量学习过程中是如何发展的。
%预先配置numObsPerChunk = 50;nchunk =地板(n / numObsPerChunk);ce = array2table (0 (nchunk, 3),'variablenames',[“累积”“窗口”“损失”]);%增量学习为n = 1:nchunk ibegin = min(n,numObsPerChunk*(j-1) + 1);iend = min (n, numObsPerChunk * j);idx = ibegin: iend;Mdl = updateMetrics (Mdl X (idx:), Y (idx));ce {j [“累积”“窗口”]} = Mdl。指标{“ClassificationError”,:};ce {j,“损失”} =损失(Mdl X (idx:), Y (idx));Mdl =适合(Mdl X (idx:), Y (idx));结束
Mdl是一个incrementalClassificationLinear模型对象在流中的所有数据上培训。在增量学习期间和模型预热后,updateMetrics检查模型的性能对传入的观察,然后适合函数使模型符合这个观察。损失是不可知的指标预热期,因此它度量所有迭代的分类错误。
要了解培训期间演化的性能指标如何,请绘制它们。
图;情节(ce.Variables);xlim ([0 nchunk]);ylim (0.05 [0]) ylabel (分类错误的)xline(mdl.metricswarmupperiod / numobsperchunk,r -。);传奇(ce.Properties.VariableNames)包含(“迭代”)

在指标预热期间(红线左边的区域),黄线表示每个传入数据块上的分类错误。在指标热身期之后,Mdl跟踪累积指标和窗口指标。累积损失和批损失收敛为适合函数适合传入数据的增量模型。
计算传入数据块的自定义损失
拟合一个增量学习模型对流数据回归,并计算传入数据批的平均绝对偏差(MAD)。
加载机器人手臂数据集。获得样本量n以及预测变量的数量p.
负载robotarmn =元素个数(ytrain);p =大小(Xtrain 2);
关于数据集的详细信息,请输入描述在命令行。
为回归创建一个增量线性模型。模型配置如下:
指定度量预热时间为1000个观察。
指定一个指标窗口大小为500个观察值。
跟踪平均绝对偏差(MAD)以测量模型的性能。创建一个匿名函数,测量每个新观察的绝对错误。创建包含名称的结构数组
MeanAbsoluteError及其相应的功能。配置模型以通过指定所有回归系数和偏差为0来预测响应。
Maefcn = @(z,zfit,w)(abs(z - zfit));maemetric = struct(“MeanAbsoluteError”, maefcn);Mdl = incrementalRegressionLinear (“MetricsWarmupPeriod”, 1000,'metricswindowsize'500,......“指标”,raemetric,'beta',零(p,1),“偏见”0,'估计period', 0)
Mdl = incrementalRegressionLinear IsWarm: 0 Metrics: [2x2 table] ResponseTransform: 'none' Beta: [32x1 double] Bias: 0 Learner: 'svm'属性,方法
Mdl是一个incrementalRegressionLinear为增量学习配置的模型对象。
执行增量学习。在每一次迭代:
通过处理50个观察数据块来模拟数据流。
称呼
updateMetrics计算传入数据块的累积和窗口指标。用一个适合覆盖先前指标的新模型覆盖先前的增量模型。称呼
损失来计算传入数据块的MAD。然而累积和窗口度量要求自定义损失返回每个观测的损失,损失需要整块的损失。计算绝对偏差的平均值。称呼
适合将增量模型拟合到传入数据块。存储累积、窗口和块指标,以查看它们在增量学习期间是如何发展的。
%预先配置numObsPerChunk = 50;nchunk =地板(n / numObsPerChunk);美= array2table (0 (nchunk, 3),'variablenames',[“累积”“窗口”“块”]);%增量式拟合为n = 1:nchunk ibegin = min(n,numObsPerChunk*(j-1) + 1);iend = min (n, numObsPerChunk * j);idx = ibegin: iend;Mdl = updateMetrics (Mdl Xtrain (idx:), ytrain (idx));美{j, 1:2} = Mdl。指标{“MeanAbsoluteError”,:};美{j 3} =损失(Mdl, Xtrain (idx:), ytrain (idx),'lockfun'@ (x, y, w)意味着(maefcn (x, y, w)));Mdl =适合(Mdl Xtrain (idx:), ytrain (idx));结束
IncrementalMdl是一个incrementalRegressionLinear模型对象在流中的所有数据上培训。在增量学习期间和模型预热后,updateMetrics检查模型对传入观察的性能,以及适合函数使模型符合这个观察。
绘制性能指标,看看它们在增量学习过程中是如何发展的。
图;h =情节(mae.Variables);ylabel (的平均绝对偏差)xline(mdl.metricswarmupperiod / numobsperchunk,r -。);包含(“迭代”传奇(h, mae.Properties.VariableNames)

这个情节暗示了以下内容:
updateMetrics仅在指标预热时间后计算性能指标。updateMetrics在每次迭代期间计算累积度量。updateMetrics在处理500个观测值后计算窗口度量值因为
Mdl被配置为从增量学习开始就预测观察结果,损失可以计算每个传入数据块的MAD。
输入参数
输出参数
更多关于
分类损失
分类损失功能测量分类模型的预测不准确性。当你在许多模型中比较同一类型的损失时,损失越低表明预测模型越好。
考虑以下场景。
l为加权平均分类损失。
n为样本量。
对于二进制分类:
yj是观察到的类标签。软件将其代码为-1或1,表示负或正类(或第一个或第二类)
一会分别属性)。f(Xj)为观察(行)的阳性分类评分j预测的数据X.
米j=yjf(Xj)为分类观察的分类评分j对应的类yj.积极的价值观米j表明正确的分类,对平均损失贡献不大。负的米j表示不正确的分类,并对平均损失显着贡献。
观测权重j是wj.
给定此场景,下表描述了支持的损失函数,可以使用金宝app'lockfun'名称-值对的论点。
| 损失函数 | 的价值LossFun |
方程 |
|---|---|---|
| 二项式偏差 | “binodeviance” |
|
| 指数损失 | “指数” |
|
| 十进制误分类率 | “classiferror” |
为得分最大的类对应的类标签。我{·}是指示函数。 |
| 铰链的损失 | “枢纽” |
|
| 分对数损失 | “分对数” |
|
| 二次损失 | “二次” |
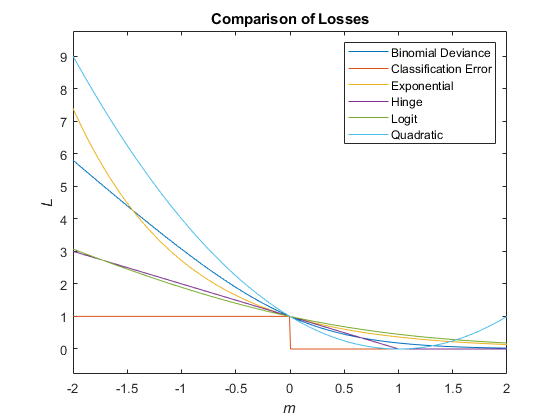
这个数字比较了分数上的损失函数米一个观察。一些函数被归一化通过点(0,1)。
算法
扩展能力
另请参阅
对象
功能
你也可以从以下列表中选择一个网站:
